Downloaded 1,062 times











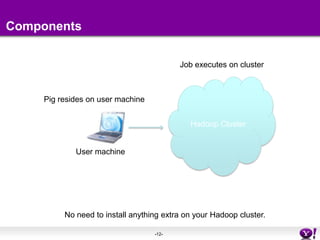
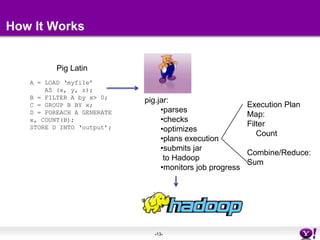




This document introduces Pig, an open source platform for analyzing large datasets that sits on top of Hadoop. It provides an example of using Pig Latin to find the top 5 most visited websites by users aged 18-25 from user and website data. Key points covered include who uses Pig, how it works, performance advantages over MapReduce, and upcoming new features. The document encourages learning more about Pig through online documentation and tutorials.





































































