Download as PDF, PPTX
















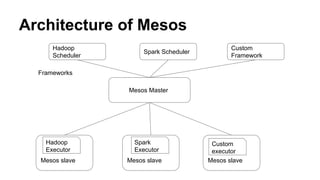

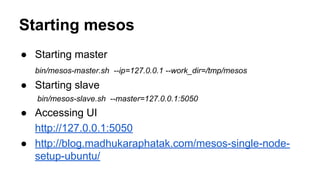















The document provides an introduction to building distributed systems using Apache Mesos, emphasizing the architecture, motivation, and components necessary for creating a custom framework. It discusses the advantages of using existing frameworks and outlines the process for building a distributed processing system akin to Spark, detailing the roles of clients, schedulers, and executors in the system. Additionally, it offers practical examples and code snippets for implementing a distributed shell and custom tasks in Scala on Mesos.