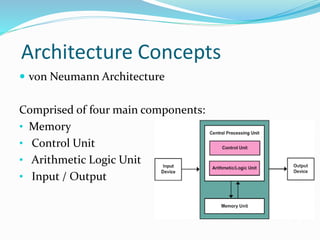
Parallel computing allows multiple instructions to be executed simultaneously, significantly saving time and enabling the solution of larger problems by leveraging the resources of multiple computers. Various architectural concepts and classifications demonstrate how different parallel computer systems operate, including shared memory and distributed memory structures. India has made notable contributions to parallel computing with significant projects like PARAM and Anupam, advancing the nation's capabilities in high-performance computing.