This document discusses how StreamSets and Spark can be used together for analytics insights in retail. Some key points:
- StreamSets Data Collector (SDC) is used to ingest IoT and sensor data from various sources into a common format and process the data in real-time using Spark evaluators.
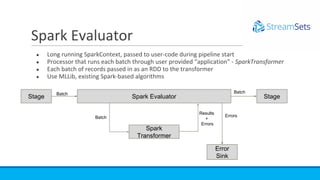
- The Spark evaluator allows running Spark transformations on batches of data within SDC pipelines to do tasks like anomaly detection, sentiment analysis, and fraud detection.
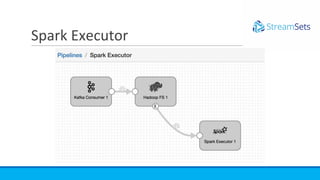
- SDC can also be used to move data to and from Spark for end-of-batch processing using a Spark executor, such as running jobs on Databricks after files land in S3.
- Together, SDC and Spark







![● SDC transparently converts several formats into SDC Record:
○ JSON
○ Avro
○ Byte[]
○ Delimited
○ Protobuf
○ Text
○ XML
○ Apache Log format
● Wow! That’s a lot of formats!
● Process SDC records and then write it out in any format, not necessarily the one you got
the data in!
● We also support ingesting Binary data
Formatting the data](https://image.slidesharecdn.com/streamsetsandspark-retail-170608001015/85/Streamsets-and-spark-in-Retail-8-320.jpg)
![● In-stream processing using processors
● Most processors are map operations on individual records
● Scripting processors process batches of records in python, groovy, javascript
● Spark Evaluators:
○ Perform arbitrary Spark operations on each batch of records
○ Each batch is an RDD[Record]
○ Stash batches or maintain state!
○ Perform reduces/shuffles.
○ Cluster mode pipelines
■ Each pipeline in the cluster generates an RDD batch
■ RDD can see all data coming in through the cluster
Processing the data](https://image.slidesharecdn.com/streamsetsandspark-retail-170608001015/85/Streamsets-and-spark-in-Retail-9-320.jpg)