Downloaded 30 times


































![Persistent Params
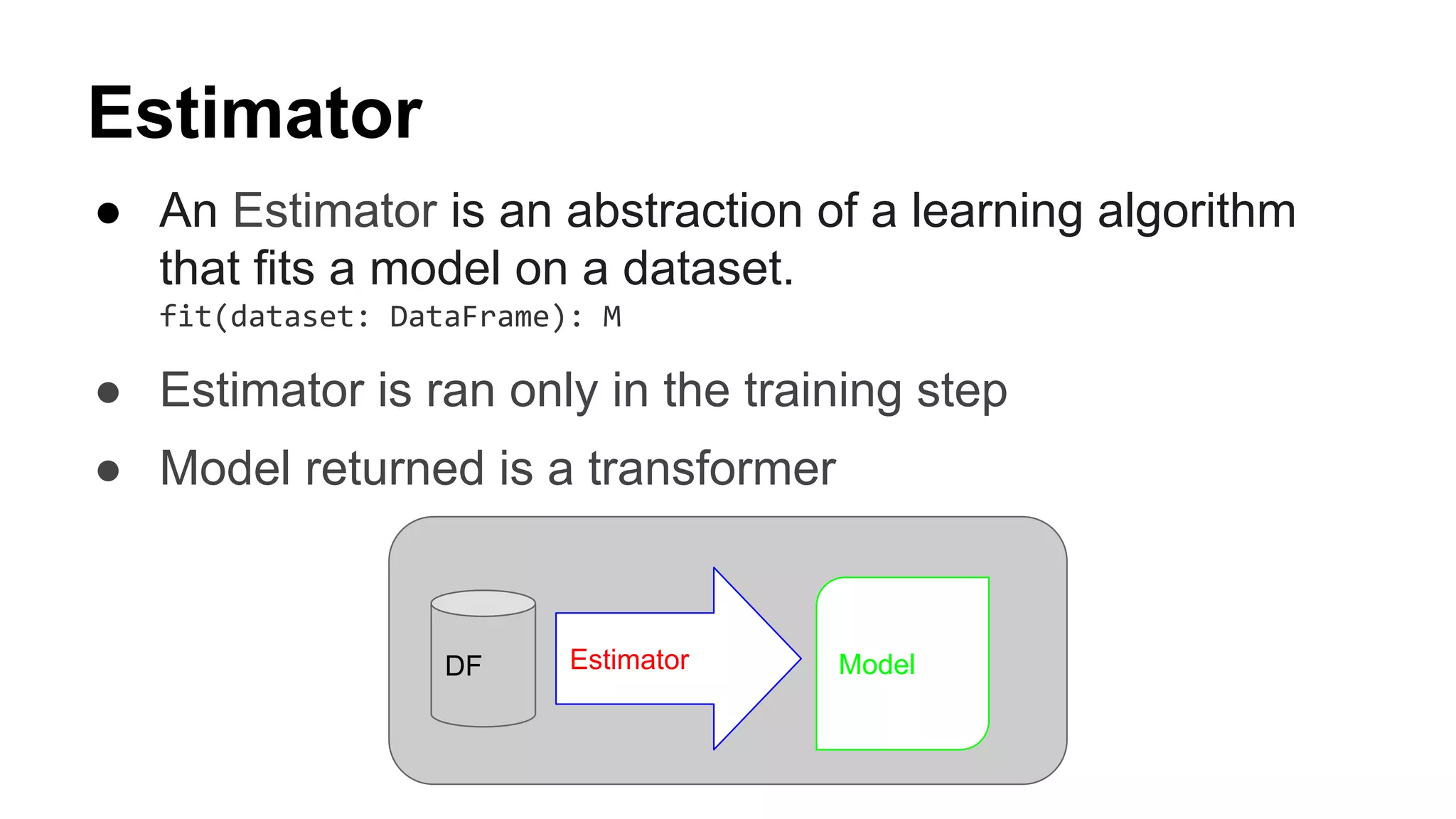
● If params are of type Double, Float, Long, Int, Boolean, Array,
Vector they are persistent params.
● Spark internally has logic to persist them
● Custom type like Map[K,V] or Option[Double] which we have
used cannot be persisted by Spark
● A param implementation has to be provided by the user
which requires below methods to be implemented
def jsonEncode(value: Option[T]): String
def jsonDecode(json: String): Option[T]
com.shashank.sparkml.operationalize.stages.PersistentParams](https://image.slidesharecdn.com/productionalizingsparkml-171113031142/75/Productionalizing-Spark-ML-37-2048.jpg)





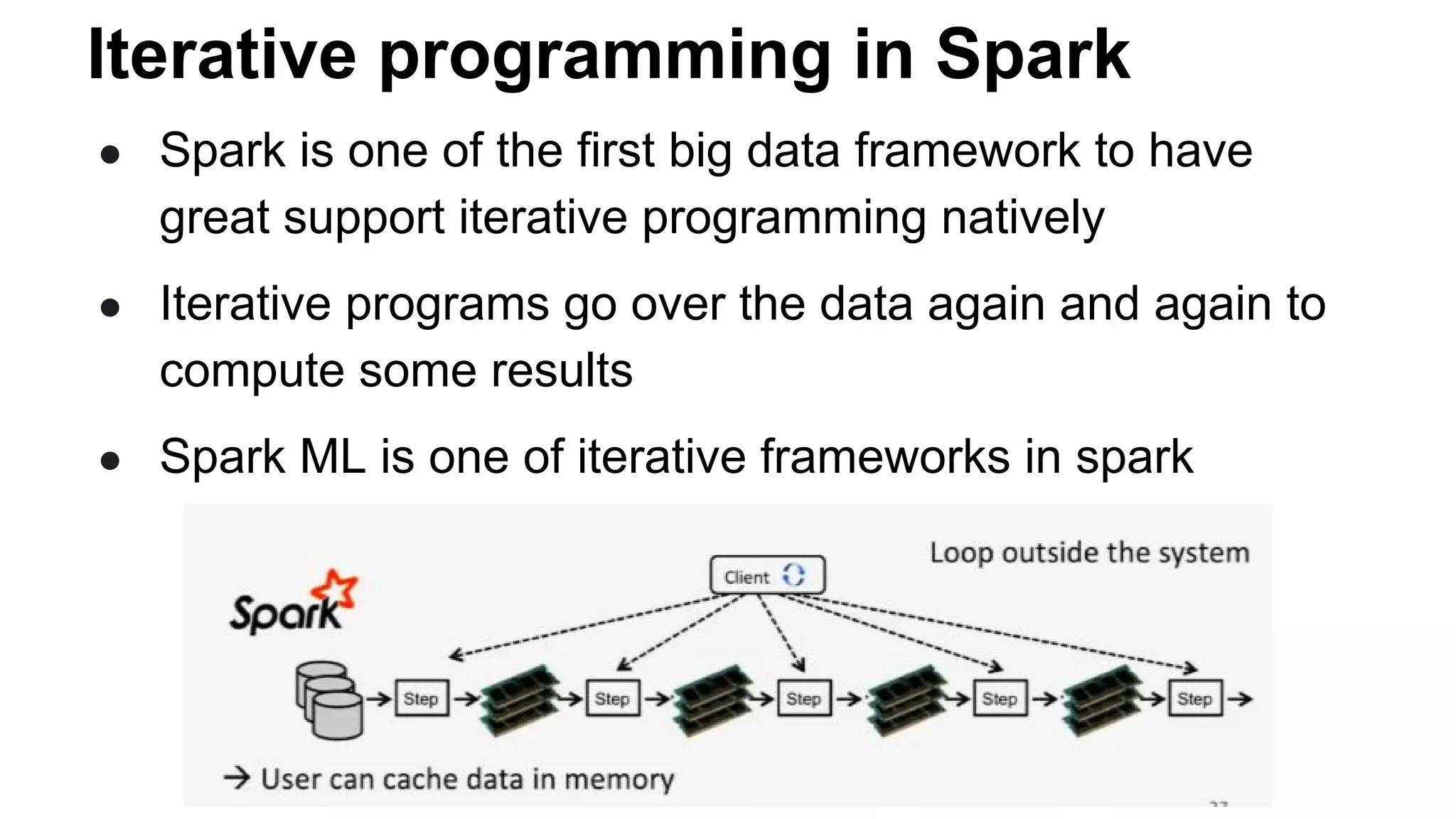
This document discusses best practices for productionalizing machine learning models built with Spark ML. It covers key stages like data preparation, model training, and operationalization. For data preparation, it recommends handling null values, missing data, and data types as custom Spark ML stages within a pipeline. For training, it suggests sampling data for testing and caching only required columns to improve efficiency. For operationalization, it discusses persisting models, validating prediction schemas, and extracting feature names from pipelines. The goal is to build robust, scalable and efficient ML workflows with Spark ML.






























































![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)



