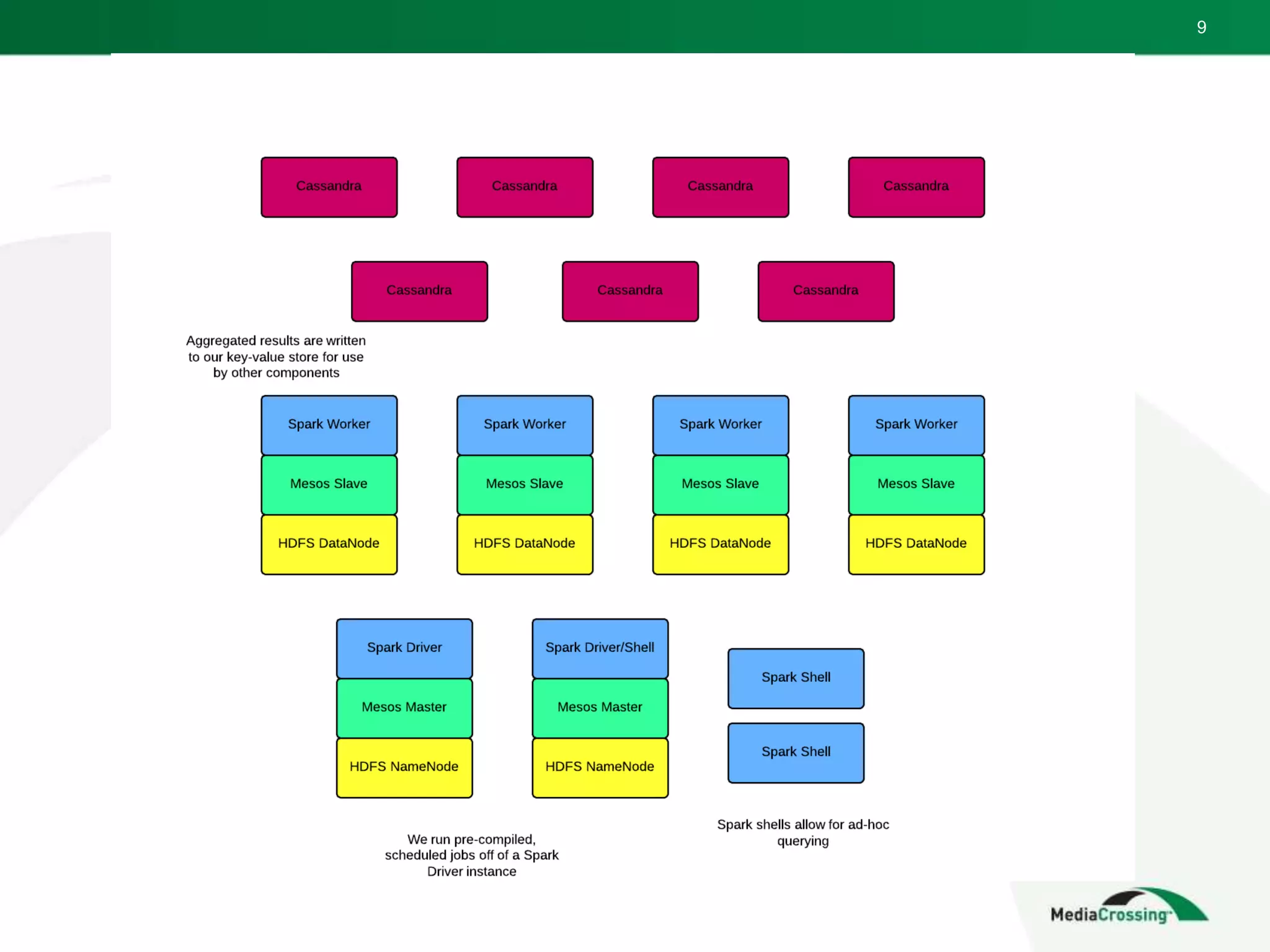
The document presents Gary Malouf's insights on the role of Spark at MediaCrossing, highlighting the company's focus on high throughput, low latency trading and the use of functional programming and Scala for building scalable software. It explains their data aggregation processes using Spark and mentions the importance of a feedback loop inspired by lambda architecture principles for improving trading strategies. Malouf also shares future plans for increasing quantitative and analytical usage of Spark while minimizing reliance on the broader Hadoop ecosystem.