The document discusses various topics related to distributed systems including:
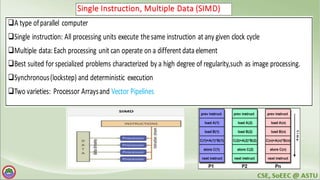
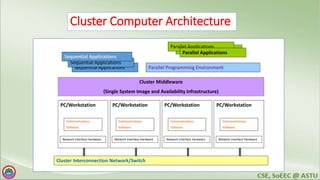
1. An agenda covering evolution of computational technology, parallel computing, cluster computing, grid computing, utility computing, virtualization, service-oriented architecture, cloud computing, and internet of things.
2. Definitions of distributed systems and reasons why typical definitions are unsatisfactory.
3. A proposed working definition of distributed systems.
4. Computing paradigms including centralized, parallel, and distributed computing.
5. Challenges of distributed systems such as failure recovery, scalability, asynchrony, and security.



![4
Definitions of Distributed Systems
A distributed system is a collection of independent computers that appear to
the users of the system as a single computer.
[Andrew Tanenbaum]
A distributed system is several computers doing something together. Thus, a
distributed system has three primary characteristics: multiple computers,
interconnections, and shared state.
[Michael Schroeder]](https://image.slidesharecdn.com/adsu1vf-240314083128-13ad1fb8/85/distributed-system-lab-materials-about-ad-4-320.jpg)