Download as PDF, PPTX








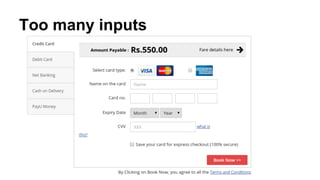


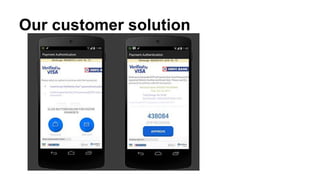



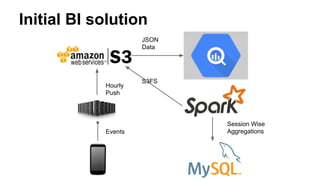




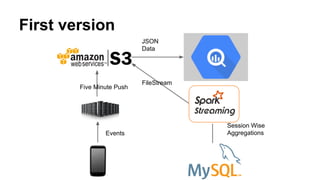

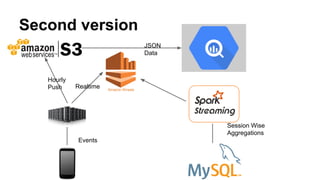





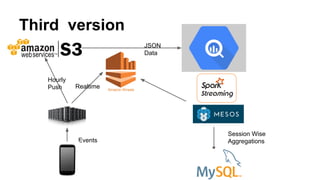

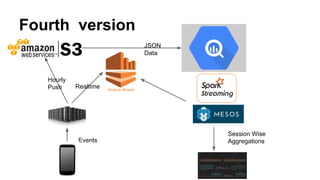


This document discusses improving mobile payments by implementing real-time analytics using Apache Spark streaming. The initial solution involved batch processing of mobile payment event data. The new solution uses Spark streaming to analyze data in real-time from sources like Amazon Kinesis. This allows for automatic alerts and a closed feedback loop. Challenges in moving from batch to streaming processing and optimizing the Python code are also covered.