



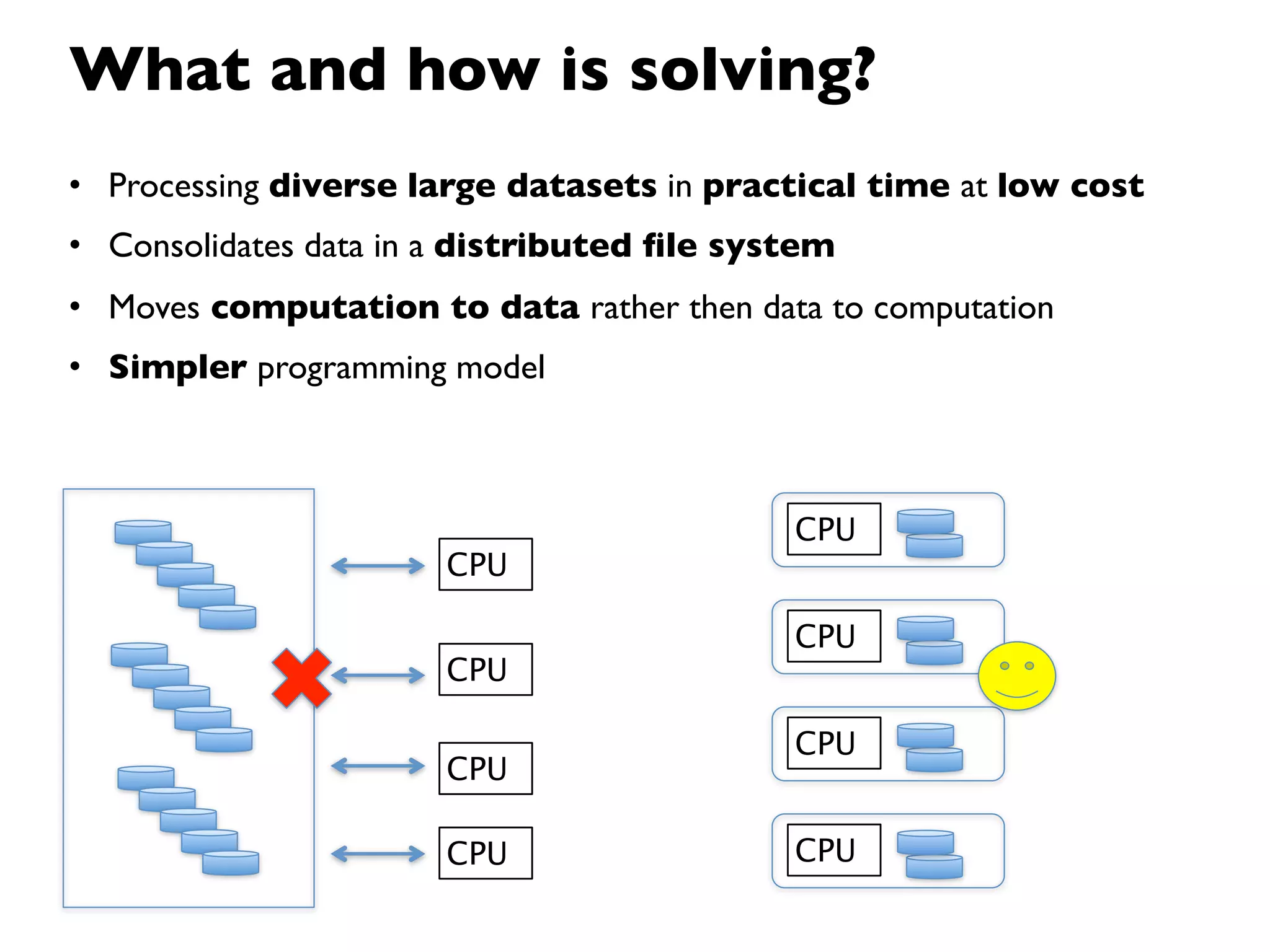

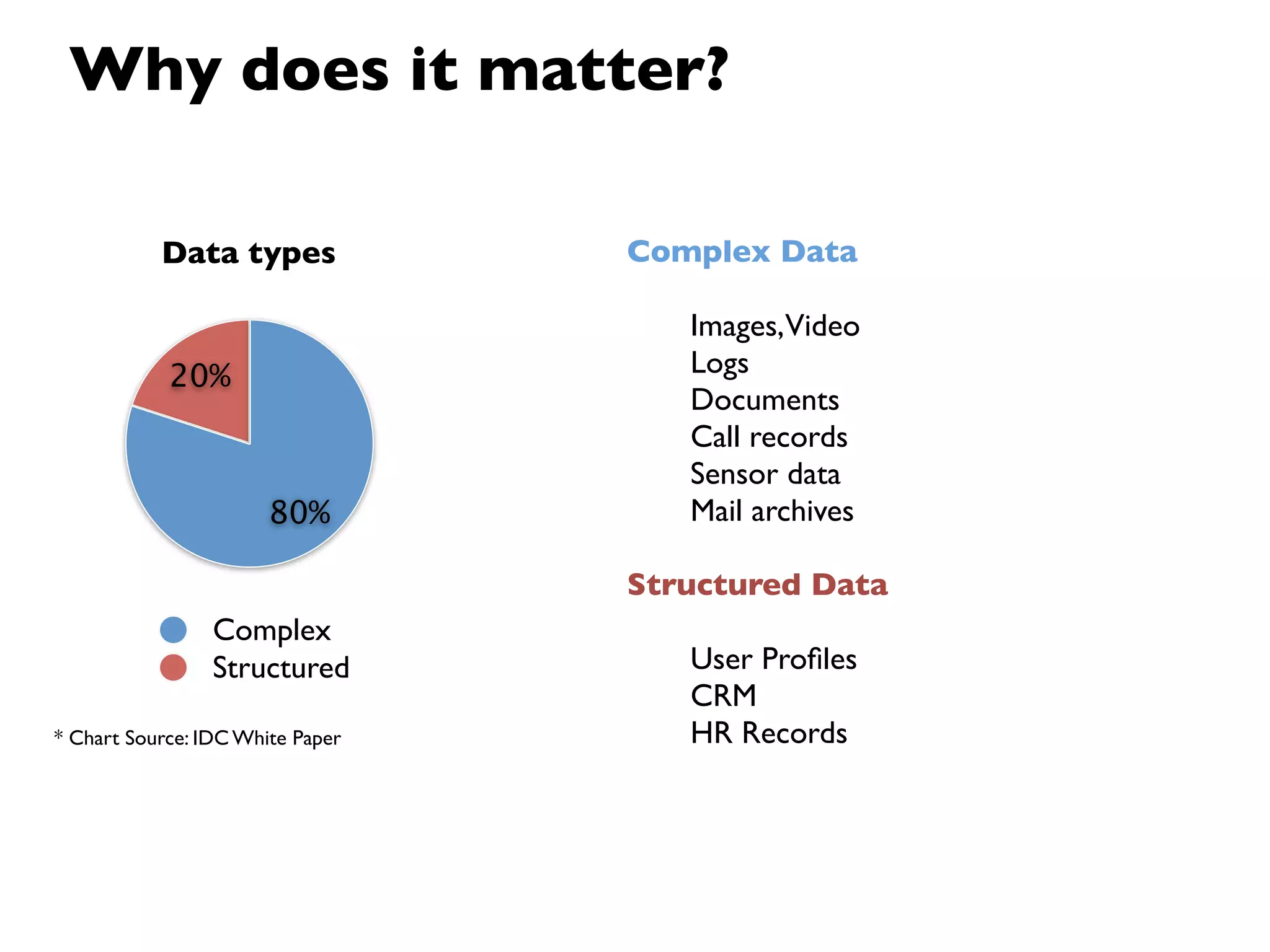







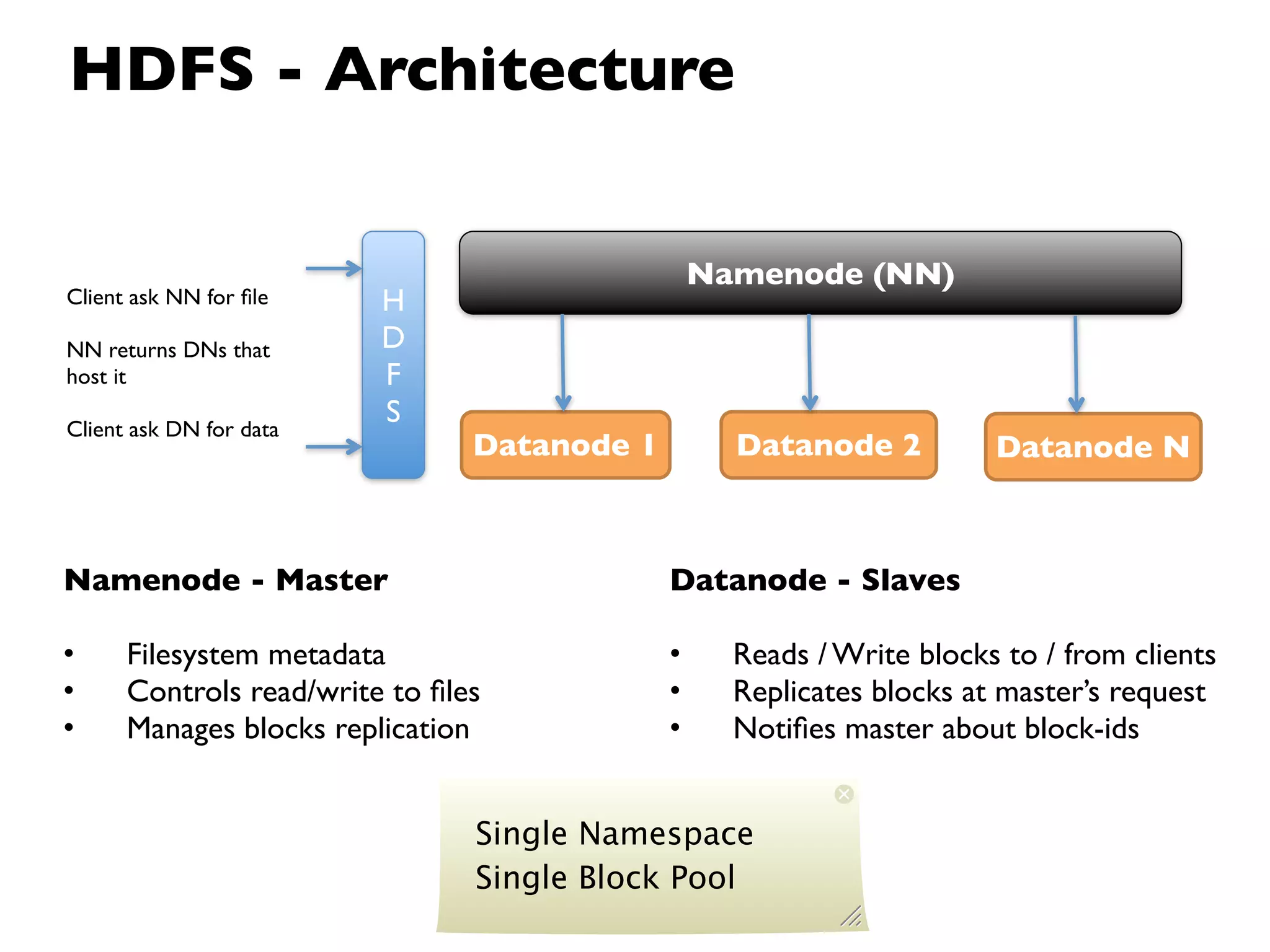

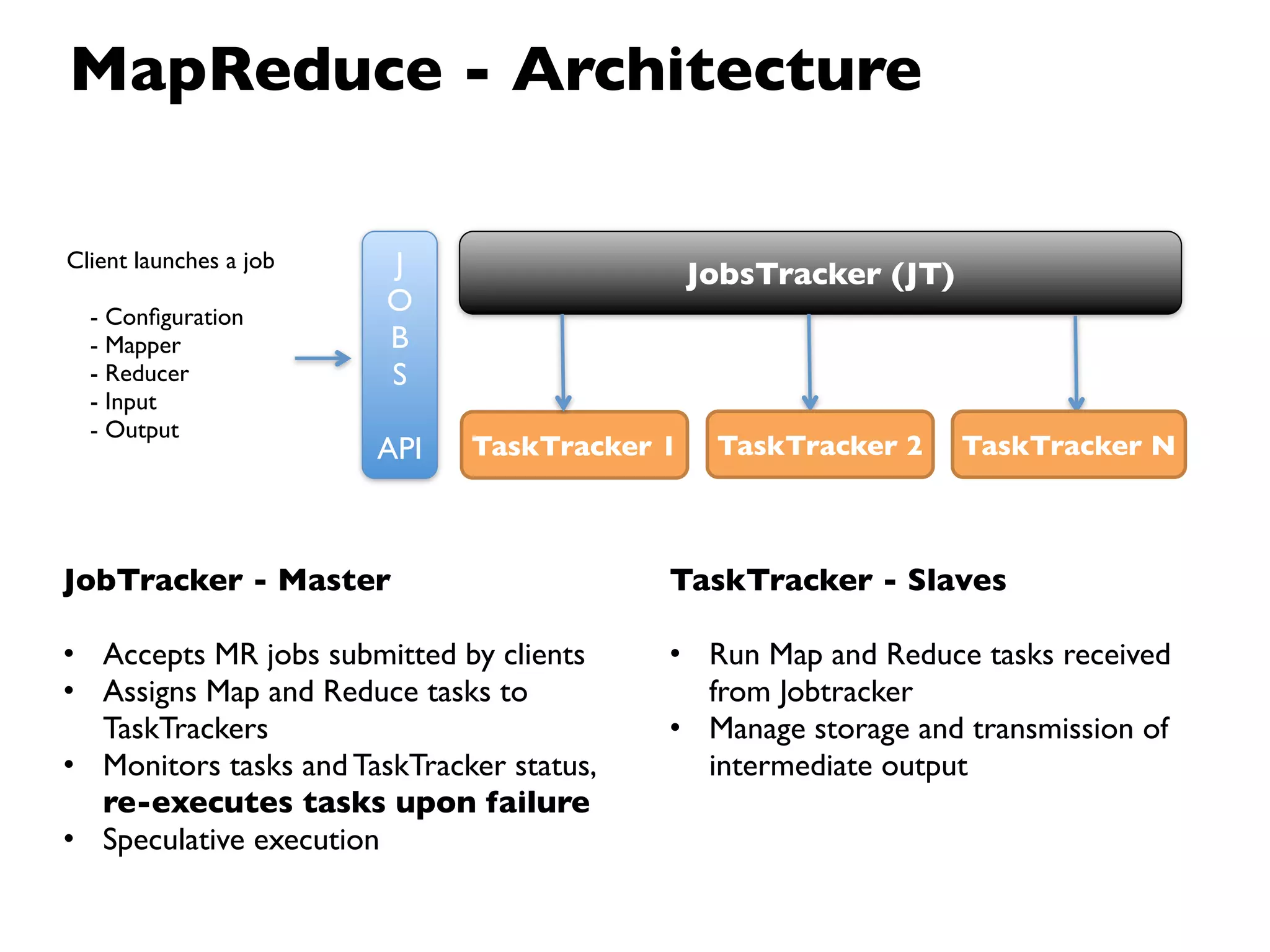
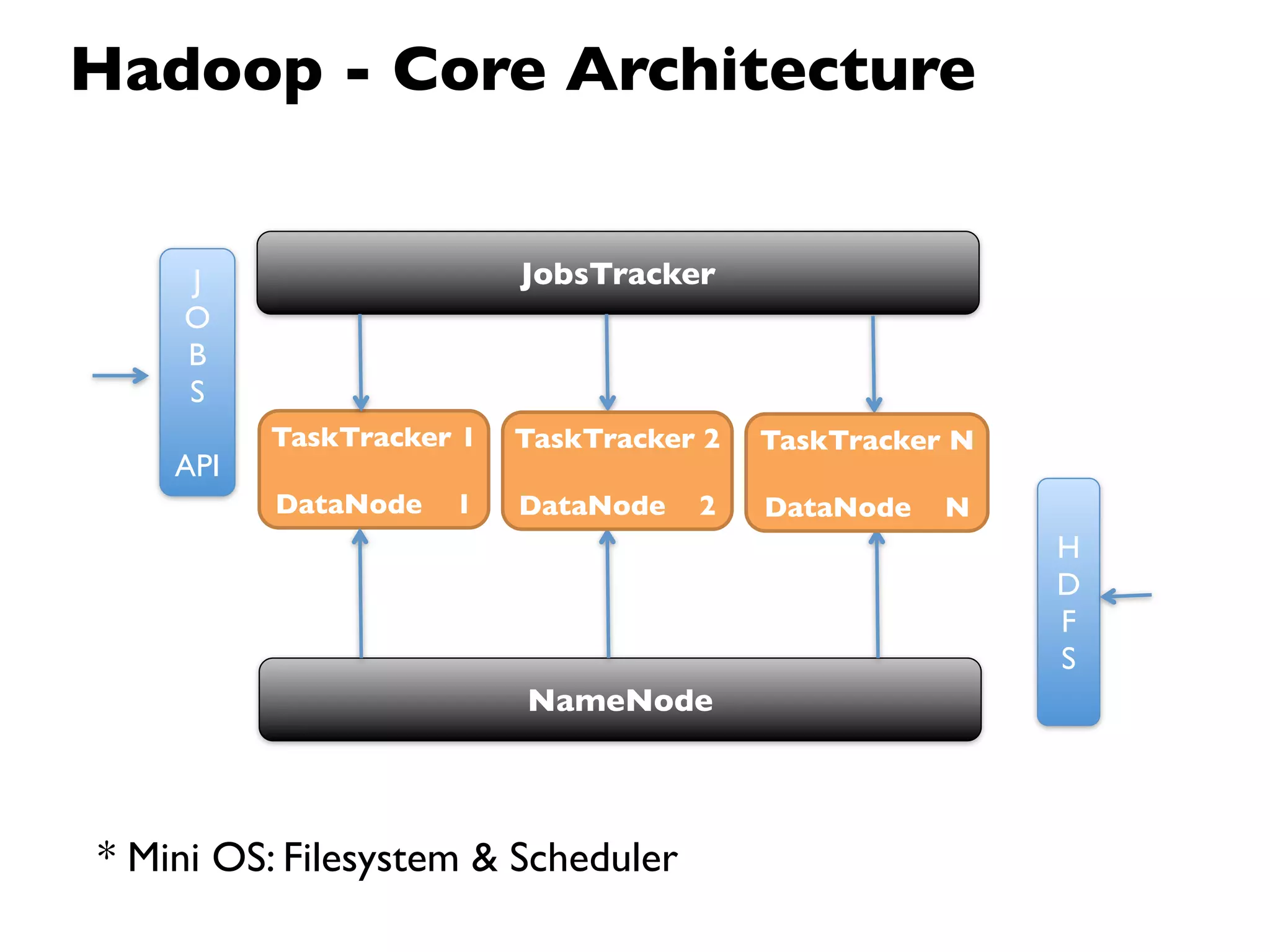
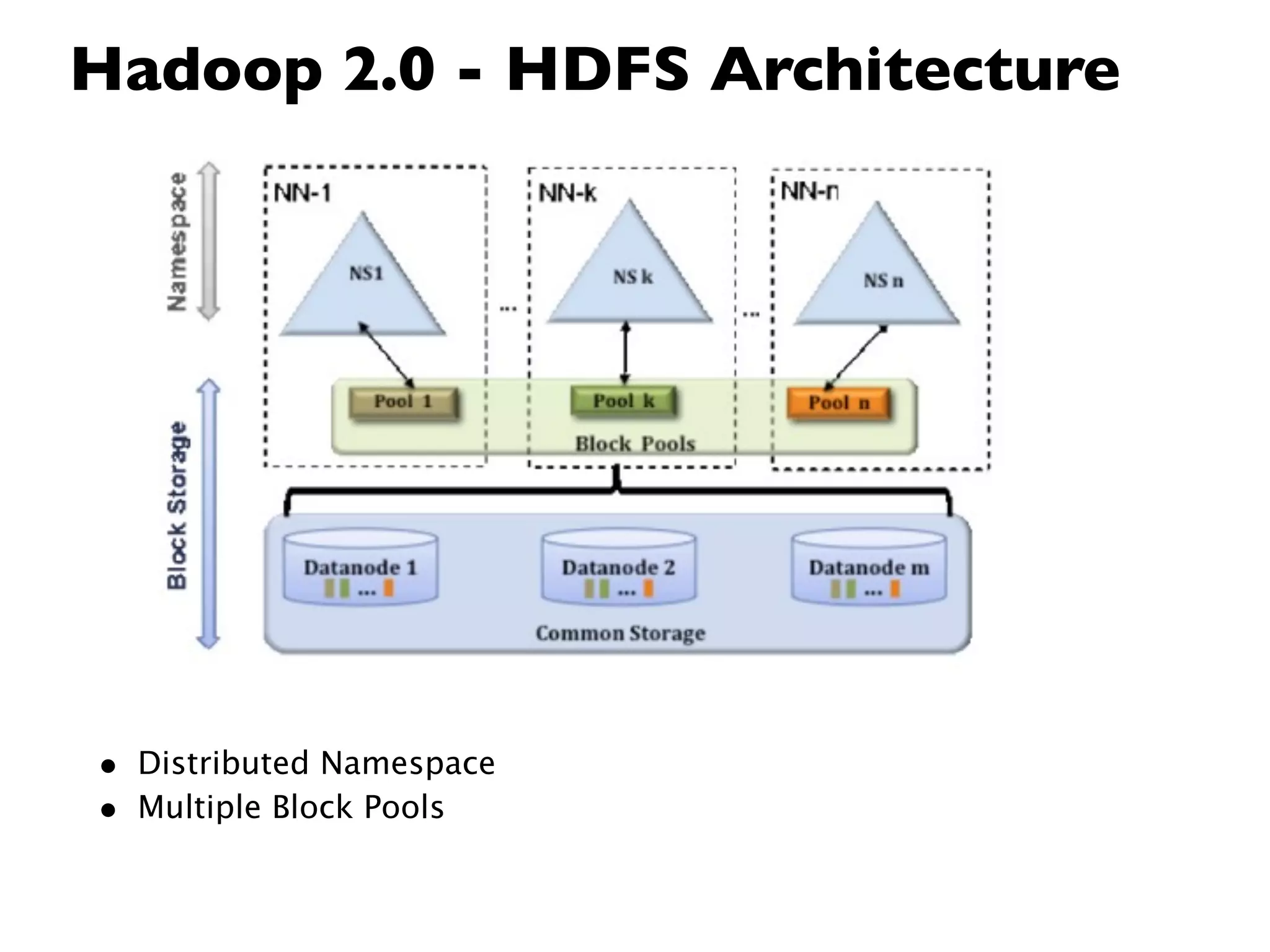
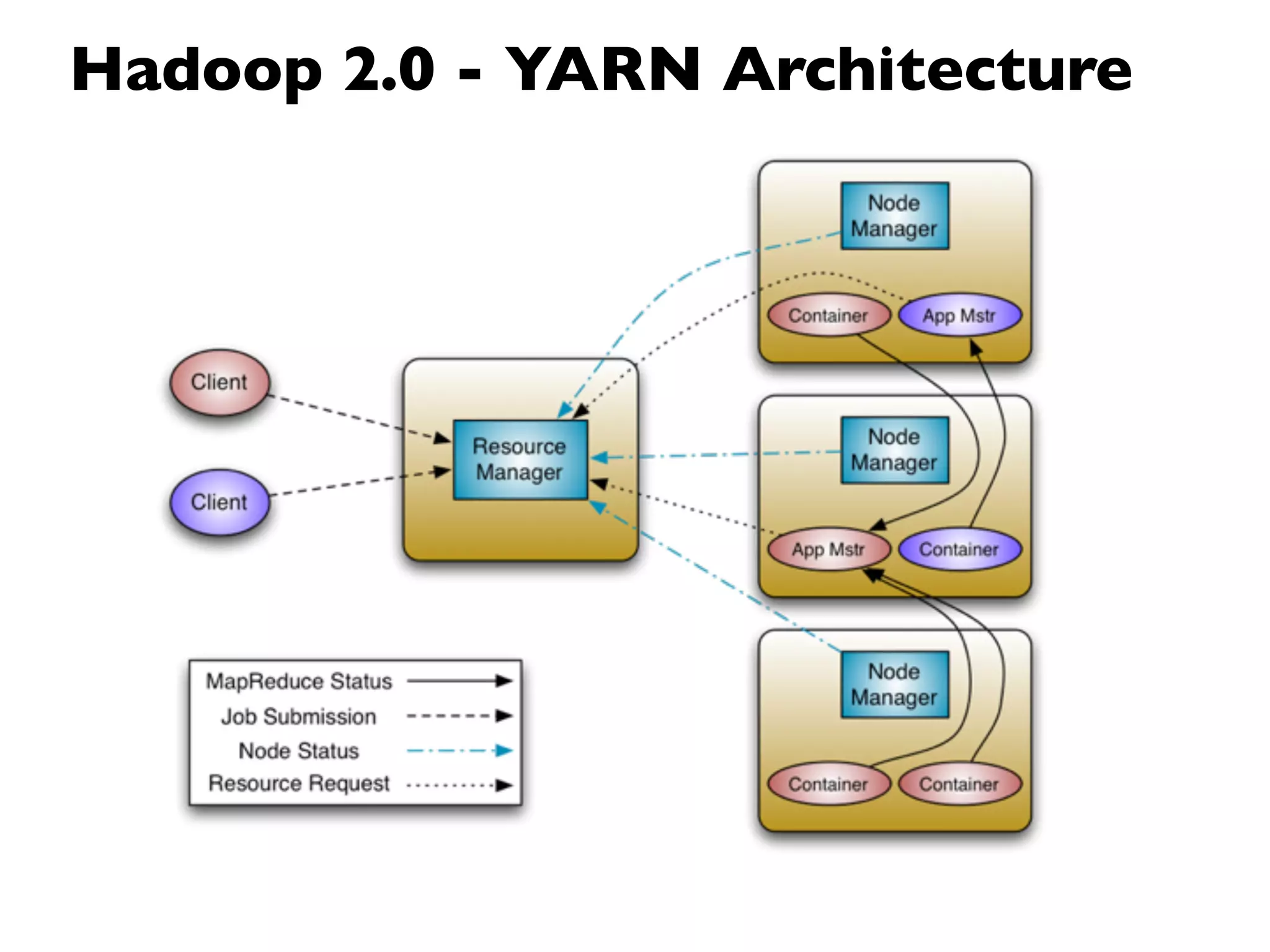

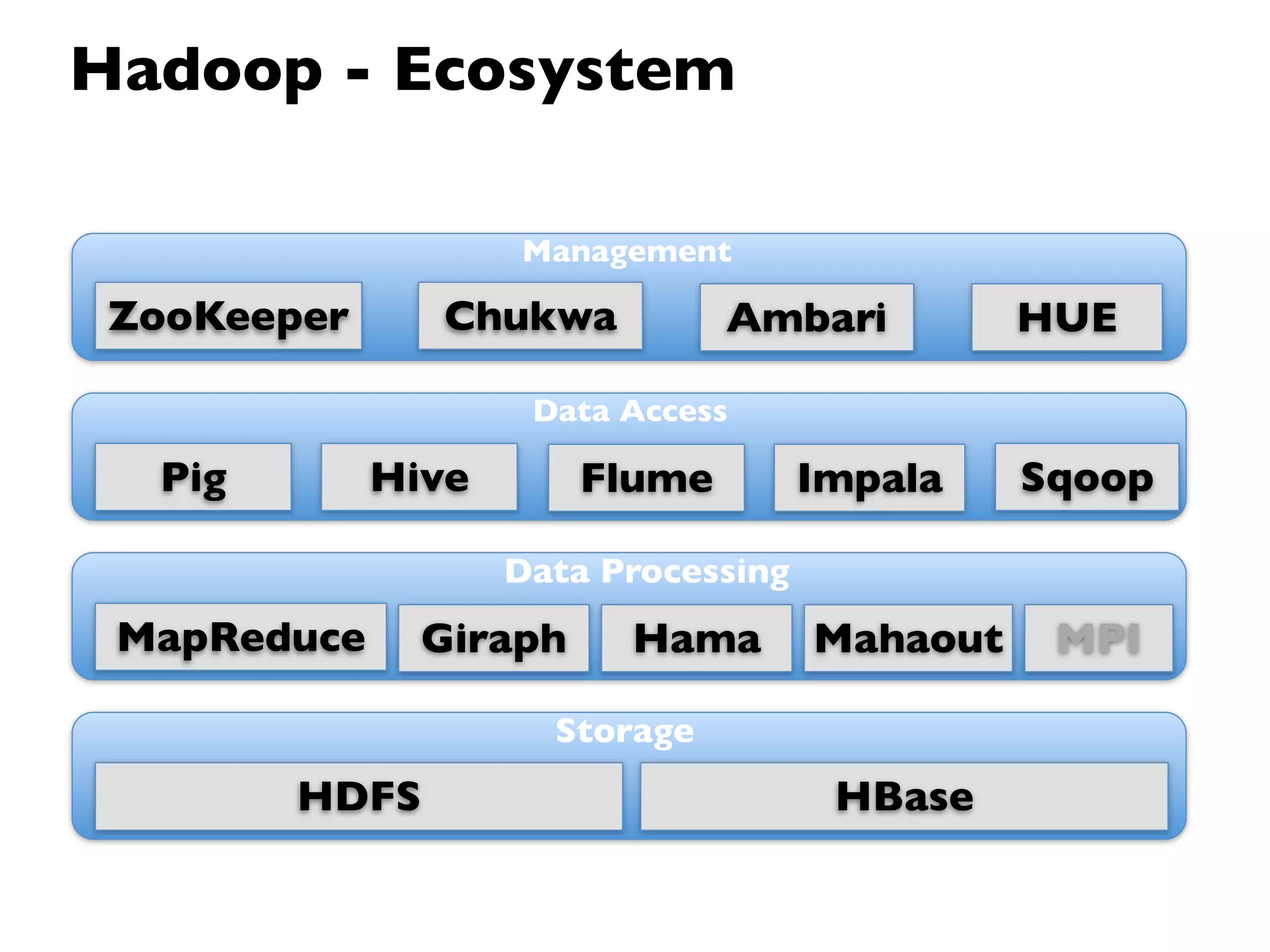











This document provides an overview of Hadoop, an open source framework for distributed storage and processing of large datasets. It discusses: - The background and architecture of Hadoop, including its core components HDFS and MapReduce. - How Hadoop is used to process diverse large datasets across commodity hardware clusters in a scalable and fault-tolerant manner. - Examples of use cases for Hadoop including ETL, log processing, and recommendation engines. - The Hadoop ecosystem including related projects like Hive, HBase, Pig and Zookeeper. - Basic installation, security considerations, and monitoring of Hadoop clusters.











































































