Downloaded 77 times




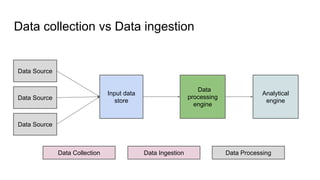
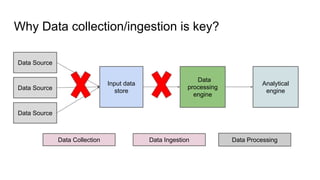



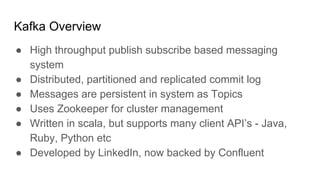


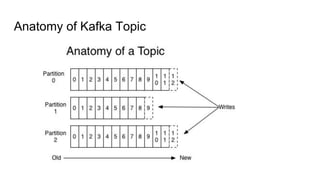
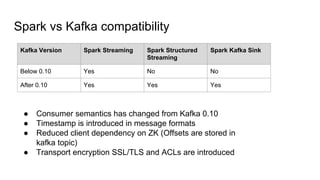
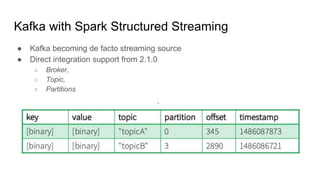


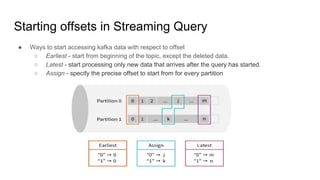








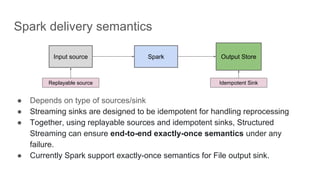



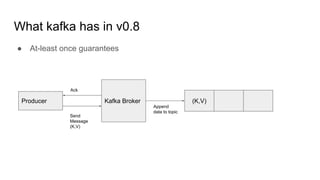
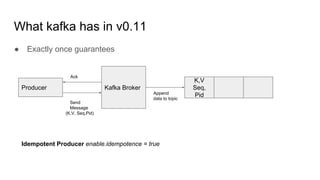
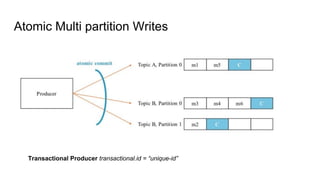
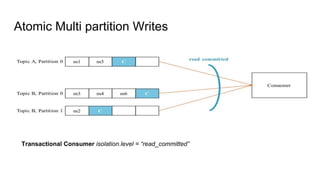





This document provides an overview of structured streaming with Kafka in Spark. It discusses data collection vs ingestion and why they are key. It also covers Kafka architecture and terminology. It describes how Spark integrates with Kafka for streaming data sources. It explains checkpointing in structured streaming and using Kafka as a sink. The document discusses delivery semantics and how Spark supports exactly-once semantics with certain output stores. Finally, it outlines new features in Kafka for exactly-once guarantees and the future of structured streaming.



































![[Big Data Spain] Apache Spark Streaming + Kafka 0.10: an Integration Story](https://cdn.slidesharecdn.com/ss_thumbnails/bigdataspainapachesparkstreamingkafka0-171117095800-thumbnail.jpg?width=640&height=640&fit=bounds)












































