Download as PDF, PPTX


















![Questions from DStream users
● Where is batch time? Or how frequently this is going to
run?
● awaitTermination is on query not on session? Does
that mean we can have multiple queries running
parallely?
● We didn't specify local[2], how does that work?
● As this program using Dataframe, how does the schema
inference works?](https://image.slidesharecdn.com/introductiontostructuredstreaming-171014154555/85/Introduction-to-Structured-streaming-18-320.jpg)

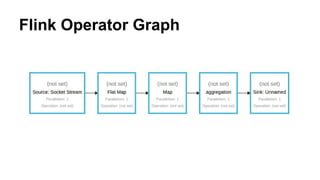
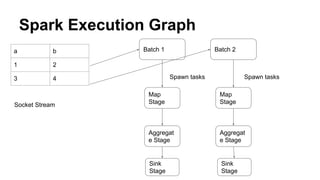














This document provides an introduction to Structured Streaming in Apache Spark. It discusses the evolution of stream processing, drawbacks of the DStream API, and advantages of Structured Streaming. Key points include: Structured Streaming models streams as infinite tables/datasets, allowing stream transformations to be expressed using SQL and Dataset APIs; it supports features like event time processing, state management, and checkpointing for fault tolerance; and it allows stream processing to be combined more easily with batch processing using the common Dataset abstraction. The document also provides examples of reading from and writing to different streaming sources and sinks using Structured Streaming.







































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)






![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)










