Download as PDF, PPTX












![DFAI = Direct-From-App-Ingest
• Market-order
• order/invoice: sales_order_invoice table
• create
• updateAddress
• order/order : sales_order table
• create
• update
• order/payment: sales_order_payment table
• create
• insertUpdateExisting
• update
• order/item:sales_order_item table
• create
• update
• order/address: sales_order_address table
• create
• updateAddress
• order/return_fulfillment: sales_order_return table
• create
• update
• order/refund: sales_order_refund table
• create
• update
Order/invoice schema example:
{ "namespace" : "com.paytm",
"name": "order_invoice_value",
"type": "record",
"fields": [ { "name": "tax_amount", "type": unitSchemas.nullLong},
{ "name": "surchange_amount", "type": unitSchemas.nullLong.name},
{ "name": "subtotal", "type":unitSchemas.nullLong.name},
{ "name": "subtotal_incl_tax", "type":unitSchemas.nullLong.name},
{ "name": "fulfillment_id", "type":unitSchemas.nullLong.name},
{ "name": "created_at", "type": unitSchemas.str} ]
}
19](https://image.slidesharecdn.com/2015nov27thugpaytmrtingestbrieffinal-151128003154-lva1-app6892/85/2015-nov-27_thug_paytm_rt_ingest_brief_final-19-320.jpg)




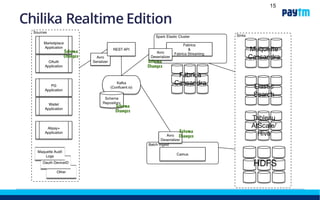
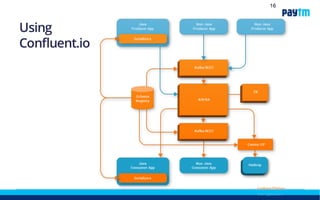
The document discusses Paytm Labs' transition from batch data ingestion to real-time data ingestion using Apache Kafka and Confluent. It outlines their current batch-driven pipeline and some of its limitations. Their new approach, called DFAI (Direct-From-App-Ingest), will have applications directly write data to Kafka using provided SDKs. This data will then be streamed and aggregated in real-time using their Fabrica framework to generate views for different use cases. The benefits of real-time ingestion include having fresher data available and a more flexible schema.






























































































