Downloaded 650 times
![1
Hadoop Installation and Running KMeans Clustering
with MapReduce Program on Hadoop
Introduction
General issue that I will cover in this document are Hadoop installation (in section 1) and running
KMeans Clustering MapReduce program on Hadoop (section 2).
1 Hadoop Installation
I will install Hadoop Single Node Cluster mode in my personal computer using this following
environment .
1. Ubuntu 12.04
2. Java JDK 1.7.0 update 21
3. Hadoop 1.2.1 (stable)
1.1 Prerequisites
Before installing Hadoop, the following point must be done first before installing Hadoop in our
system
1. Sun JDK /Open JDK
I use Sun JDK from oracle instead of Open JDK, the resource package can be downloaded from here :
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
2. Hadoop installer packages
In this report, I will use Hadoop version 1.2.1 (stable). The resource package can be downloaded
from her : http://archive.apache.org/dist/hadoop/core/hadoop-1.2.1/
1.1.1 Configuring Java
In my computer, I have several installed java version, they are Java 7 and java 6. For running Hadoop
program, I need to configure which version I will use. I decide to use the newer version (java version
1.7 update 21) so the following are step by step for configuring latest java version.
1. Configure java
$ sudo update-alternatives --config java
There are 2 choices for the alternative java (providing /usr/bin/java).
Selection Path Priority Status
------------------------------------------------------------
0 /usr/lib/jvm/jdk1.6.0_45/bin/java 1 auto mode
1 /usr/lib/jvm/jdk1.6.0_45/bin/java 1 manual mode
* 2 /usr/lib/jvm/jdk1.7.0_21/bin/java 1 manual mode
Press enter to keep the current choice[*], or type selection number: 2](https://image.slidesharecdn.com/hadoopinstallation-kmeansclusteringmapreduce-150109230522-conversion-gate01/75/Hadoop-installation-and-Running-KMeans-Clustering-with-MapReduce-Program-on-Hadoop-1-2048.jpg)
![2
2. configure javac
$ sudo update-alternatives --config javac
There are 2 choices for the alternative javac (providing /usr/bin/javac).
Selection Path Priority Status
------------------------------------------------------------
0 /usr/lib/jvm/jdk1.6.0_45/bin/javac 1 auto mode
1 /usr/lib/jvm/jdk1.6.0_45/bin/javac 1 manual mode
* 2 /usr/lib/jvm/jdk1.7.0_21/bin/javac 1 manual mode
Press enter to keep the current choice[*], or type selection number: 2
3. configure javaws
$ sudo update-alternatives --config javaws
There are 2 choices for the alternative javaws (providing /usr/bin/javaws).
Selection Path Priority Status
------------------------------------------------------------
0 /usr/lib/jvm/jdk1.6.0_45/bin/javaws 1 auto mode
1 /usr/lib/jvm/jdk1.6.0_45/bin/javaws 1 manual mode
* 2 /usr/lib/jvm/jdk1.7.0_21/bin/javaws 1 manual mode
Press enter to keep the current choice[*], or type selection number: 2
4. check the configuration
To make sure the latest java, javac, and javaws successfully configure, I use this following command
tid@dbubuntu:~$ java -version
java version "1.7.0_21"
Java(TM) SE Runtime Environment (build 1.7.0_21-b11)
Java HotSpot(TM) 64-Bit Server VM (build 23.21-b01, mixed mode)
1.1.2 Hadoop installer
After downloading Hadoop installer package, then we need to extract the installer package into the
desire directory. I downloaded Hadoop installer and locate in the ~/Download directory.
For extracting Hadoop installer package in the local directory, I use the following command
$ tar -xzfv hadoop-1.2.1.tar.gz
1.2 System configuration
In this section I will explain step-by step how to setup and preparing the system for Hadoop single
node cluster in my local compute. The system configuration consists of network configuration for
setup the hosts name, move Hadoop extracted package into desire folder, enabling ssh, and adding
and changing folder permission.
1.2.1 Network configuration
In the hadoop network configuration, all of the machines should have alias instead of IP address. To
configure network aliases, we can edit /etc/hosts on machine that will we use for Hadoop
master and slave. In my case, since I am using single node, the configuration can be done by these
step
1. Open file /etc/hosts as sudoers,](https://image.slidesharecdn.com/hadoopinstallation-kmeansclusteringmapreduce-150109230522-conversion-gate01/75/Hadoop-installation-and-Running-KMeans-Clustering-with-MapReduce-Program-on-Hadoop-2-2048.jpg)
![3
$ sudo nano /etc/hosts
2. I add the following lines, inside the curly branch is my IP Address,
127.0.0.1 localhost
164.125.50.127 localhost
Note :
For configuring the local computer into pseudo distributed mode, the following configuration for
/etc/hosts is used
# /etc/hosts (for Hadoop Master and Slave)
192.168.0.1 master
192.168.0.2 slave
1.2.2 User configuration
For security issue, we better to create special user for Hadoop in each machine, however, since I am
working in local computer, I use existing user. The following command is for adding new user and
group
$ sudo addgroup hadoop
$ sudo adduser --ingroup hadoop hduser
1.2.3 Configuring SSH
Hadoop requires SSH access to manage its nodes. In this configuration, I also configure SSH access to
localhost for hduser that I already made in the previous section and local existing user.
1. For generating ssh key for hduser, we can use the following command
$ su - hduser
Password:
hduser@dbubuntu:~$ ssh-keygen -t rsa -P ""
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hduser/.ssh/id_rsa):
/home/hduser/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Your identification has been saved in /home/hduser/.ssh/id_rsa.
Your public key has been saved in /home/hduser/.ssh/id_rsa.pub.
The key fingerprint is:
b8:68:c1:4b:d1:fe:4b:40:2c:1c:b4:37:db:5f:76:ee hduser@dbubuntu
The key's randomart image is:
+--[ RSA 2048]----+
| .o |
| . = |
| = * |
| . * = |
| + = S o . |
| . + + . o o |
| + . o . . |
| . . . . |
| . E |
+-----------------+
hduser@dbubuntu:~$](https://image.slidesharecdn.com/hadoopinstallation-kmeansclusteringmapreduce-150109230522-conversion-gate01/75/Hadoop-installation-and-Running-KMeans-Clustering-with-MapReduce-Program-on-Hadoop-3-2048.jpg)


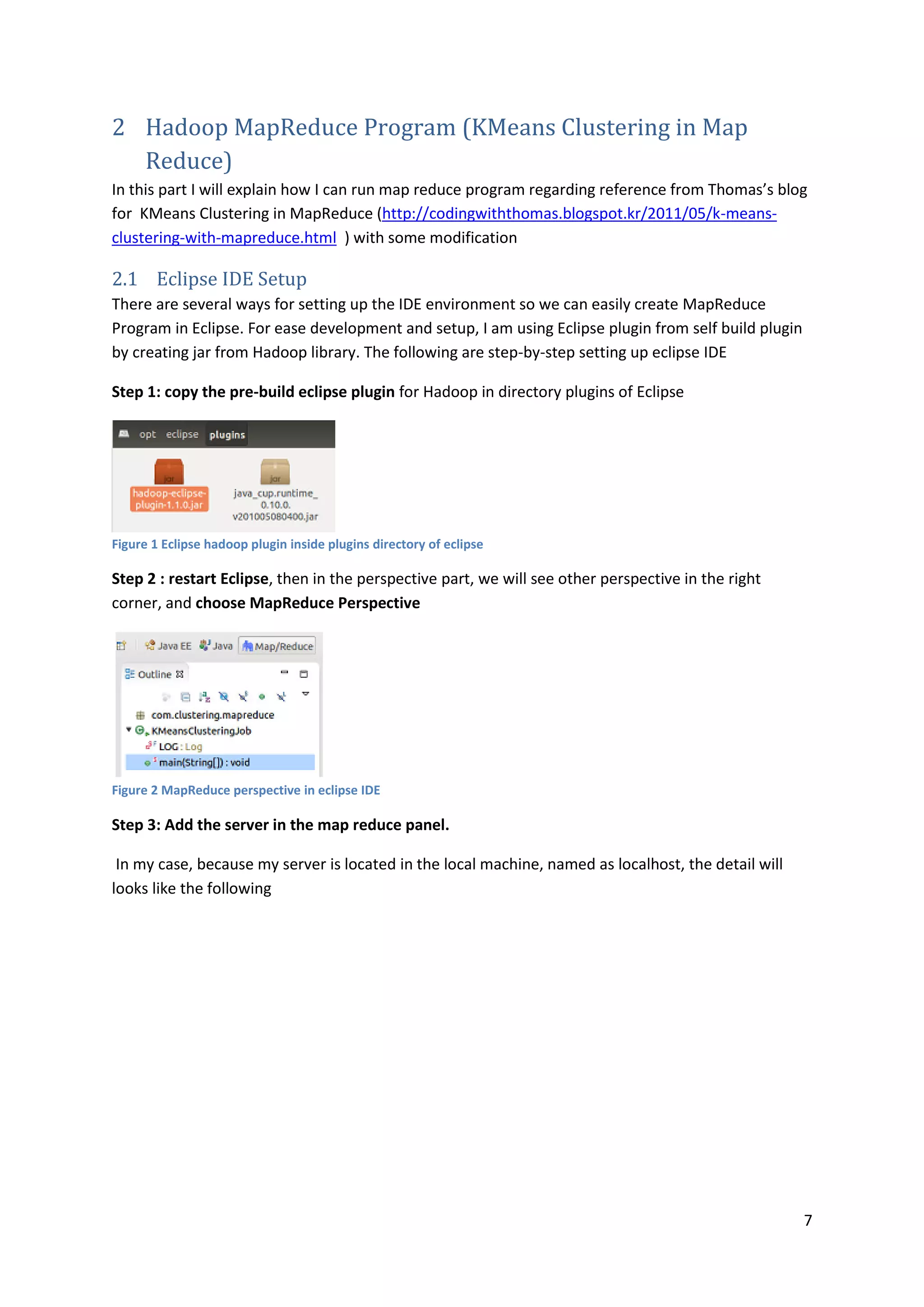
![9
2. Fill the project name, and check the reference location of Hadoop. By default, if we are using
eclipse plugin for Hadoop, the folder will be directed to our Hadoop installation folder , then
click “Finish”
Create Package and Class
For KMeans Clustering MapReduce program, based on Thomas’s references, we need to create two
package, one package for clustering model, consists of Model class for Vector, Distance Measure,
and define the ClusterCenter (Vector.java, DistanceMeasurer.java, and ClusterCenter.java) and the
other is package for Main, Mapper, and Reducer Class (KMeans
1. com.clustering.model package Model Class (Vector.java)
Model Class : Vector.java
package com.clustering.model;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.Arrays;
import org.apache.hadoop.io.WritableComparable;
public class Vector implements WritableComparable<Vector>{
private double[] vector;
public Vector(){
super();
}
public Vector(Vector v){
super();
int l= v.vector.length;
this.vector= new double[l];
System.arraycopy(v.vector, 0,this.vector, 0, l);](https://image.slidesharecdn.com/hadoopinstallation-kmeansclusteringmapreduce-150109230522-conversion-gate01/75/Hadoop-installation-and-Running-KMeans-Clustering-with-MapReduce-Program-on-Hadoop-9-2048.jpg)
![10
}
public Vector(double x, double y){
super();
this.vector = new double []{x,y};
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
int size = in.readInt();
vector = new double[size];
for(int i=0;i<size;i++)
vector[i]=in.readDouble();
}
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeInt(vector.length);
for(int i=0;i<vector.length;i++)
out.writeDouble(vector[i]);
}
@Override
public int compareTo(Vector o) {
// TODO Auto-generated method stub
boolean equals = true;
for (int i=0;i<vector.length;i++){
if (vector[i] != o.vector[i]) {
equals = false;
break;
}
}
if(equals)
return 0;
else
return 1;
}
public double[] getVector(){
return vector;
}
public void setVector(double[]vector){
this.vector=vector;
}
public String toString(){
return "Vector [vector=" + Arrays.toString(vector) + "]";
}
}
2. Distance Measurement Class
Distance Measurement class : DistanceMeasurer.java
package com.clustering.model;](https://image.slidesharecdn.com/hadoopinstallation-kmeansclusteringmapreduce-150109230522-conversion-gate01/75/Hadoop-installation-and-Running-KMeans-Clustering-with-MapReduce-Program-on-Hadoop-10-2048.jpg)
![11
public class DistanceMeasurer {
public static final double measureDistance(ClusterCenter center,
Vector v) {
double sum = 0;
int length = v.getVector().length;
for (int i = 0; i < length; i++) {
sum += Math.abs(center.getCenter().getVector()[i]
- v.getVector()[i]);
}
return sum;
}
}
3. ClusterCenter
Cluster Center definition : ClusterCenter.java
package com.clustering.model;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class ClusterCenter implements WritableComparable<ClusterCenter> {
private Vector center;
public ClusterCenter() {
super();
this.center = null;
}
public ClusterCenter(ClusterCenter center) {
super();
this.center = new Vector(center.center);
}
public ClusterCenter(Vector center) {
super();
this.center = center;
}
public boolean converged(ClusterCenter c) {
return compareTo(c) == 0 ? false : true;
}
@Override
public void write(DataOutput out) throws IOException {
center.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
this.center = new Vector();
center.readFields(in);
}](https://image.slidesharecdn.com/hadoopinstallation-kmeansclusteringmapreduce-150109230522-conversion-gate01/75/Hadoop-installation-and-Running-KMeans-Clustering-with-MapReduce-Program-on-Hadoop-11-2048.jpg)
![12
@Override
public int compareTo(ClusterCenter o) {
return center.compareTo(o.getCenter());
}
/**
* @return the center
*/
public Vector getCenter() {
return center;
}
@Override
public String toString() {
return "ClusterCenter [center=" + center + "]";
}
}
After configuring the class model, the next one is MapReduce Classes, which consist of Mapper,
Reducer, and finally the Main class
1. Mapper class
Mapper class : KMeansMapper.java
package com.clustering.mapreduce;
import java.io.IOException;
import java.util.LinkedList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.mapreduce.Mapper;
import com.clustering.model.ClusterCenter;
import com.clustering.model.DistanceMeasurer;
import com.clustering.model.Vector;
public class KMeansMapper extends
Mapper<ClusterCenter, Vector, ClusterCenter, Vector>{
List<ClusterCenter> centers = new LinkedList<ClusterCenter>();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
super.setup(context);
Configuration conf = context.getConfiguration();
Path centroids = new Path(conf.get("centroid.path"));
FileSystem fs = FileSystem.get(conf);
SequenceFile.Reader reader = new SequenceFile.Reader(fs,
centroids,
conf);](https://image.slidesharecdn.com/hadoopinstallation-kmeansclusteringmapreduce-150109230522-conversion-gate01/75/Hadoop-installation-and-Running-KMeans-Clustering-with-MapReduce-Program-on-Hadoop-12-2048.jpg)

![14
protected void reduce(ClusterCenter key, Iterable<Vector> values,
Context context) throws IOException,
InterruptedException{
Vector newCenter = new Vector();
List<Vector> vectorList = new LinkedList<Vector>();
int vectorSize = key.getCenter().getVector().length;
newCenter.setVector(new double[vectorSize]);
for(Vector value :values){
vectorList.add(new Vector(value));
for(int i=0;i<value.getVector().length;i++){
newCenter.getVector()[i]+=value.getVector()[i];
}
}
for(int i=0;i<newCenter.getVector().length;i++){
newCenter.getVector()[i] =
newCenter.getVector()[i]/vectorList.size();
}
ClusterCenter center = new ClusterCenter(newCenter);
centers.add(center);
for(Vector vector:vectorList){
context.write(center, vector);
}
if(center.converged(key))
context.getCounter(Counter.CONVERGED).increment(1);
}
protected void cleanup(Context context) throws
IOException,InterruptedException{
super.cleanup(context);
Configuration conf = context.getConfiguration();
Path outPath = new Path(conf.get("centroid.path"));
FileSystem fs = FileSystem.get(conf);
fs.delete(outPath,true);
final SequenceFile.Writer out = SequenceFile.createWriter(fs,
context.getConfiguration(),
outPath, ClusterCenter.class, IntWritable.class);
final IntWritable value = new IntWritable(0);
for(ClusterCenter center:centers){
out.append(center, value);
}
out.close();
}
}](https://image.slidesharecdn.com/hadoopinstallation-kmeansclusteringmapreduce-150109230522-conversion-gate01/75/Hadoop-installation-and-Running-KMeans-Clustering-with-MapReduce-Program-on-Hadoop-14-2048.jpg)
![15
3. Main class
Main class : KMeansClusteringJob.java
package com.clustering.mapreduce;
import java.io.IOException;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import com.clustering.model.ClusterCenter;
import com.clustering.model.Vector;
public class KMeansClusteringJob {
private static final Log LOG =
LogFactory.getLog(KMeansClusteringJob.class);
public static void main(String[] args) throws IOException,
InterruptedException, ClassNotFoundException {
int iteration = 1;
Configuration conf = new Configuration();
conf.set("num.iteration", iteration + "");
Path in = new Path("files/clustering/import/data");
Path center = new
Path("files/clustering/import/center/cen.seq");
conf.set("centroid.path", center.toString());
Path out = new Path("files/clustering/depth_1");
Job job = new Job(conf);
job.setJobName("KMeans Clustering");
job.setMapperClass(KMeansMapper.class);
job.setReducerClass(KMeansReducer.class);
job.setJarByClass(KMeansMapper.class);
SequenceFileInputFormat.addInputPath(job, in);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(out))
fs.delete(out, true);
if (fs.exists(center))
fs.delete(out, true);
if (fs.exists(in))
fs.delete(out, true);
final SequenceFile.Writer centerWriter =
SequenceFile.createWriter(fs,
conf, center, ClusterCenter.class,
IntWritable.class);](https://image.slidesharecdn.com/hadoopinstallation-kmeansclusteringmapreduce-150109230522-conversion-gate01/75/Hadoop-installation-and-Running-KMeans-Clustering-with-MapReduce-Program-on-Hadoop-15-2048.jpg)

![17
in = new Path("files/clustering/depth_" +
(iteration - 1) + "/");
out = new Path("files/clustering/depth_" +
iteration);
SequenceFileInputFormat.addInputPath(job, in);
if (fs.exists(out))
fs.delete(out, true);
SequenceFileOutputFormat.setOutputPath(job, out);
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setOutputKeyClass(ClusterCenter.class);
job.setOutputValueClass(Vector.class);
job.waitForCompletion(true);
iteration++;
counter = job.getCounters()
.findCounter(KMeansReducer.Counter.CONVERGED).getValue();
}
Path result = new Path("files/clustering/depth_" +
(iteration - 1) + "/");
FileStatus[] stati = fs.listStatus(result);
for (FileStatus status : stati) {
if (!status.isDir() &&
!status.getPath().toString().contains("/_")) {
Path path = status.getPath();
LOG.info("FOUND " + path.toString());
SequenceFile.Reader reader = new
SequenceFile.Reader(fs, path,
conf);
ClusterCenter key = new ClusterCenter();
Vector v = new Vector();
while (reader.next(key, v)) {
LOG.info(key + " / " + v);
}
reader.close();
}
}
}
}](https://image.slidesharecdn.com/hadoopinstallation-kmeansclusteringmapreduce-150109230522-conversion-gate01/75/Hadoop-installation-and-Running-KMeans-Clustering-with-MapReduce-Program-on-Hadoop-17-2048.jpg)
![18
Final project listing will look like this
Figure 6 File Listing for KMeansMapReduce Program
2.3 Run the program
Unlike the wordcount program that we have to prepare the input files, in KMeansClustering
program the input is defined inside the KMeansClusteringJob class.
For running KMeansClustering job, since we are already configure the eclipse, we can run the
program natively inside Eclipse, So by pointing out the Main class (KMeansClusteringJob.java) we can
run the project as Hadoop Application
Figure 7 Run Project as hadoop application
The Input (to be defined in KMeansClusteringJob class)
Vector [vector=[16.0, 3.0]]
Vector [vector=[7.0, 6.0]]
Vector [vector=[6.0, 5.0]]
Vector [vector=[25.0, 1.0]]
Vector [vector=[1.0, 2.0]]
Vector [vector=[3.0, 3.0]]
Vector [vector=[2.0, 2.0]]
Vector [vector=[2.0, 3.0]]
Vector [vector=[-1.0, -23.0]]
Output from Thomas’s Blog :
ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[16.0, 3.0]]
ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[7.0, 6.0]]
ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[6.0, 5.0]]
ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[25.0, 1.0]]
ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[1.0, 2.0]]
ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[3.0, 3.0]]
ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[2.0, 2.0]]
ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[2.0, 3.0]]](https://image.slidesharecdn.com/hadoopinstallation-kmeansclusteringmapreduce-150109230522-conversion-gate01/75/Hadoop-installation-and-Running-KMeans-Clustering-with-MapReduce-Program-on-Hadoop-18-2048.jpg)
![19
ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[-1.0, -23.0]]
Output of my KMeansClusteringJob :
file:/home/tid/eclipse/workspace/MRClustering/files/clustering/depth_3/part-r-00000
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[13.5, 3.75]]] / Vector [vector=[16.0, 3.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[13.5, 3.75]]] / Vector [vector=[7.0, 6.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[13.5, 3.75]]] / Vector [vector=[6.0, 5.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[13.5, 3.75]]] / Vector [vector=[25.0, 1.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[1.4, -2.6]]] / Vector [vector=[1.0, 2.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[1.4, -2.6]]] / Vector [vector=[3.0, 3.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[1.4, -2.6]]] / Vector [vector=[2.0, 2.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[1.4, -2.6]]] / Vector [vector=[2.0, 3.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[1.4, -2.6]]] / Vector [vector=[-1.0, -23.0]]
Complete Log Result of My KMeansClusteringJob
14/04/08 15:50:35 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your
platform... using builtin-java classes where applicable
14/04/08 15:50:35 INFO compress.CodecPool: Got brand-new compressor
14/04/08 15:50:35 WARN mapred.JobClient: Use GenericOptionsParser for parsing the
arguments. Applications should implement Tool for the same.
14/04/08 15:50:35 WARN mapred.JobClient: No job jar file set. User classes may not be](https://image.slidesharecdn.com/hadoopinstallation-kmeansclusteringmapreduce-150109230522-conversion-gate01/75/Hadoop-installation-and-Running-KMeans-Clustering-with-MapReduce-Program-on-Hadoop-19-2048.jpg)



![23
14/04/08 15:50:39 INFO mapred.JobClient: Reduce output records=9
14/04/08 15:50:39 INFO mapred.JobClient: Spilled Records=18
14/04/08 15:50:39 INFO mapred.JobClient: Map output bytes=360
14/04/08 15:50:39 INFO mapred.JobClient: Total committed heap usage (bytes)=754712576
14/04/08 15:50:39 INFO mapred.JobClient: CPU time spent (ms)=0
14/04/08 15:50:39 INFO mapred.JobClient: Virtual memory (bytes) snapshot=0
14/04/08 15:50:39 INFO mapred.JobClient: SPLIT_RAW_BYTES=148
14/04/08 15:50:39 INFO mapred.JobClient: Map output records=9
14/04/08 15:50:39 INFO mapred.JobClient: Combine input records=0
14/04/08 15:50:39 INFO mapred.JobClient: Reduce input records=9
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: FOUND
file:/home/tid/eclipse/workspace/MRClustering/files/clustering/depth_3/part-r-00000
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[13.5, 3.75]]] / Vector [vector=[16.0, 3.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[13.5, 3.75]]] / Vector [vector=[7.0, 6.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[13.5, 3.75]]] / Vector [vector=[6.0, 5.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[13.5, 3.75]]] / Vector [vector=[25.0, 1.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[1.4, -2.6]]] / Vector [vector=[1.0, 2.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[1.4, -2.6]]] / Vector [vector=[3.0, 3.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[1.4, -2.6]]] / Vector [vector=[2.0, 2.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[1.4, -2.6]]] / Vector [vector=[2.0, 3.0]]
14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector
[vector=[1.4, -2.6]]] / Vector [vector=[-1.0, -23.0]]
References
Hadoop Installation on single node cluster - http://www.michael-noll.com/tutorials/running-
hadoop-on-ubuntu-linux-single-node-cluster/
KMeansClustering with MapReduce - http://codingwiththomas.blogspot.kr/2011/05/k-
means-clustering-with-mapreduce.html](https://image.slidesharecdn.com/hadoopinstallation-kmeansclusteringmapreduce-150109230522-conversion-gate01/75/Hadoop-installation-and-Running-KMeans-Clustering-with-MapReduce-Program-on-Hadoop-23-2048.jpg)

1. The document discusses installing Hadoop in single node cluster mode on Ubuntu, including installing Java, configuring SSH, extracting and configuring Hadoop files. Key configuration files like core-site.xml and hdfs-site.xml are edited. 2. Formatting the HDFS namenode clears all data. Hadoop is started using start-all.sh and the jps command checks if daemons are running. 3. The document then moves to discussing running a KMeans clustering MapReduce program on the installed Hadoop framework.








































































