Download as PDF, PPTX












![WriterSupport Interface
● Entry Point to the Data Source
● Has One Method
def createWriter(jobId: String, schema: StructType, mode: SaveMode,options:
DataSourceOptions): Optional[DataSourceWriter]
● SaveMode and Schema same as V1 API
● Returns Optional for ready only sources](https://image.slidesharecdn.com/understandingtransactionalwritesindatasourcev2-180813053131/85/Understanding-transactional-writes-in-datasource-v2-14-320.jpg)
![DataSourceWriter Interface
● Entry Point to Writer
● Has Three Methods
○ def createWriterFactory(): DataWriterFactory[Row]
○ def commit(messages: Array[WriterCommitMessage])
○ def abort(messages: Array[WriterCommitMessage])
● Responsible for create writer factory
● WriterCommitMessage is interface for communication
● Can see transactional support throughout of the API](https://image.slidesharecdn.com/understandingtransactionalwritesindatasourcev2-180813053131/85/Understanding-transactional-writes-in-datasource-v2-15-320.jpg)
![DataWriterFactory Interface
● Follow factory design pattern of Java to create actual
data writes
● This code for creating writers for uniquely identifying
different partitions
● It has one method to create data write
def createDataWriter(partitionId: Int, attemptNumber: Int): DataWriter[Row]
● attemptNumber for retrying tasks](https://image.slidesharecdn.com/understandingtransactionalwritesindatasourcev2-180813053131/85/Understanding-transactional-writes-in-datasource-v2-16-320.jpg)












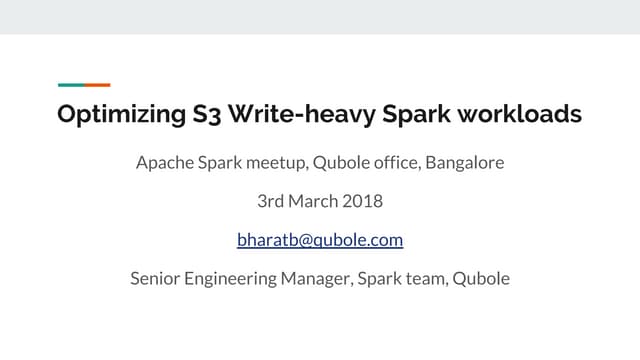
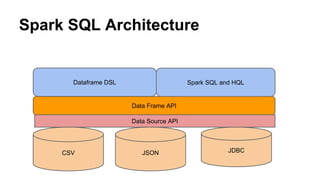
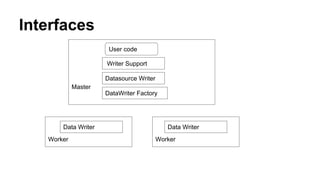
This document discusses the new Transactional Writes in Datasource V2 API introduced in Spark 2.3. It outlines the shortcomings of the previous V1 write API, specifically the lack of transaction support. It then describes the anatomy of the new V2 write API, including interfaces like DataSourceWriter, DataWriterFactory, and DataWriter that provide transactional capabilities at the partition and job level. It also covers how the V2 API addresses partition awareness through preferred location hints to improve performance.