






















![DataXceiverServer
• Accept data connection & start DataXceiver
– Max num: dfs.datanode.max.xcievers [256]
• DataXceiver
– Handle blocks
• Read block
• Write block
• Replace block
• Copy block
• …
27](https://image.slidesharecdn.com/hadoophdfs-detailedintroduction-130319015949-phpapp01/75/Hadoop-HDFS-Detailed-Introduction-27-2048.jpg)


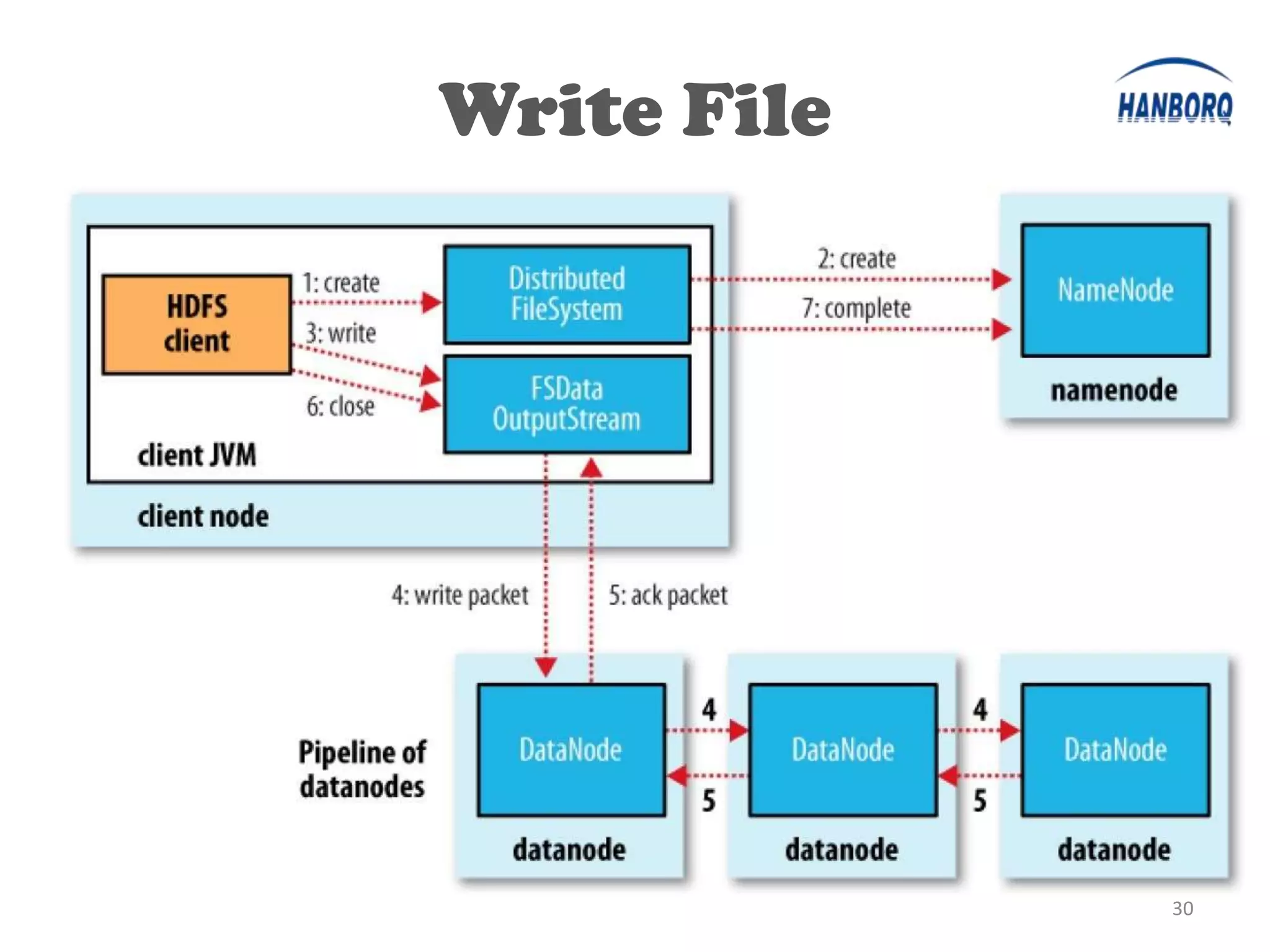








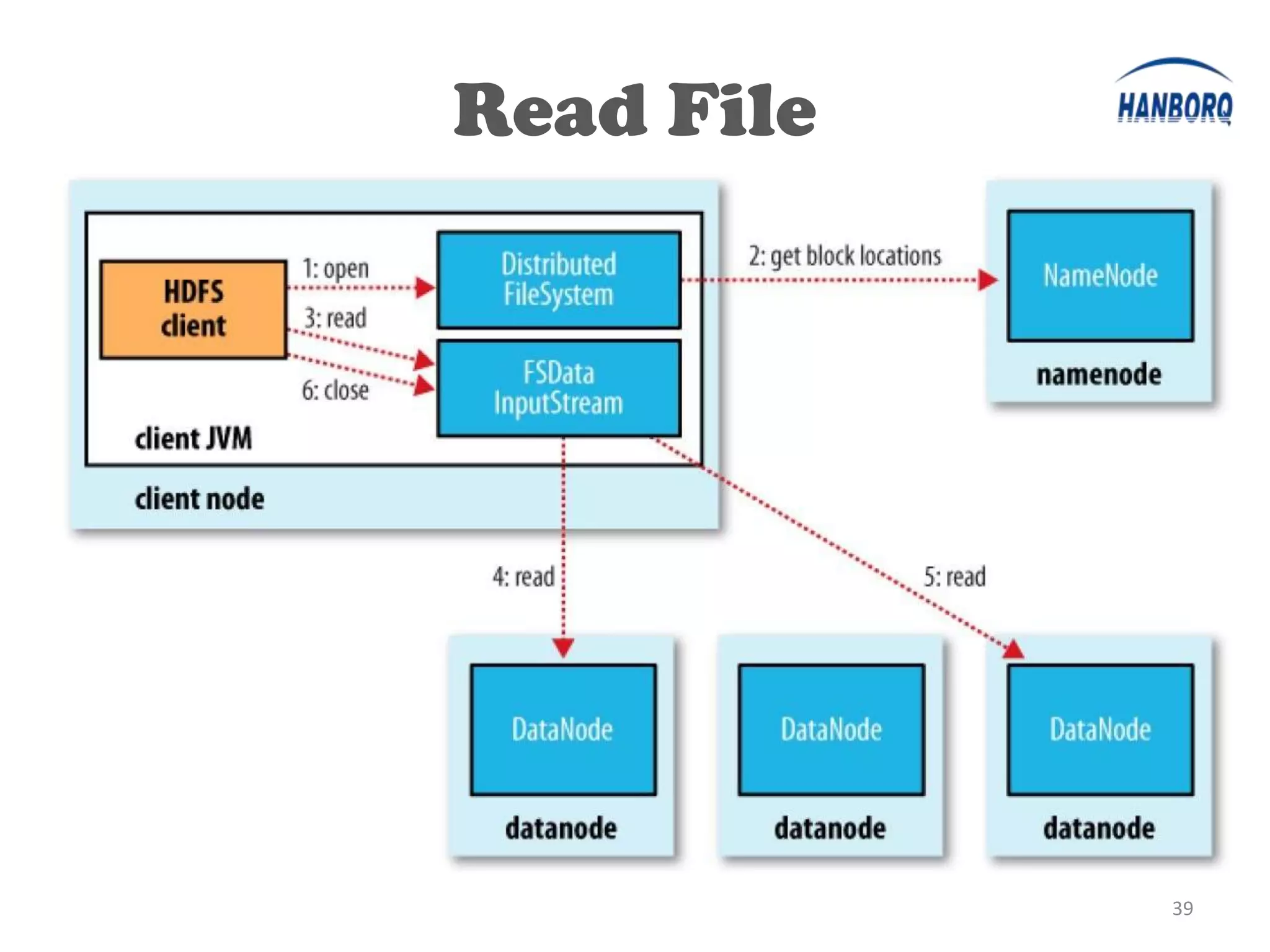


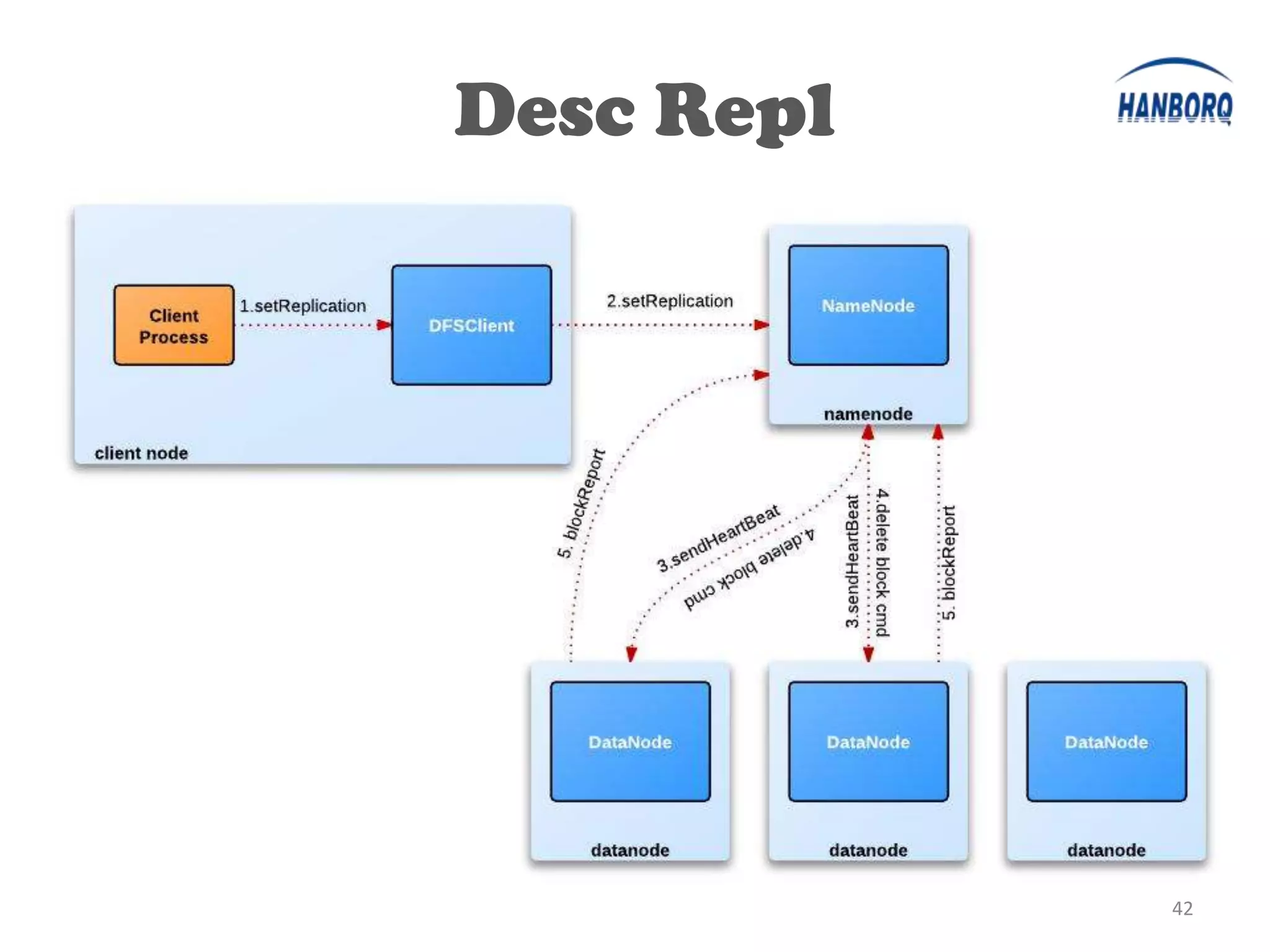









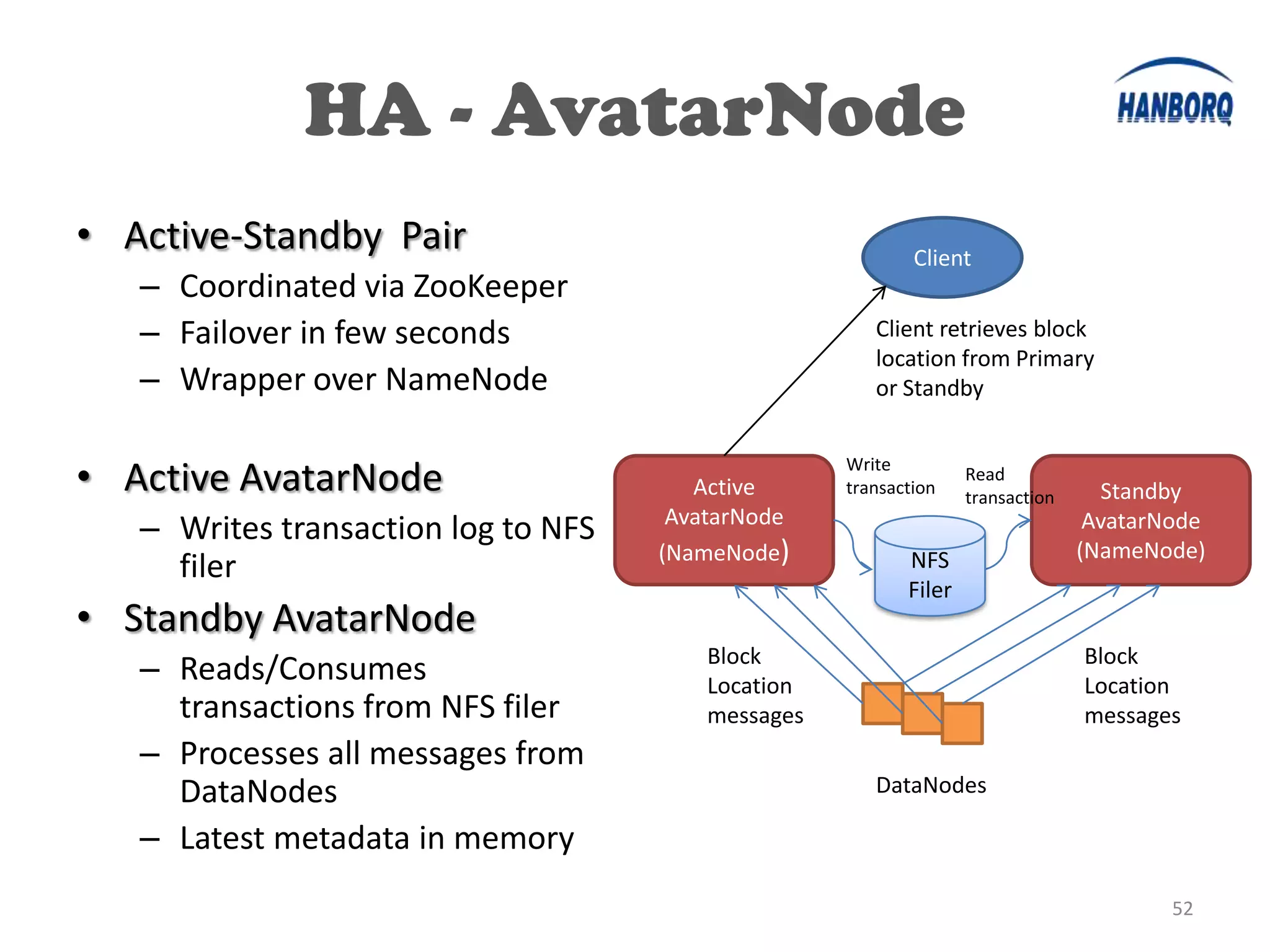

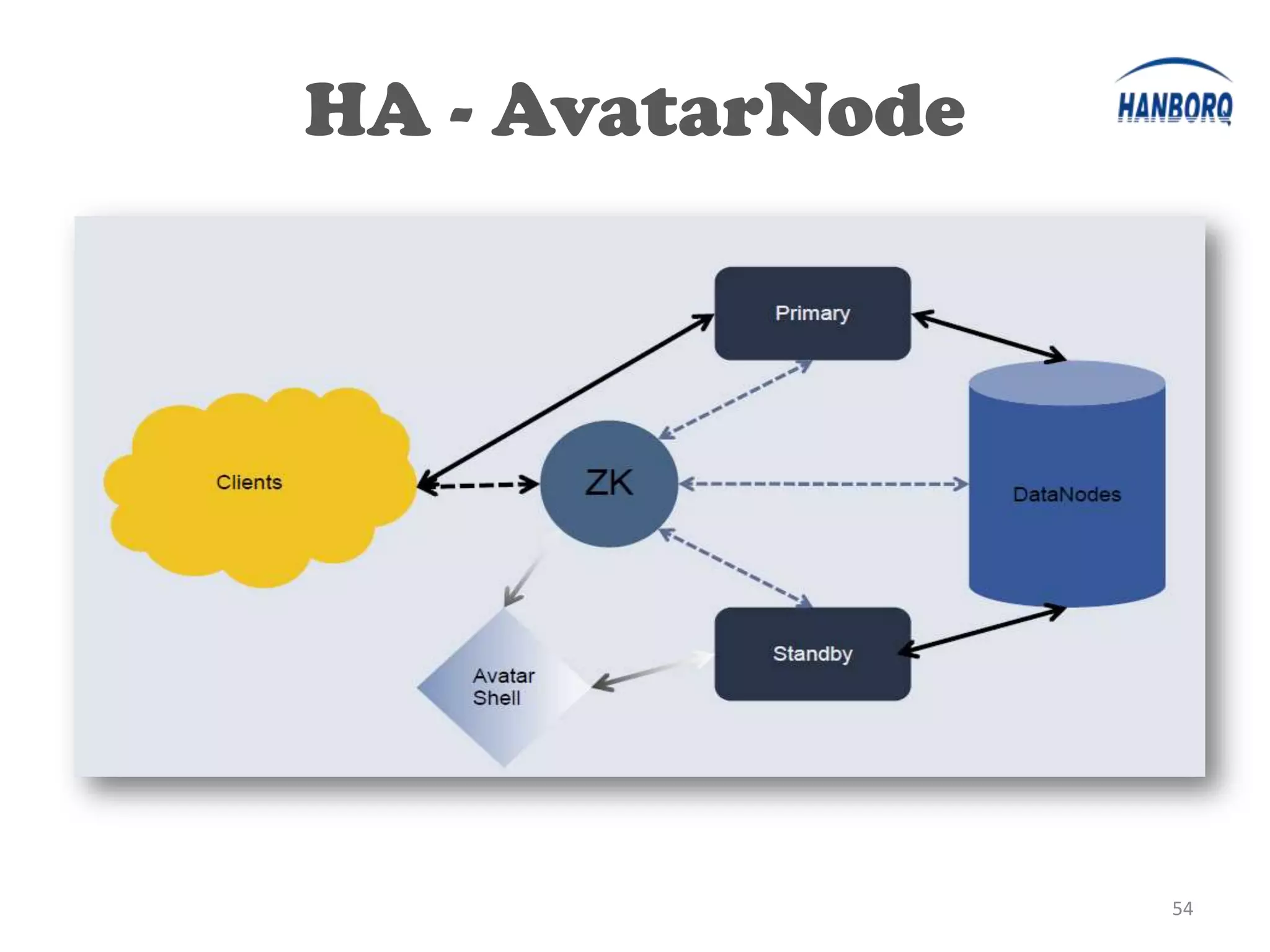










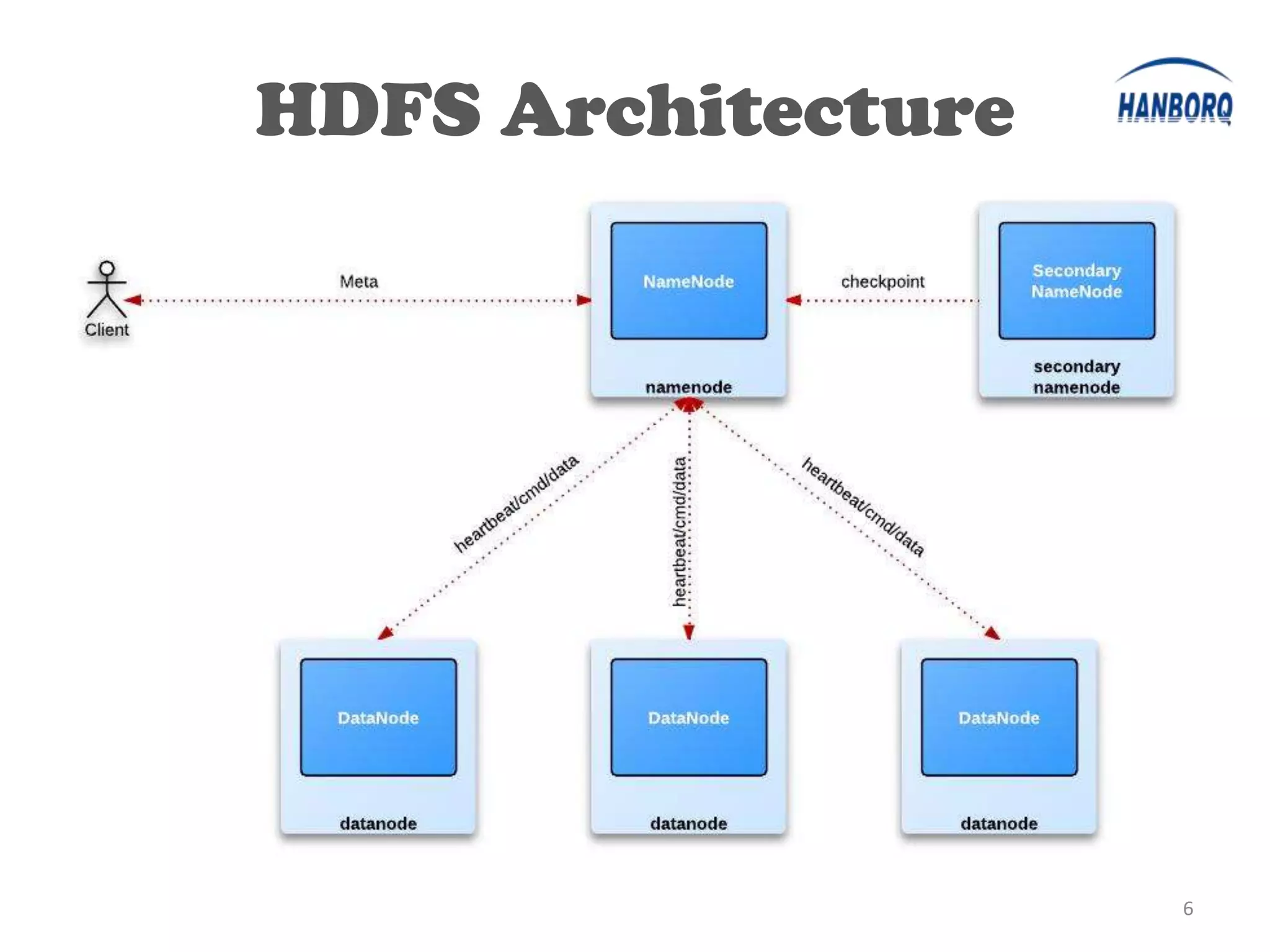
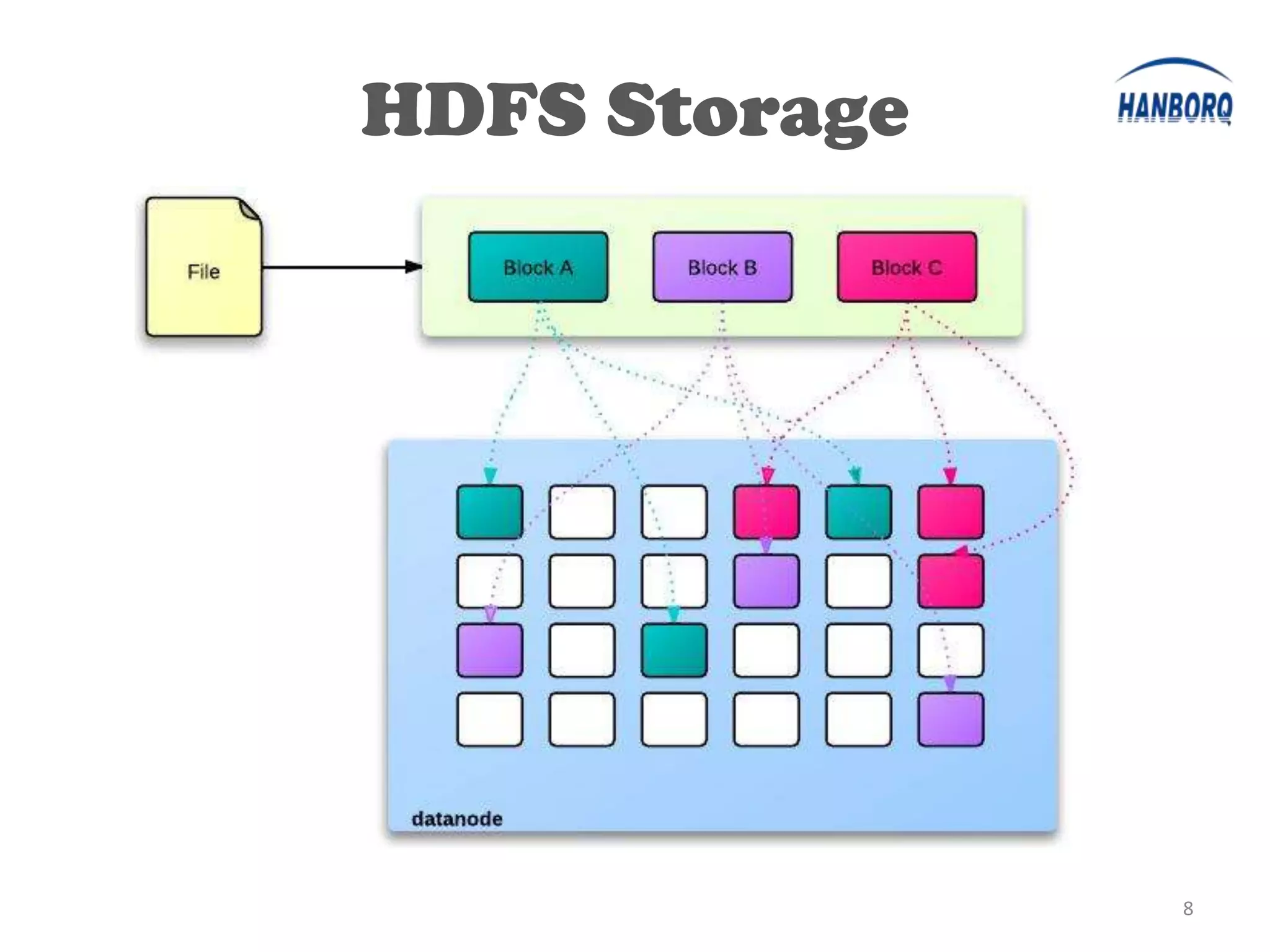
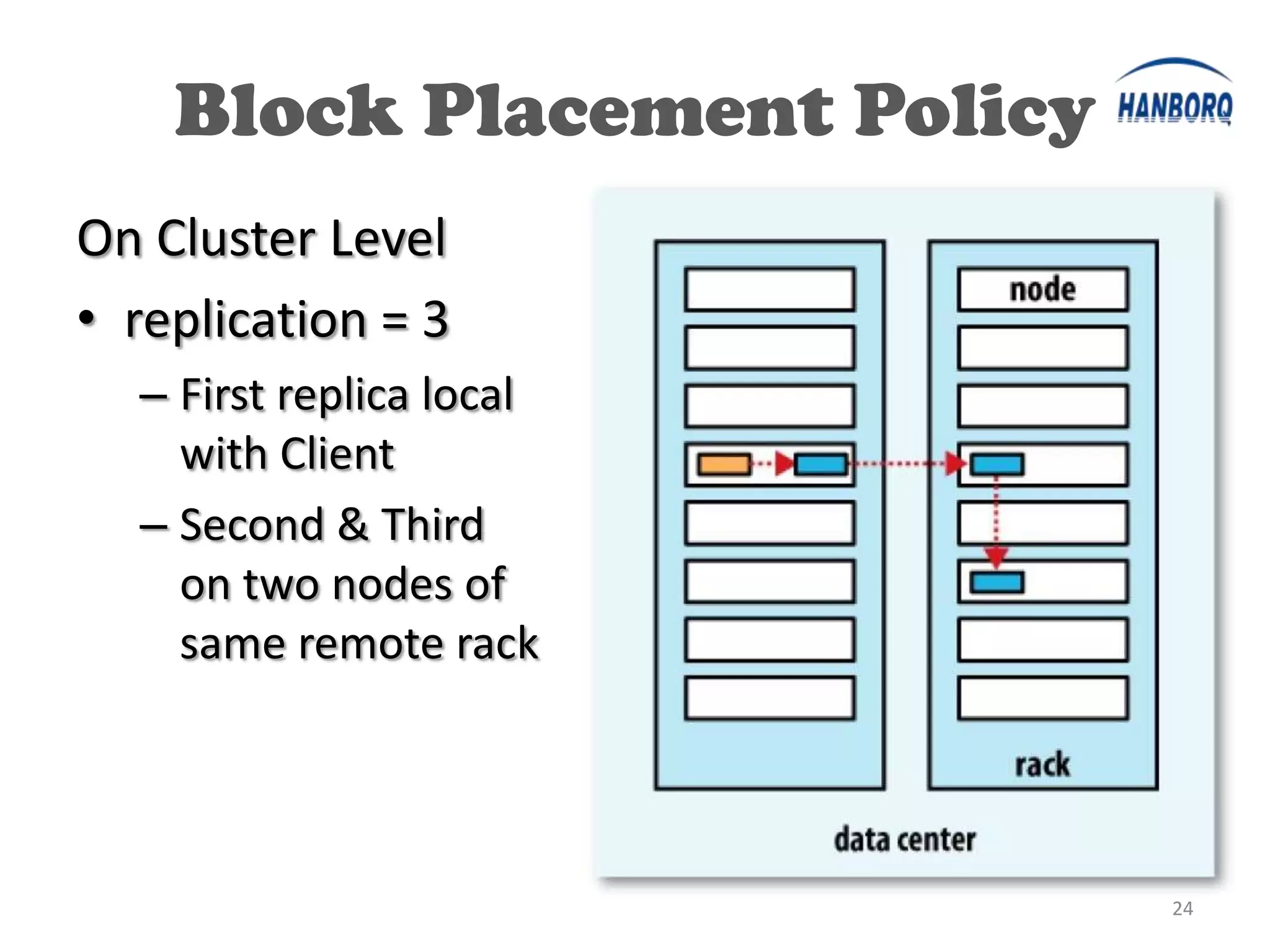
The document provides an overview of the Hadoop Distributed File System (HDFS). It describes HDFS's master-slave architecture with a single NameNode master and multiple DataNode slaves. The NameNode manages filesystem metadata and data placement, while DataNodes store data blocks. The document outlines HDFS components like the SecondaryNameNode, DataNodes, and how files are written and read. It also discusses high availability solutions, operational tools, and the future of HDFS.














































































