Download as PDF, PPTX






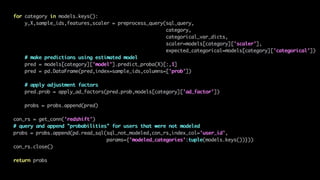
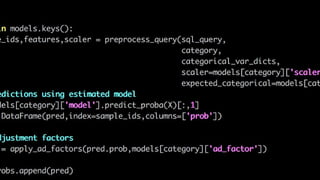

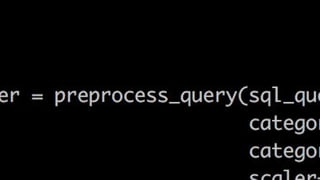






![Missing / empty data
● Easy to overlook but important
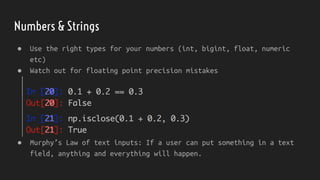
● What does missing data in the context of your analysis mean?
○ Not collected (why not?)
○ Error state
○ N/A or undefined
○ Especially for histograms, missing data lead to very poor conclusions.
● Does your data use sentinel values? (ie -9999 or “null”)
○ df[‘nps_score’].replace(-9999, np.nan)
● Imputation
● Storage](https://image.slidesharecdn.com/dirtydata-cleanitup-rockymountaindatacon2016-161111213531/85/Dirty-Data-Clean-it-up-Rocky-Mountain-DataCon-2016-20-320.jpg)
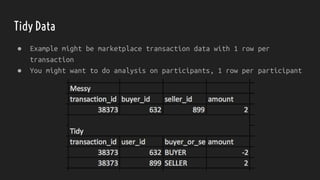



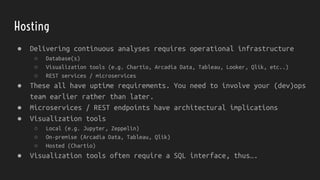

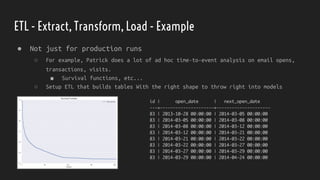
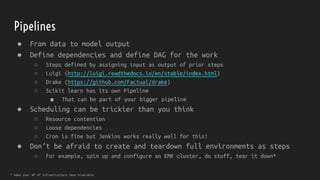
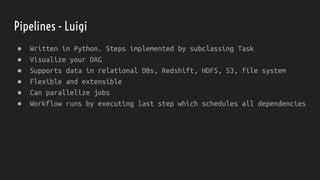
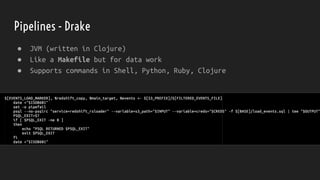


The document discusses strategies for dealing with dirty data in data science, emphasizing the importance of data cleansing and operationalizing data analysis. It covers various aspects such as handling missing data, data types, and the use of tools for ETL, pipelines, and visualization. Ultimately, it aims to provide insights for effectively integrating data science into business processes to ensure continuous insight and improved decision-making.



























































![[IJCT-V3I2P32] Authors: Amarbir Singh, Palwinder Singh](https://cdn.slidesharecdn.com/ss_thumbnails/ijct-v3i2p32-160609071950-thumbnail.jpg?width=640&height=640&fit=bounds)



























