Download as PDF, PPTX









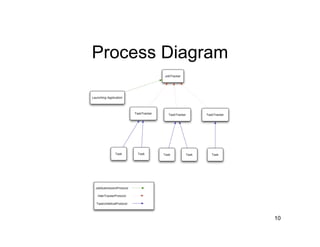









This document summarizes Hadoop MapReduce, including its goals of distribution and reliability. It describes the roles of mappers, reducers, and other system components like the JobTracker and TaskTracker. Mappers process input splits in parallel and generate intermediate key-value pairs. Reducers sort and group the outputs by key before processing each unique key. The JobTracker coordinates jobs while the TaskTracker manages tasks on each node.



































































































