




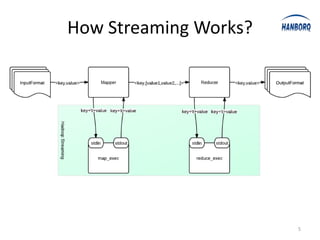


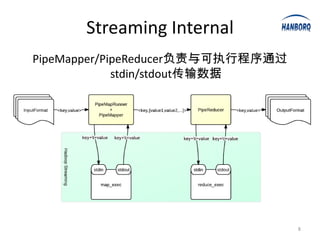


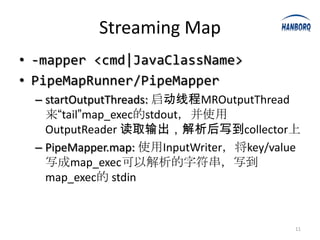



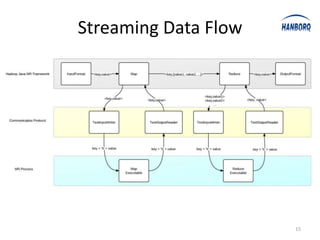












Hadoop Streaming allows any executable or script to be used as a MapReduce job. It works by launching the executable or script as a separate process and communicating with it via stdin and stdout. The executable or script receives key-value pairs in a predefined format and outputs new key-value pairs that are collected. Hadoop Streaming uses PipeMapper and PipeReducer to adapt the external processes to the MapReduce framework. It provides a simple way to run MapReduce jobs without writing Java code.


































































































