







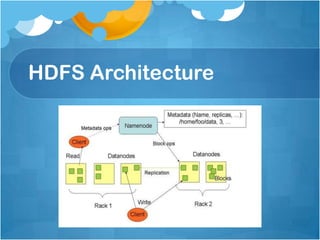










![JobClient.submitJob - 1
Check input and output, e.g. check if the output
directory is already existing
job.getInputFormat().validateInput(job);
job.getOutputFormat().checkOutputSpecs(fs, job);
Get InputSplits, sort, and write output to HDFS
InputSplit[] splits = job.getInputFormat().
getSplits(job, job.getNumMapTasks());
writeSplitsFile(splits, out); // out is
$SYSTEMDIR/$JOBID/job.split](https://image.slidesharecdn.com/005hadoopintroduction-130604110329-phpapp01/85/Hadoop-Introduction-20-320.jpg)




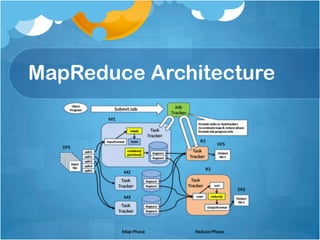
![JobInProgress - 2
splits = JobClient.readSplitFile(splitFile);
numMapTasks = splits.length;
maps[i] = new
TaskInProgress(jobId, jobFile, splits[i], jobtracker, co
nf, this, i);
reduces[i] = new
TaskInProgress(jobId, jobFile, splits[i], jobtracker, co
nf, this, i);
JobStatus --> JobStatus.RUNNING](https://image.slidesharecdn.com/005hadoopintroduction-130604110329-phpapp01/85/Hadoop-Introduction-25-320.jpg)












This document provides an overview of Apache Hadoop, an open-source software framework for distributed storage and processing of large datasets across clusters of commodity hardware. It describes Hadoop's core components like HDFS for distributed file storage and MapReduce for distributed processing. Key aspects covered include HDFS architecture, data flow and fault tolerance, as well as MapReduce programming model and architecture. Examples of Hadoop usage and a potential project plan for load balancing enhancements are also briefly mentioned.









































































