Download as PDF, PPTX












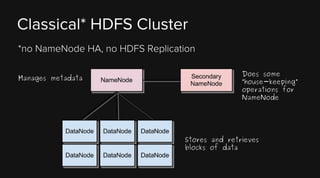



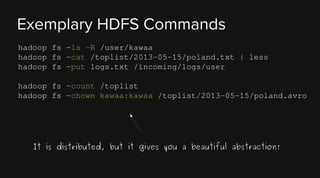





















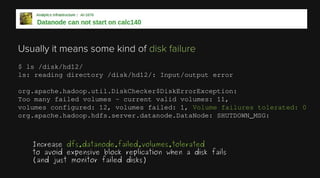
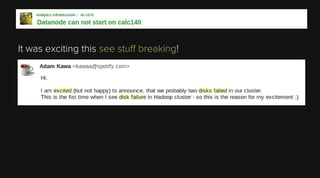



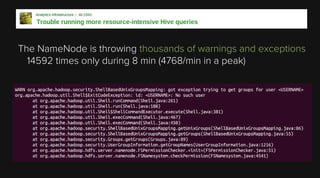
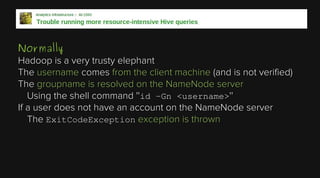



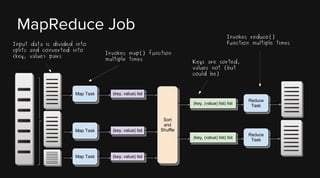
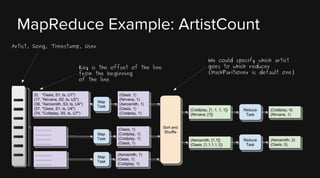
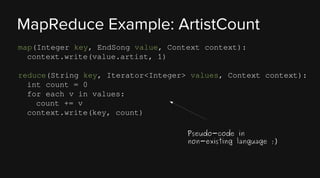
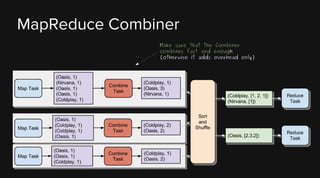
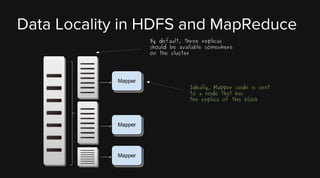

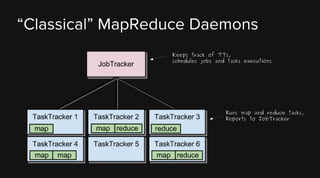


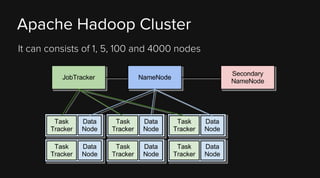
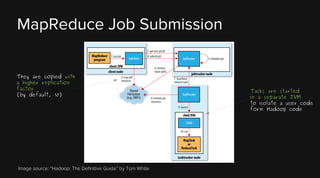
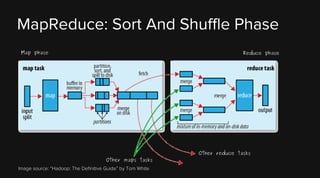










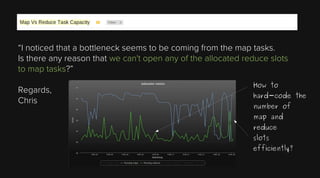
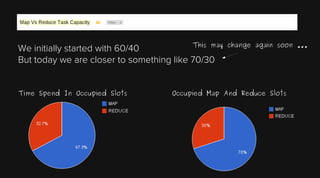
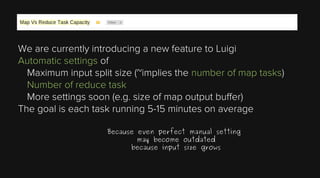















This document provides an overview of Apache Hadoop and its two main components - HDFS and MapReduce. It describes the fundamental ideas behind Hadoop such as storing data reliably across commodity hardware and moving computation to data. It then discusses HDFS in more detail, explaining how it stores very large files reliably through data replication and partitioning files into blocks. It also covers the roles of the NameNode and DataNodes and common HDFS commands. Finally, it discusses some challenges encountered when using HDFS in practice and potential solutions.





































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)









