


![Features
• SQL
– CREATE STREAM stream_name (col_name data_type [, ...])
FROM [LOCAL] {FILE | NODE | SOURCE} input_spec
[EVENT FORMAT format_spec
[PROPERTIES (key = val, …)]]
– SELECT select_expr, select_expr ... FROM stream_reference
[ JOIN stream_reference ON join_expr OVER range_expr, JOIN ... ]
[ WHERE where_condition ]
[ GROUP BY column_list ] [ OVER range_expr ] [ HAVING
having_condition ]
[ WINDOW window_name AS ( range_expr ), WINDOW ... ]](https://image.slidesharecdn.com/flumebase-study-willis-130319035743-phpapp01/85/FlumeBase-Study-7-320.jpg)


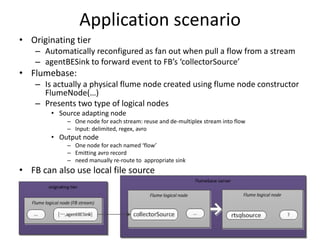
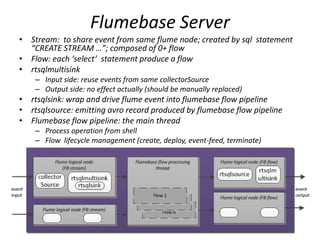
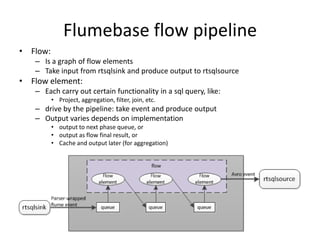
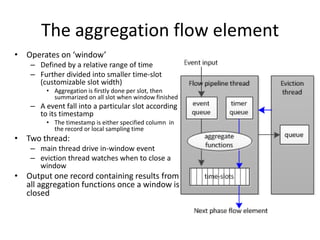
This document summarizes a study on FlumeBase, a system for processing streaming data using SQL queries. It describes FlumeBase's architecture, including how it integrates with Flume and uses SQL queries to define streams, flows, and flow elements for aggregating data. The document notes some potential issues with FlumeBase regarding window alignment, deployment integration with Flume, and code maturity.
![[Altibase] 9 replication part2 (methods and controls)](https://cdn.slidesharecdn.com/ss_thumbnails/altibase9replicationpart2methodsandcontrols-160126071813-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Altibase] 10 replication part3 (system design)](https://cdn.slidesharecdn.com/ss_thumbnails/altibase10replicationpart3systemdesign-160126072046-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Altibase] 12 replication part5 (optimization and monitoring)](https://cdn.slidesharecdn.com/ss_thumbnails/altibase12replicationpart5optimizationandmonitoring-160126072237-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Altibase] 13 backup and recovery](https://cdn.slidesharecdn.com/ss_thumbnails/altibase13backupandrecovery-160126072259-thumbnail.jpg?width=640&height=640&fit=bounds)




































![Complex Er[jl]ang Processing with StreamBase](https://cdn.slidesharecdn.com/ss_thumbnails/complexerjlangprocessing-pptx-110611095407-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


































