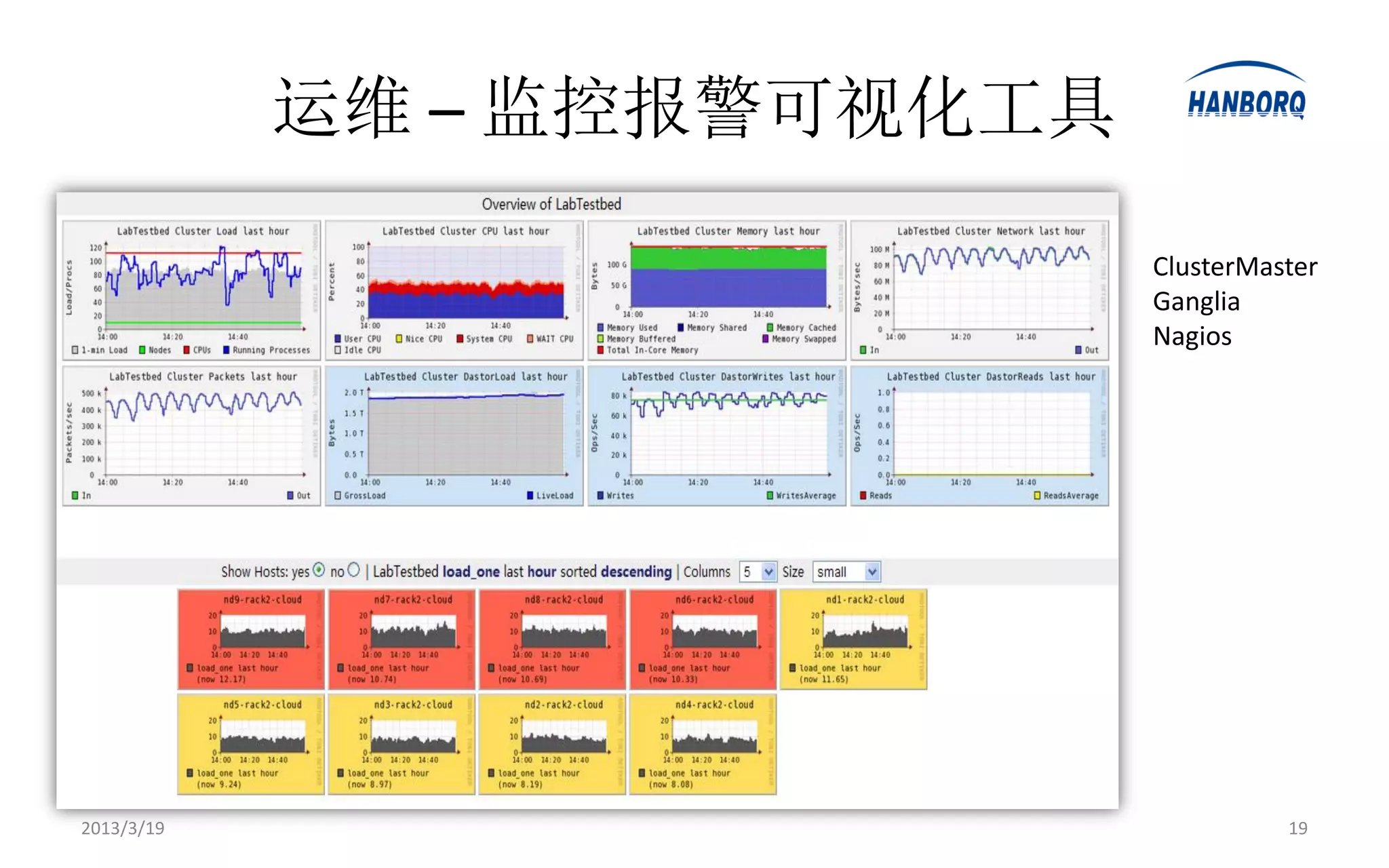
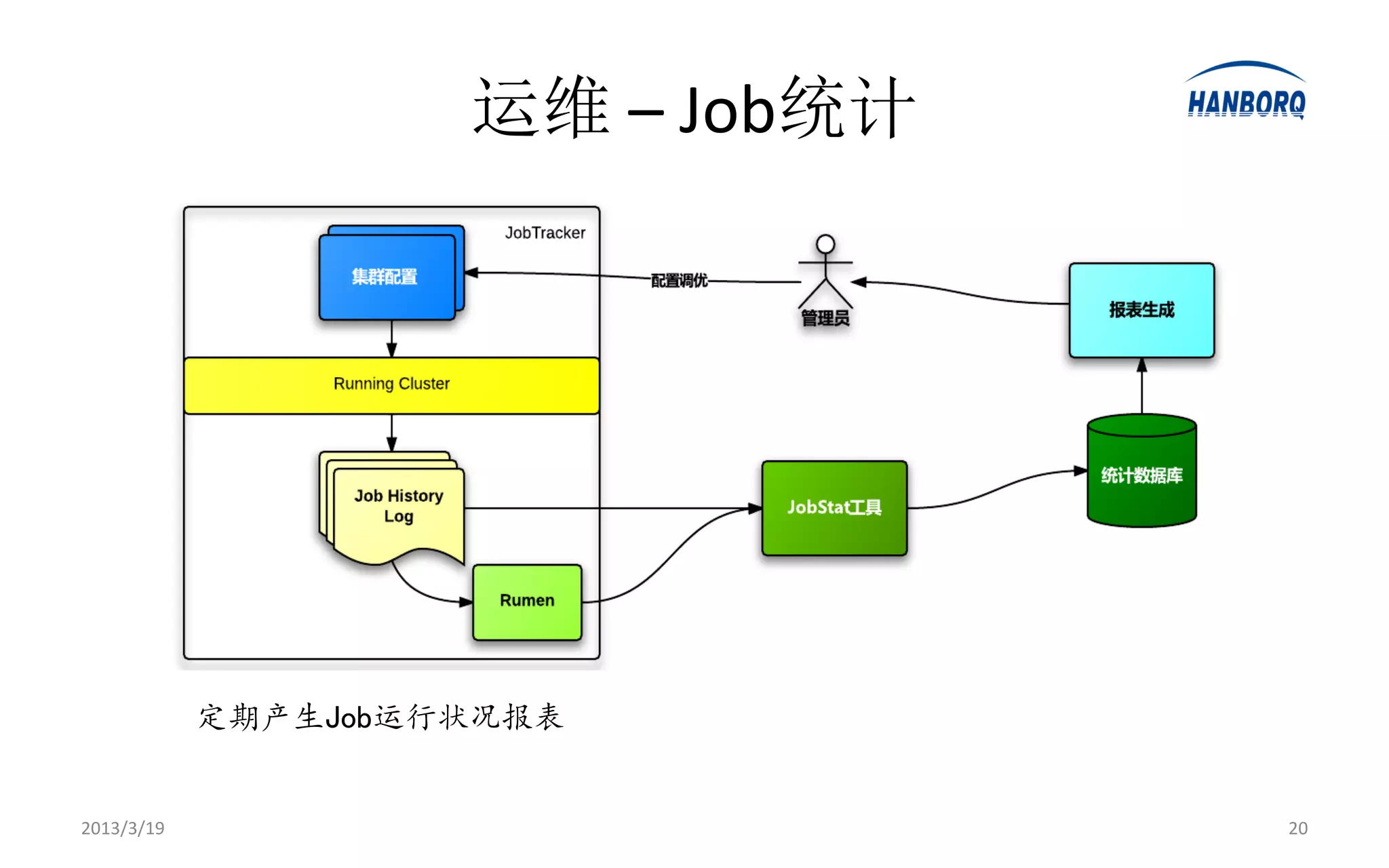
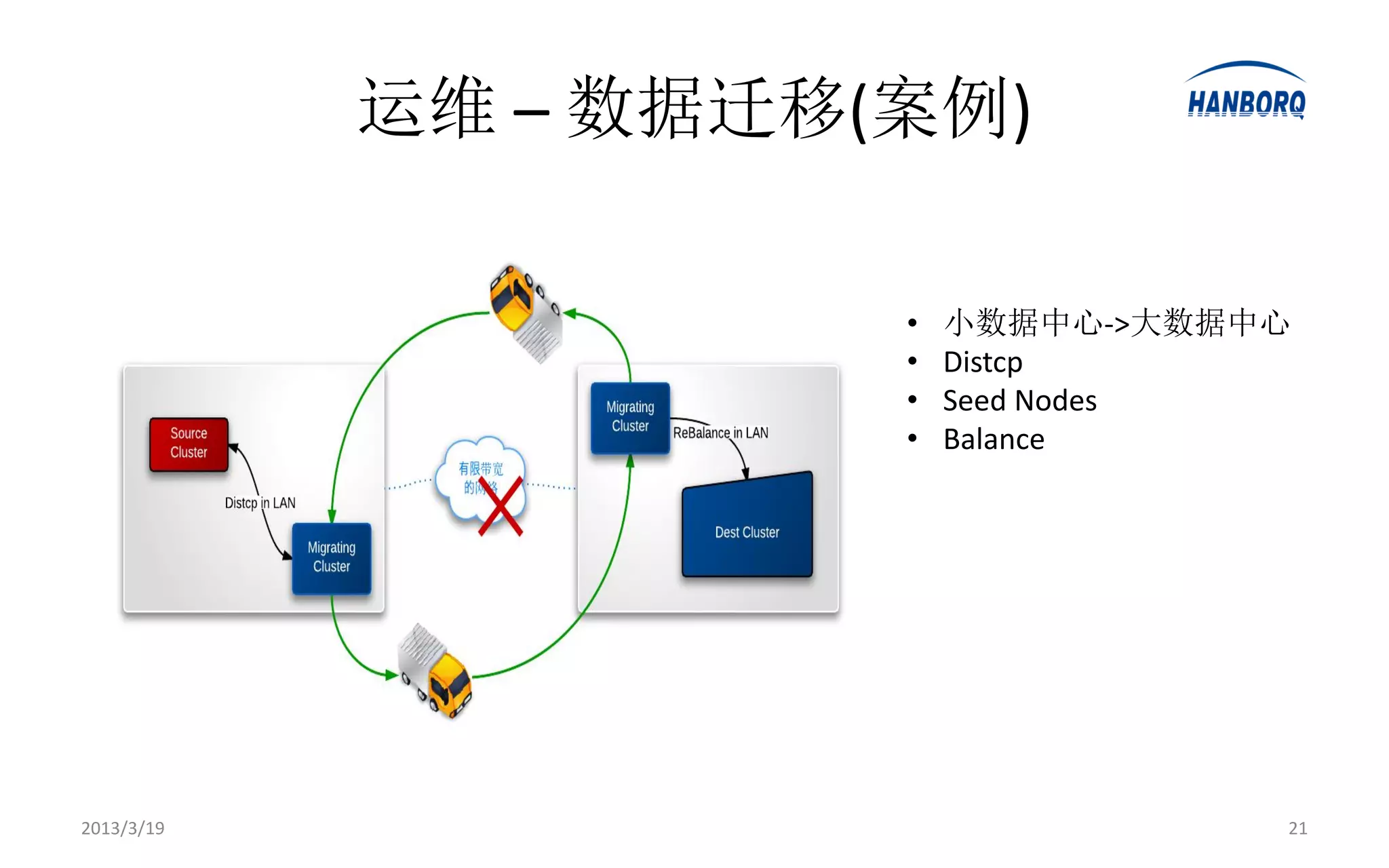
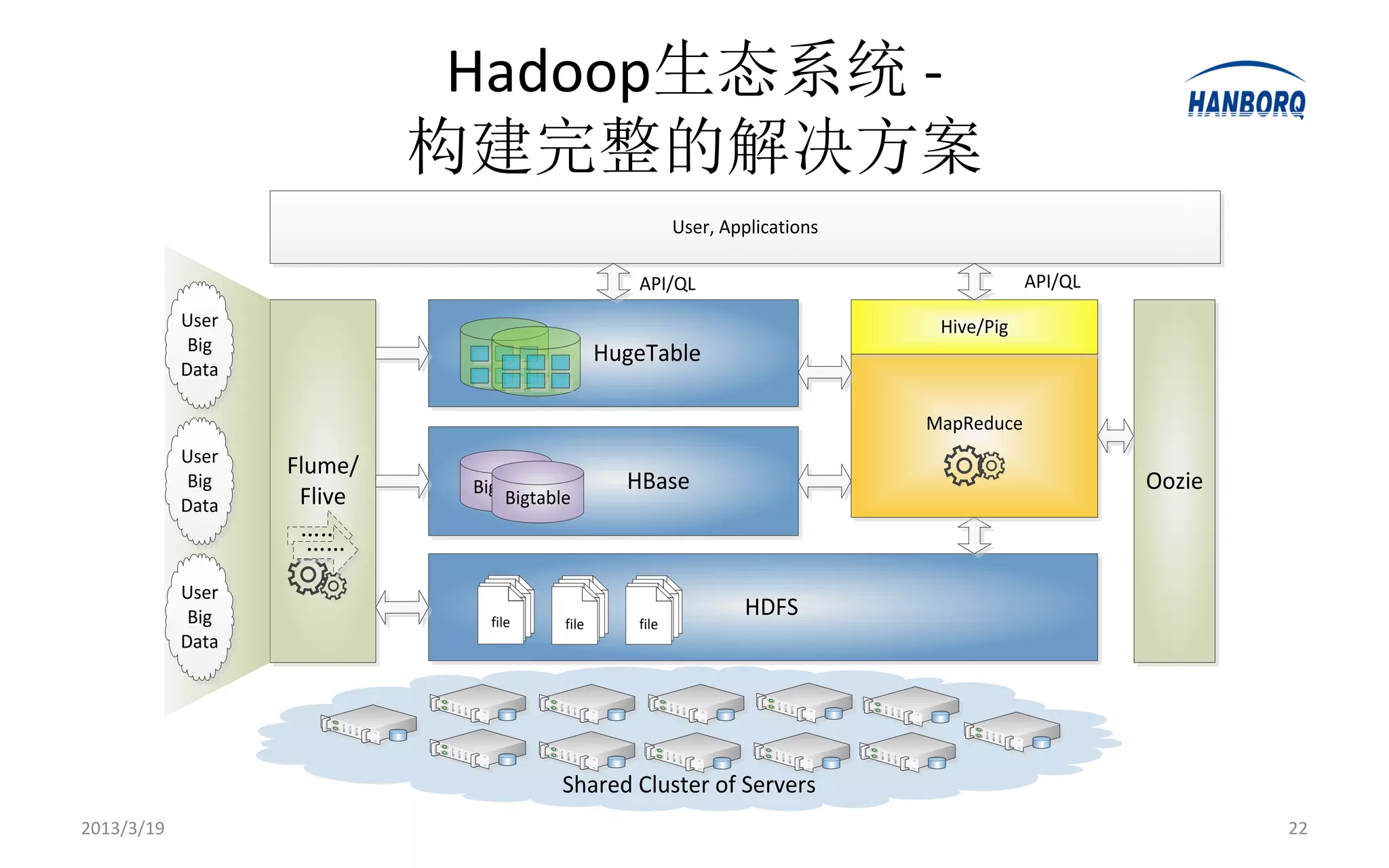
Hadoop生态系统 -
构建完整的解决方案
User, Applications
API/QL API/QL
User Hive/Pig
Big HugeTable
Data
MapReduce
User
Flume/
Big Bigtable HBase Oozie
Data Flive Bigtable
……
……
User
Big file
HDFS
file file
Data
Shared Cluster of Servers
2013/3/19 22
23.
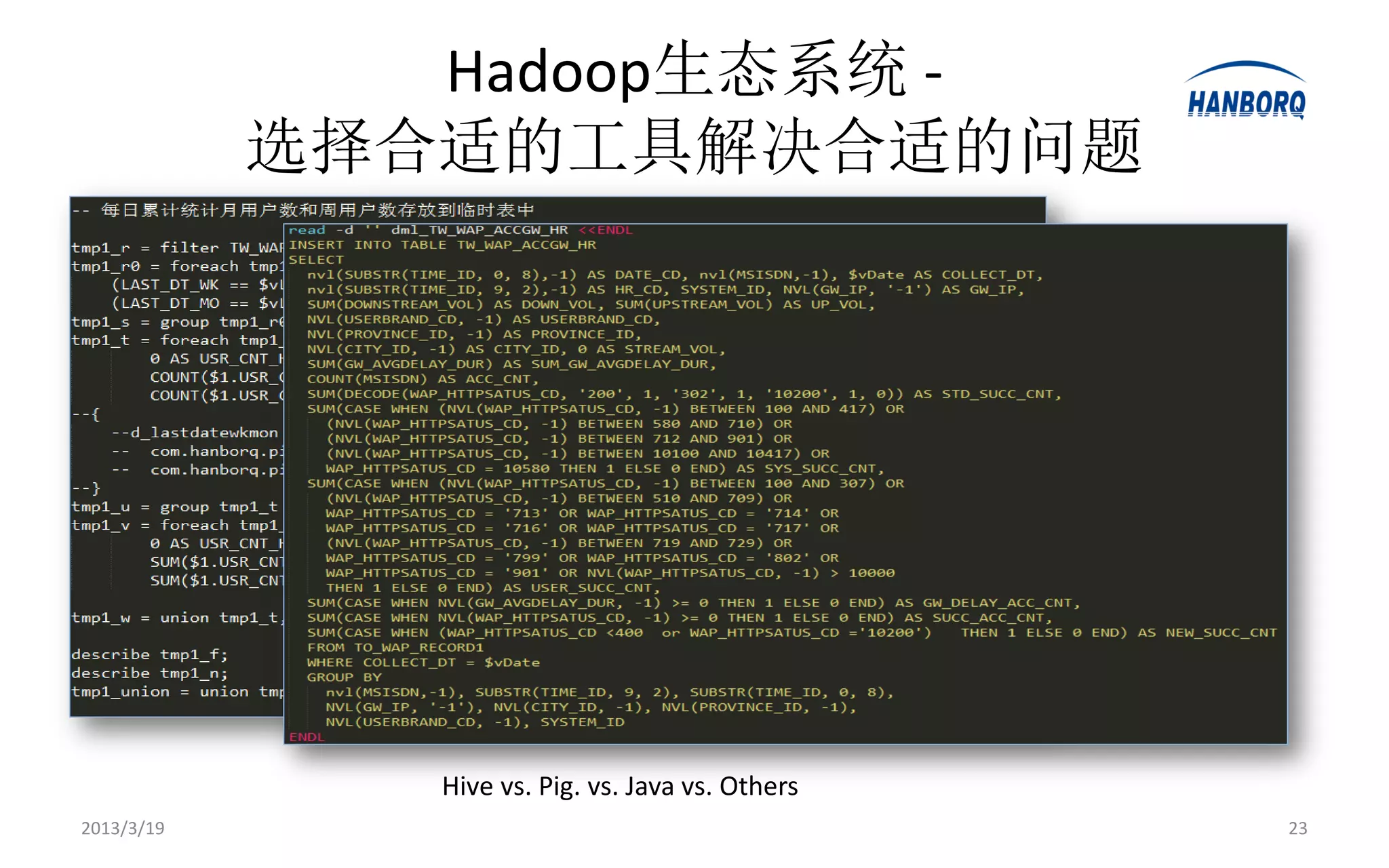
Hadoop生态系统 -
选择合适的工具解决合适的问题
Hive vs. Pig. vs. Java vs. Others
2013/3/19 23