





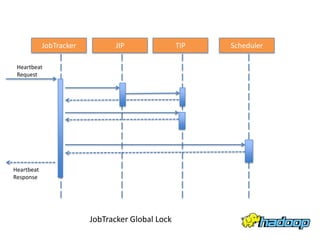

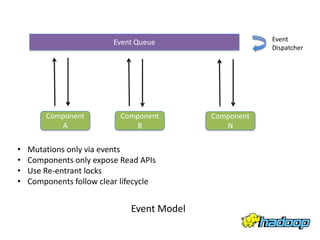
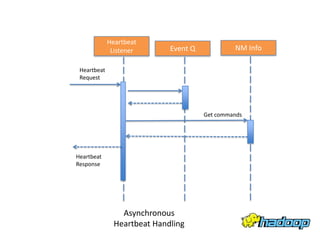
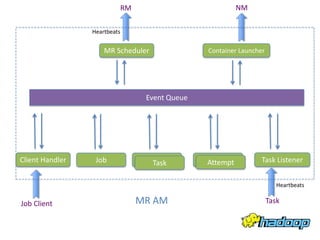
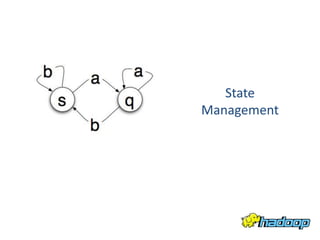

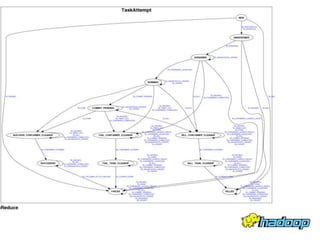





YARN - Under the Hood Sharad Agarwal discusses the architecture of YARN and how it handles concurrency. YARN uses an event-driven model with asynchronous processing to improve scalability. It employs a lightweight state machine library to better manage state transitions and make debugging easier. This declarative approach to state management improves on Hadoop 1's approach which was difficult to maintain and debug.





















































