Downloaded 224 times




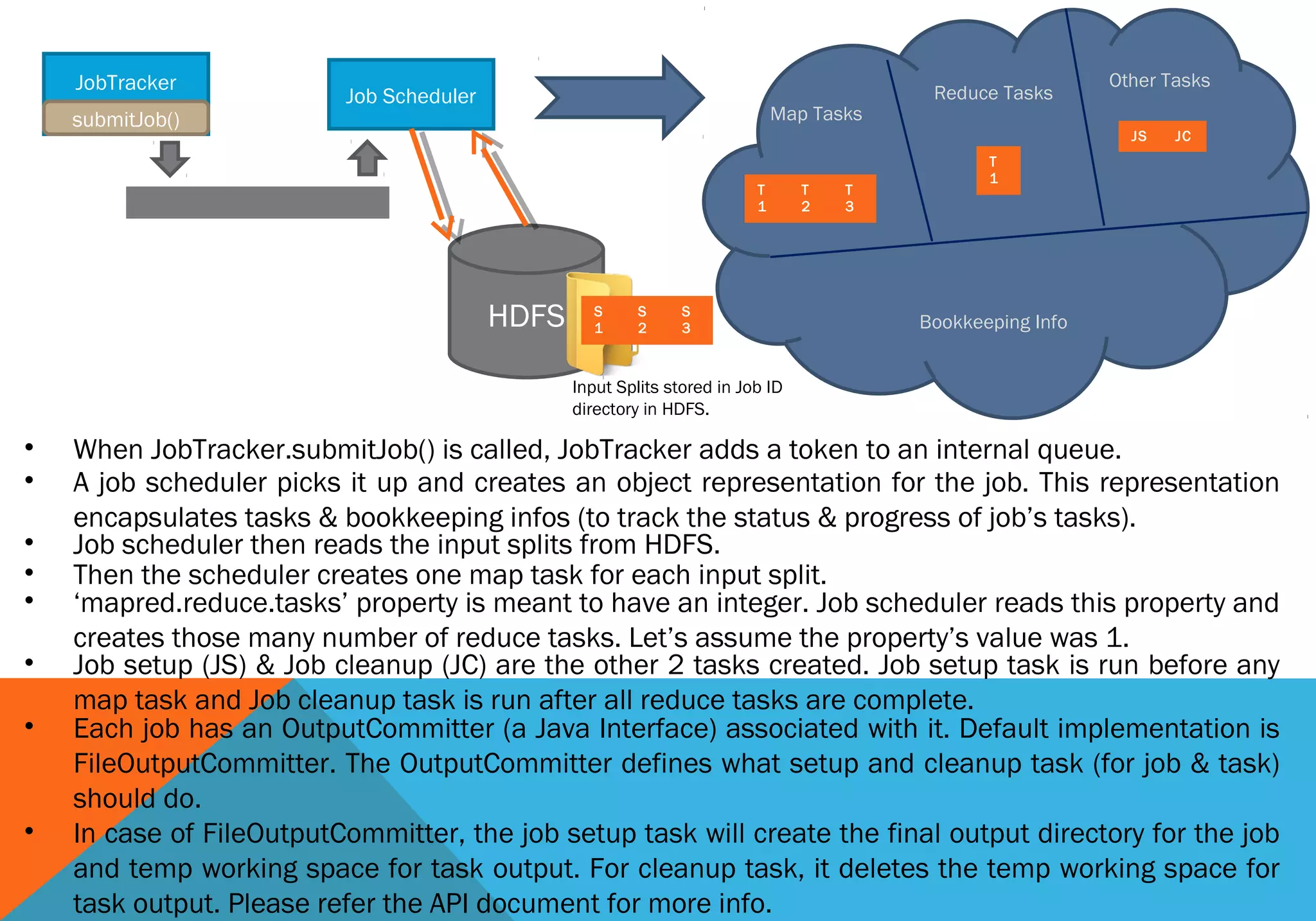

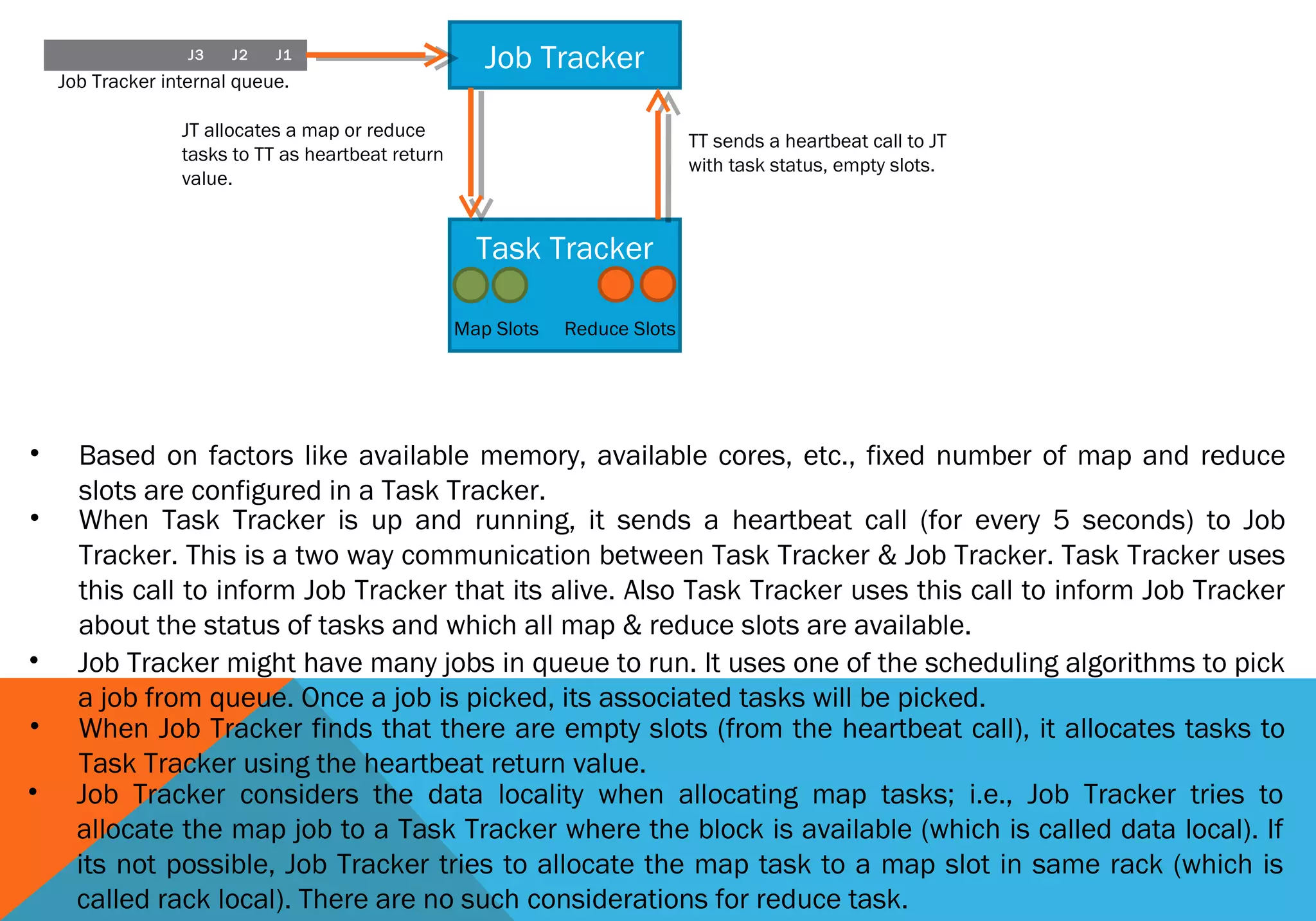

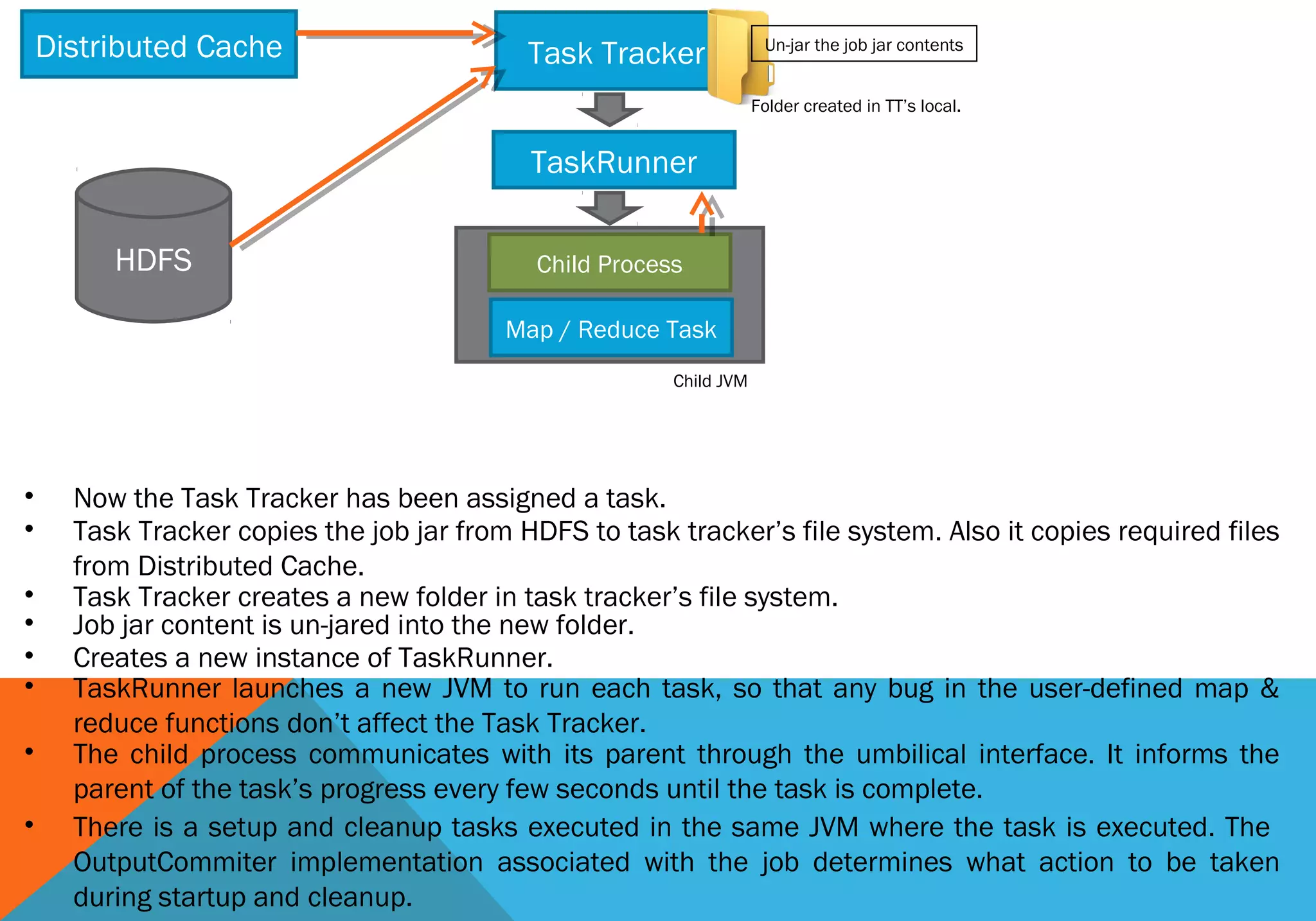







1) A job is first submitted to the Hadoop cluster by a client calling the Job.submit() method. This generates a unique job ID and copies the job files to HDFS. 2) The JobTracker then initializes the job by splitting it into tasks like map and reduce tasks. It assigns tasks to TaskTrackers based on data locality. 3) Each TaskTracker executes tasks by copying job files, running tasks in a child JVM, and reporting progress back to the JobTracker. 4) The JobTracker tracks overall job status and progress by collecting task status updates from TaskTrackers. It reports this information back to clients. 5) Once all tasks complete successfully, the job


























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












