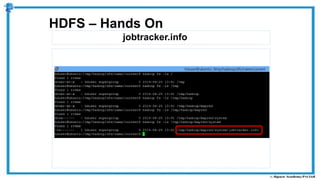
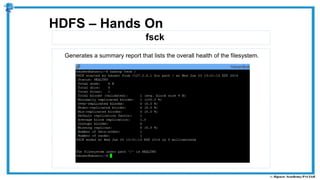
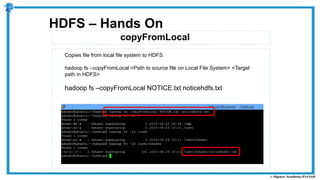
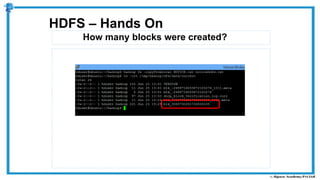
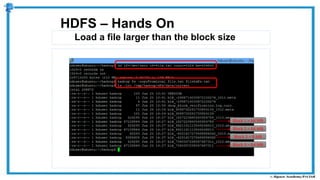
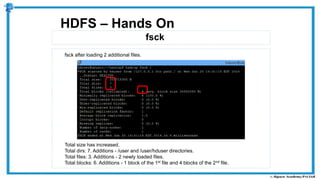
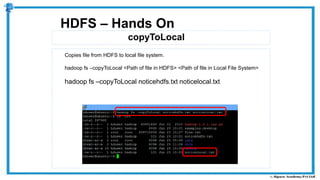
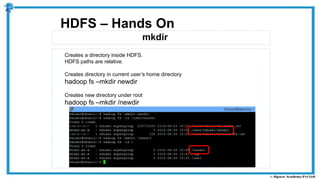
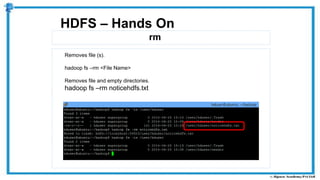
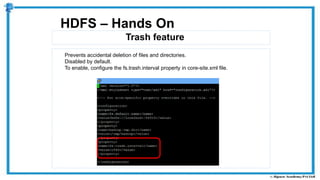
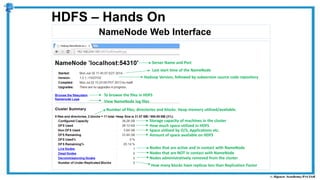
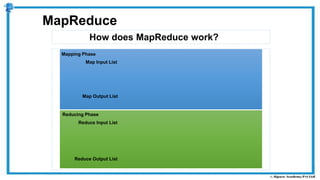
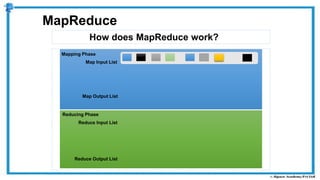
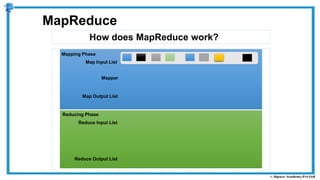
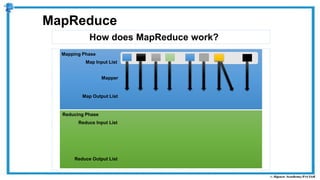
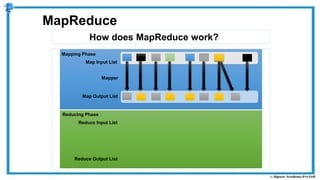
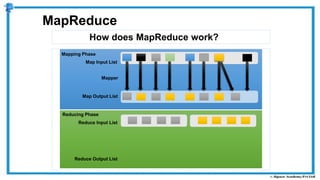
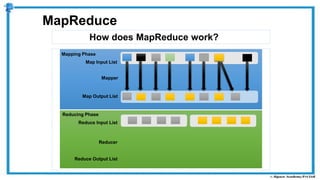
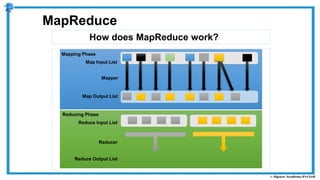
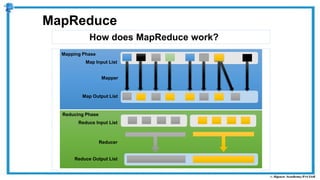
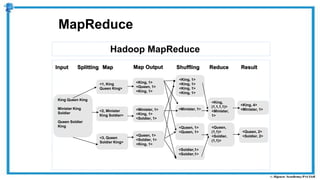
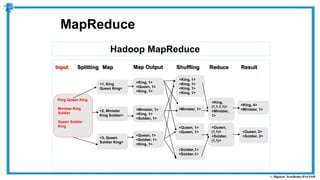
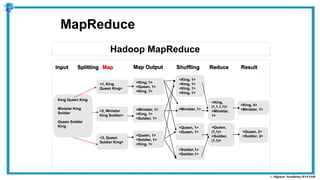
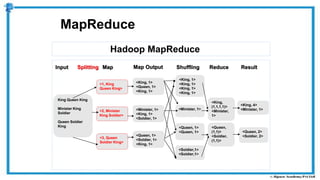
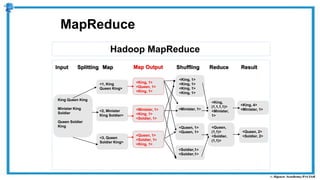
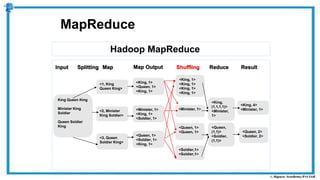
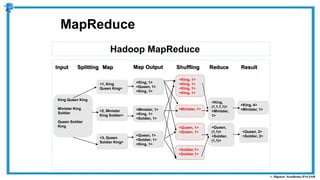
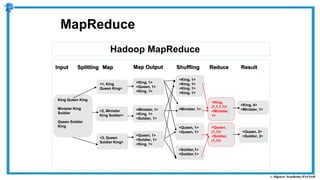
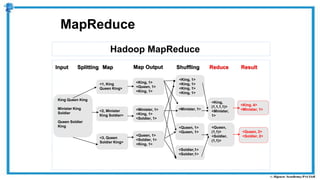
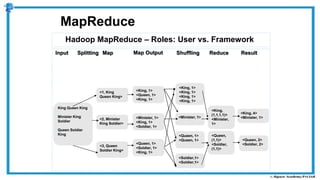
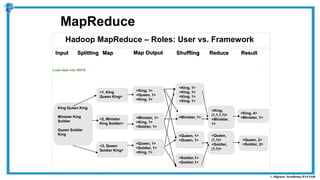
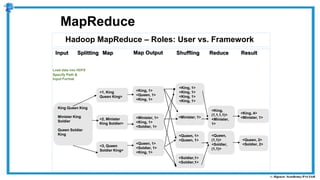
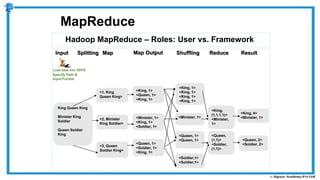
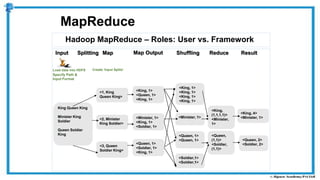
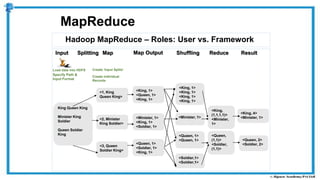
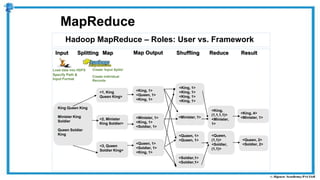
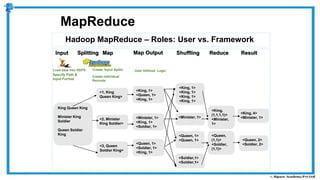
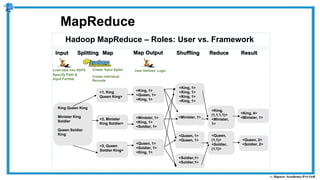
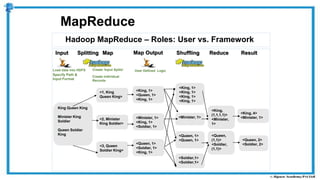
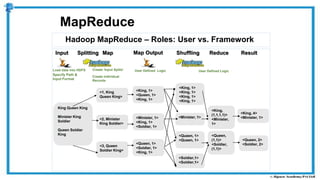
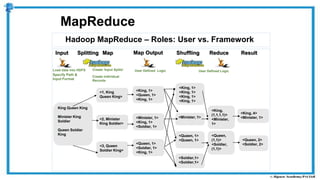
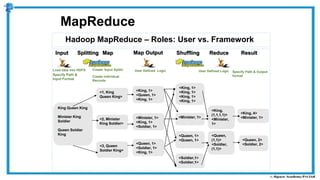
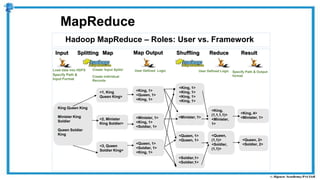
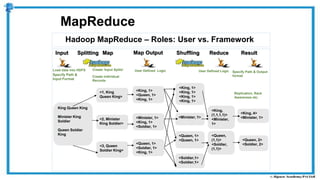
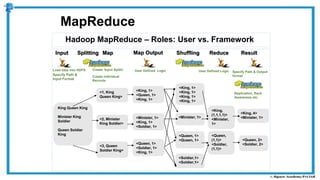
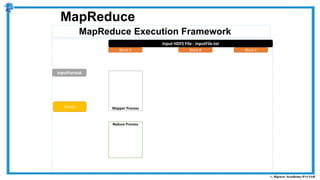
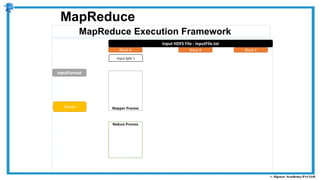
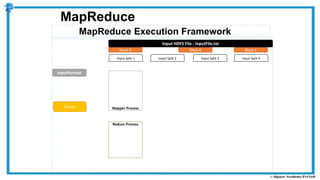
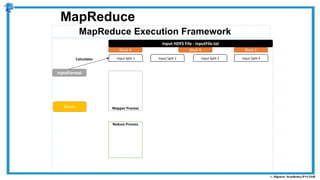
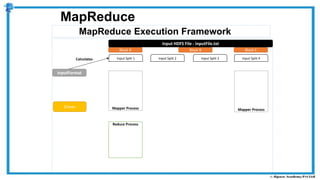
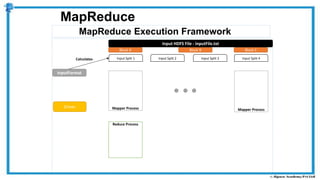
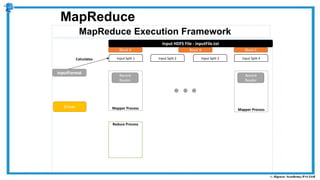
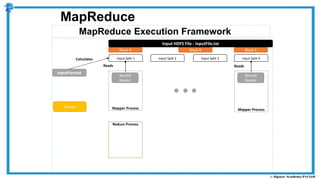
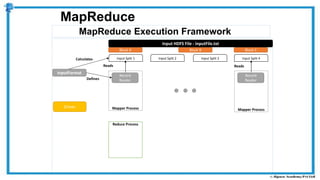
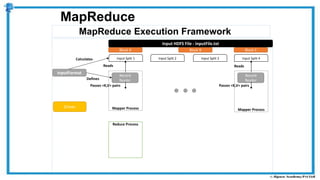
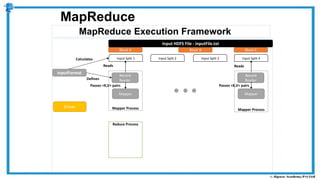
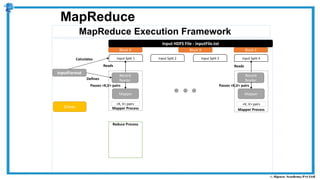
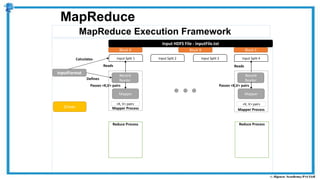
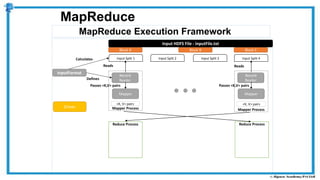
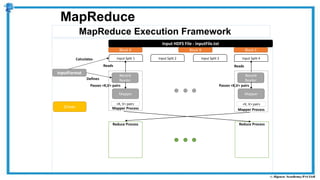
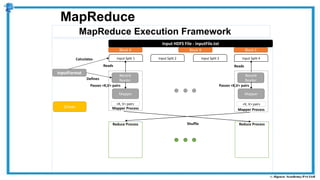
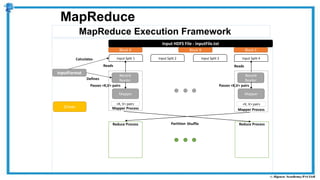
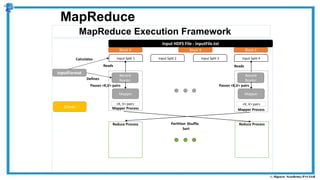
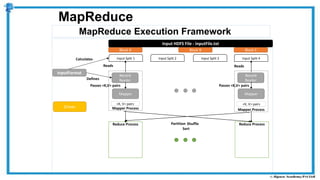
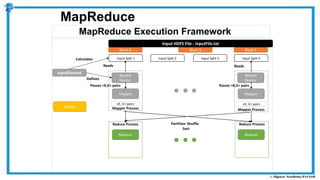
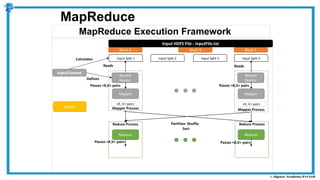
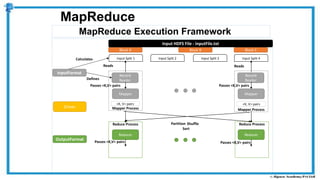
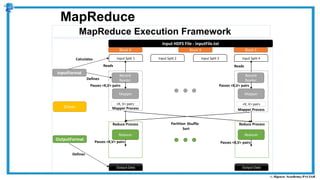
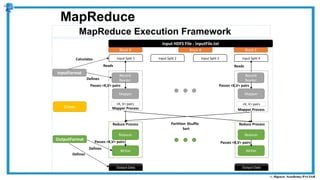
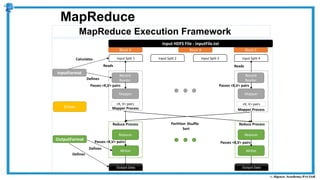
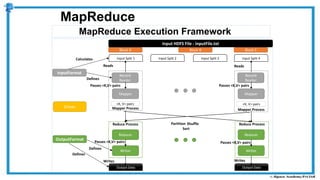
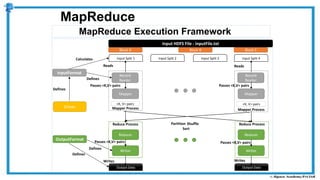
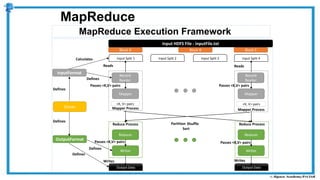
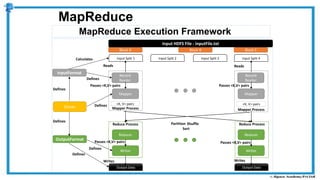
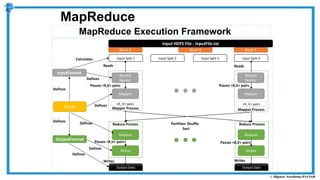
The document provides an overview of how MapReduce works in Hadoop. It explains that MapReduce involves a mapping phase where mappers process input data and emit key-value pairs, and a reducing phase where reducers combine the output from mappers by key and produce the final output. An example of word count using MapReduce is also presented, showing how the input data is split, mapped to count word occurrences, shuffled by key, and reduced to get the final count of each word.