Download as PDF, PPTX





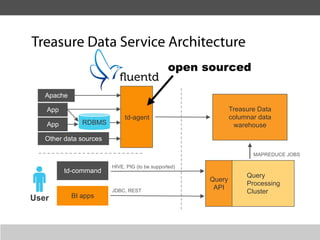
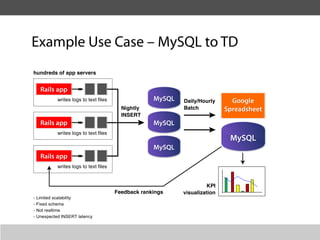
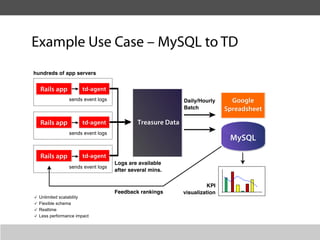







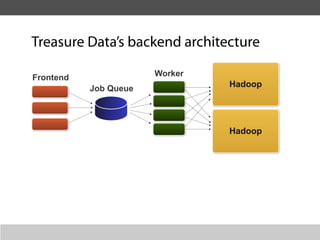
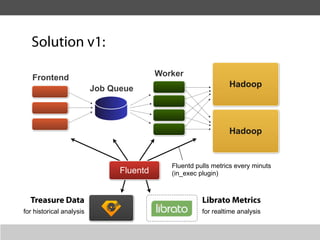
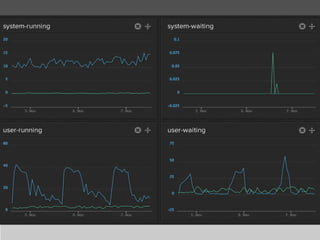


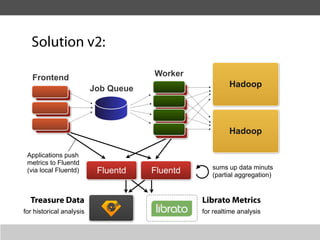

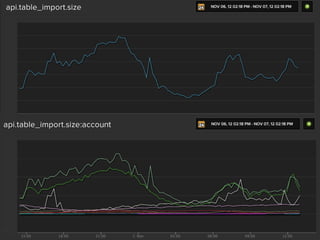




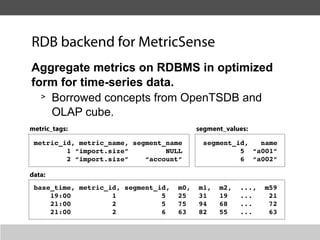






This document summarizes a presentation about collecting application metrics in decentralized systems. It discusses how Treasure Data solved problems they faced by collecting metrics from their applications and services. This allowed them to monitor performance, notice issues, understand user behavior, and prioritize tasks. They open sourced their metrics collection system, MetricSense, to help others address similar challenges.











































































