






























![USE HADOOP'S RAW COMPARATOR API
Hadoop comes with a RawComparator API for comparing records in
their serialized (raw) form
Don't make sorting more expensive than it already is
public interface RawComparator<T> {
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2);
}](https://image.slidesharecdn.com/june9145pmtwitterlevensonoconnellv32-150701223312-lva1-app6891/85/Hadoop-Performance-Optimization-at-Scale-Lessons-Learned-at-Twitter-33-320.jpg)
![USE HADOOP'S RAW COMPARATOR API
Unfortunately, this requires you to write a custom comparator by hand
And assumes that your data is actually easy to compare in its
serialized form
Don't make sorting more expensive than it already is
public interface RawComparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}](https://image.slidesharecdn.com/june9145pmtwitterlevensonoconnellv32-150701223312-lva1-app6891/85/Hadoop-Performance-Optimization-at-Scale-Lessons-Learned-at-Twitter-34-320.jpg)

















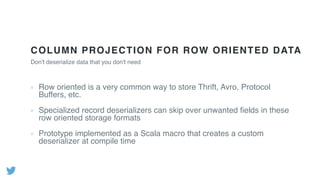


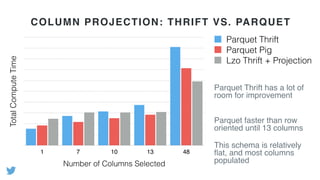


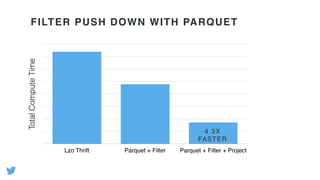













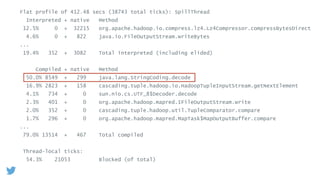
- Profiling Hadoop jobs at Twitter revealed that compression/decompression of intermediate data and deserialization of complex object keys were very expensive. Optimizing these led to performance improvements of 1.5x or more. - Using columnar file formats like Apache Parquet allows reading only needed columns, avoiding deserialization of unused data. This led to gains of up to 3x. - Scala macros were developed to generate optimized implementations of Hadoop's RawComparator for common data types, avoiding deserialization for sorting.
























































































![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)














