















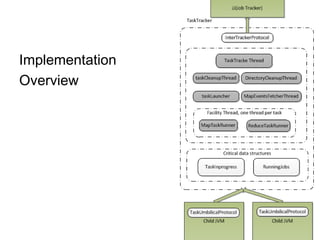









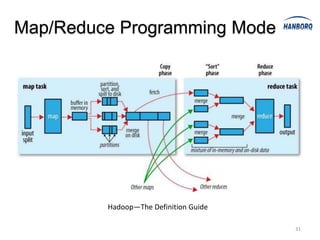
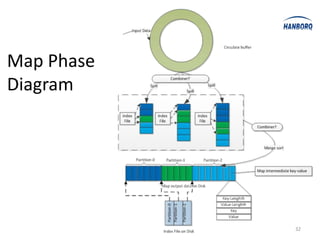


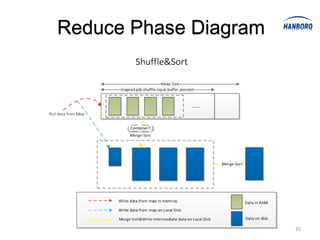










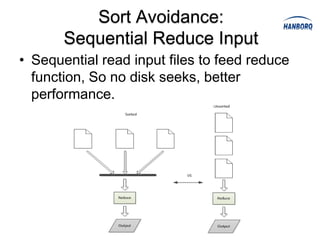
![Sort Avoidance: Spill and Partition
• When spills, records compare by partition
only.
• Partition comparison using counting sort [O(n)],
not quick sort [O(nlog n)].](https://image.slidesharecdn.com/hadoopmapreduce-introductionanddeepinsight-130319020141-phpapp01/85/Hadoop-MapReduce-Introduction-and-Deep-Insight-51-320.jpg)





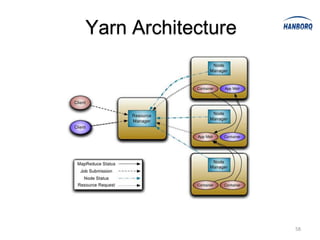






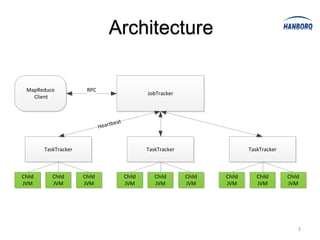
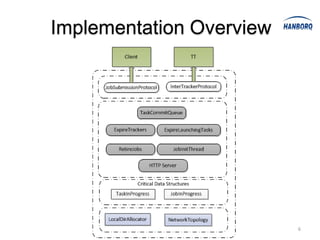
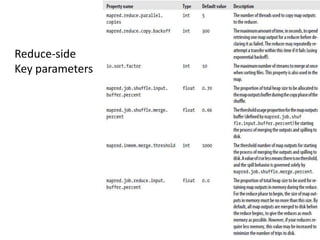
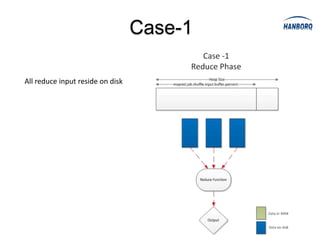
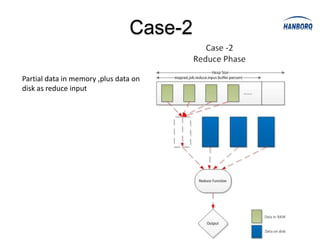
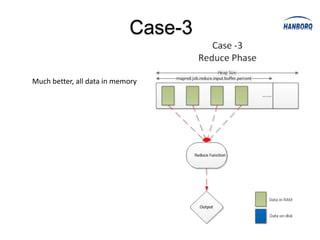
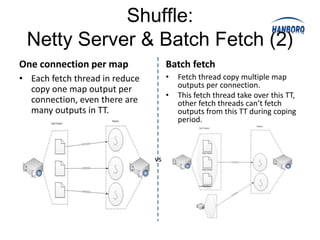
Hadoop MapReduce introduces YARN, which separates cluster resource management from application execution. YARN introduces a global ResourceManager and per-node NodeManagers to manage resources. Applications run as ApplicationMasters and containers on the nodes. This improves scalability, fault tolerance, and allows various application paradigms beyond MapReduce. Optimization techniques for MapReduce include tuning buffer sizes, enabling sort avoidance when sorting is unnecessary, and using Netty and batch fetching to improve shuffle performance.















![[Altibase] 13 backup and recovery](https://cdn.slidesharecdn.com/ss_thumbnails/altibase13backupandrecovery-160126072259-thumbnail.jpg?width=640&height=640&fit=bounds)







































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)







