Download to read offline
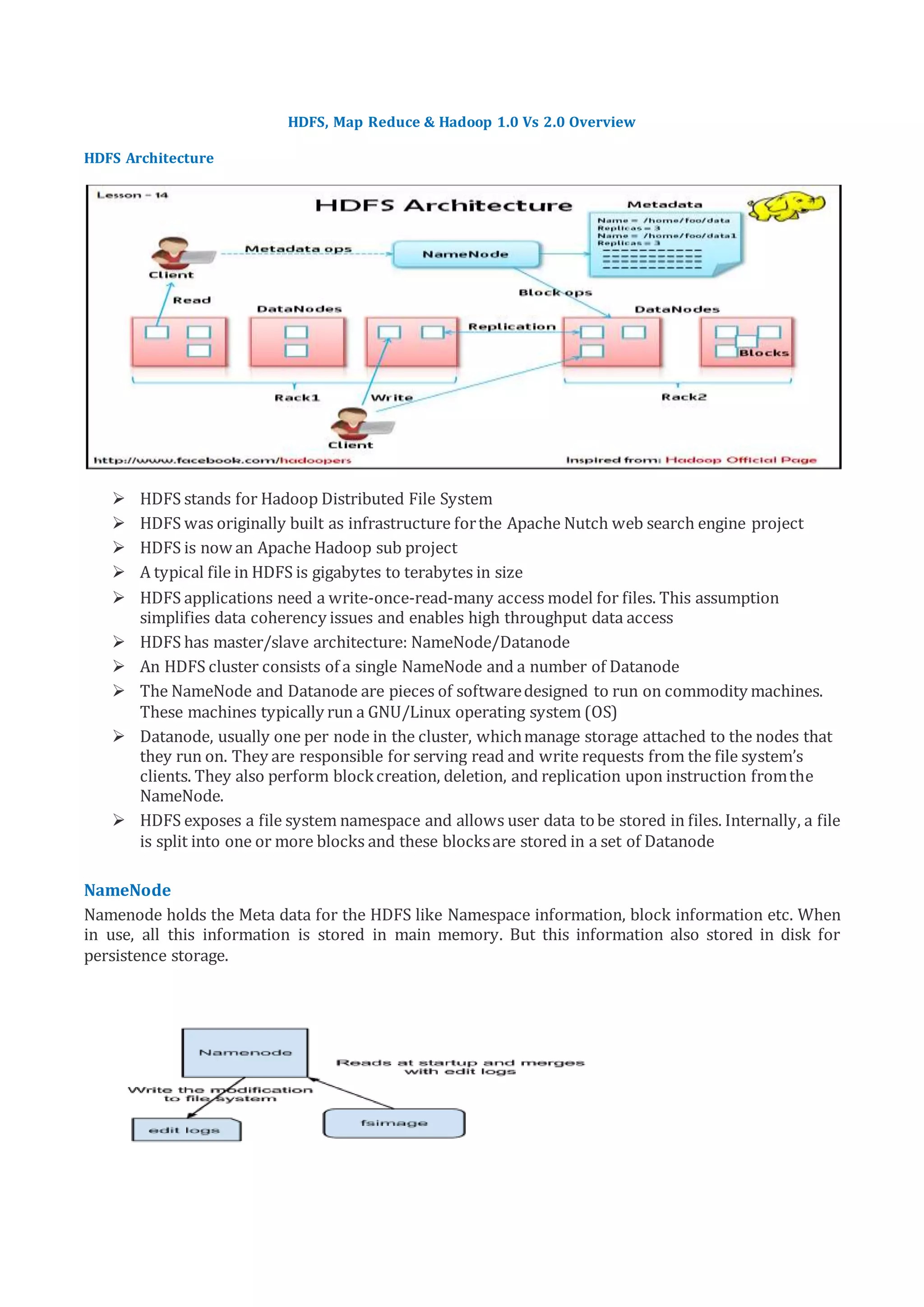


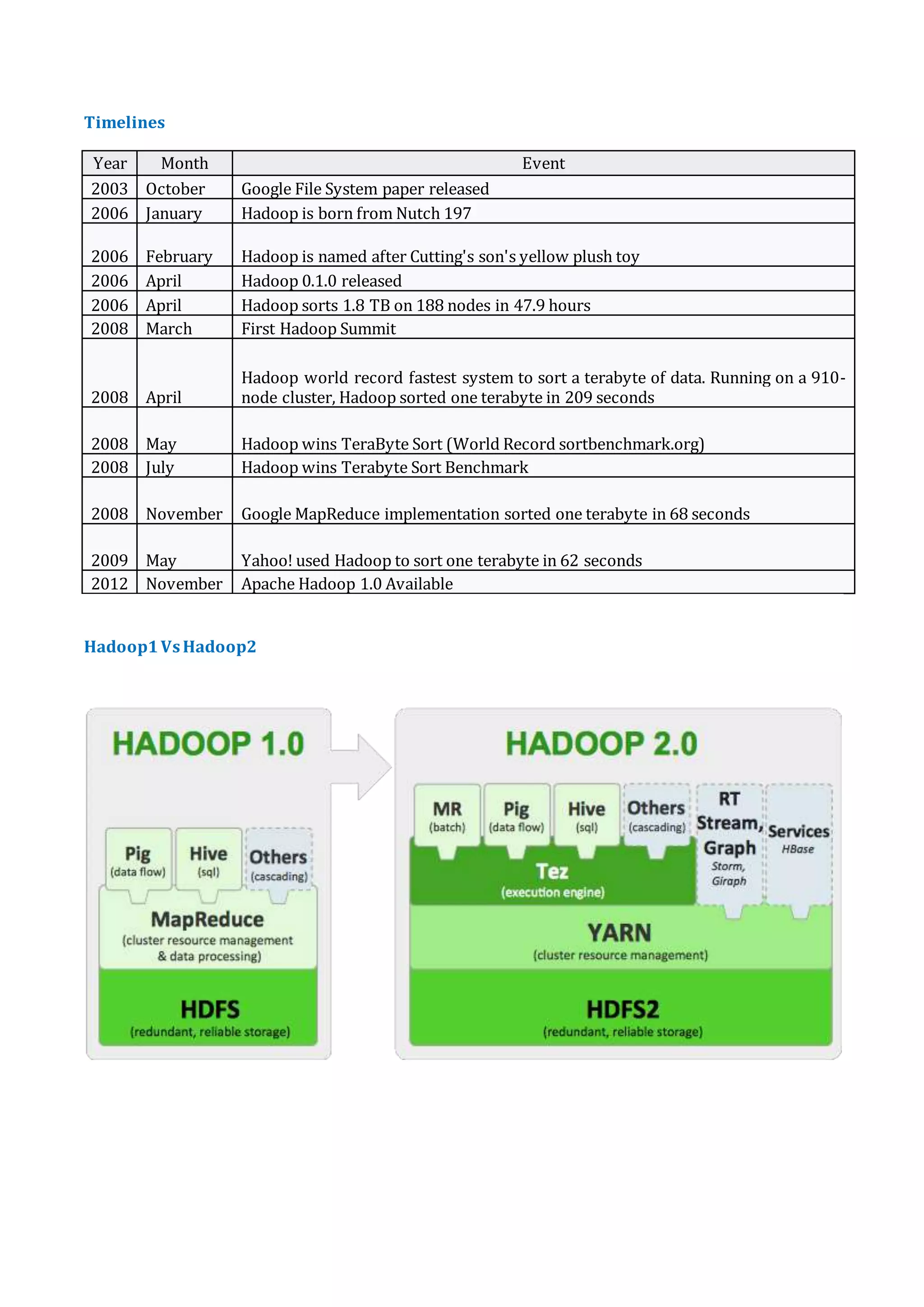
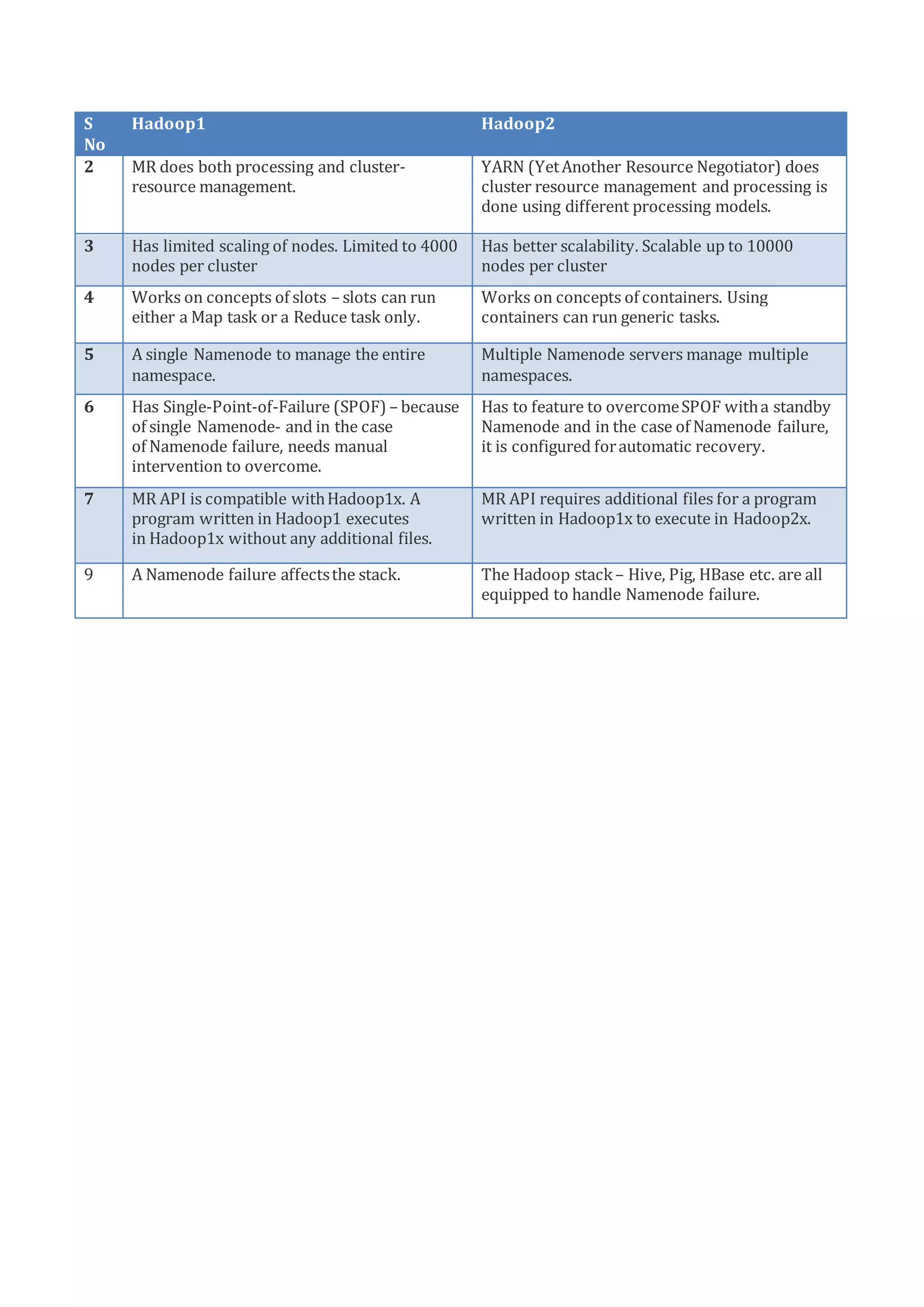

HDFS, MapReduce & Hadoop 1.0 vs 2.0 provides an overview of HDFS architecture, MapReduce framework, and differences between Hadoop 1.0 and 2.0. HDFS uses a master/slave architecture with a NameNode that manages metadata and DataNodes that store data blocks. MapReduce allows processing large datasets in parallel using Map and Reduce functions. Hadoop 2.0 introduced YARN for improved resource management, support for more than 4000 nodes, use of containers instead of slots, multiple NameNodes for high availability, and APIs requiring additional files to run programs from Hadoop 1.x.


































































