How To Build
CloudStorage Services
张卫平 (Simon Zhang)
with the team of
武汉播思科技有限公司 (Hanborq Inc)
June 2012
2.
About me
• SimonZhang 张卫平, CTO
武汉播思科技有限公司 (Hanborq Inc.)
simon.zhang@gmail.com
@seymourz
3.
About this talk
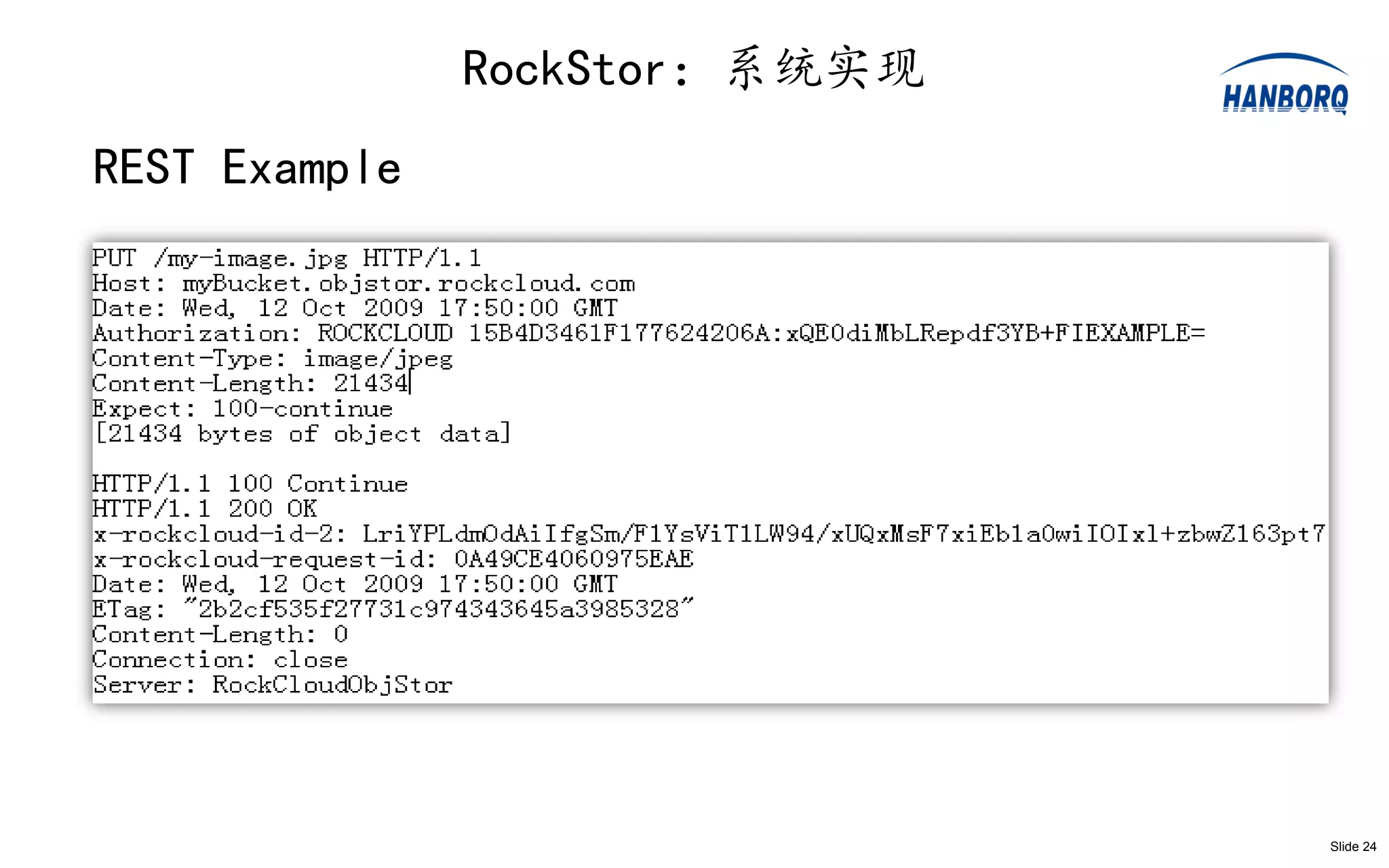
•This talk describes how to build an Amazon AWS S3 - like
cloud storage service prototype based on Apache
Hadoop stack;
• This talk also touches on how to build a Dropbox - like
personal storage service, based on S3 - like cloud
storage services.
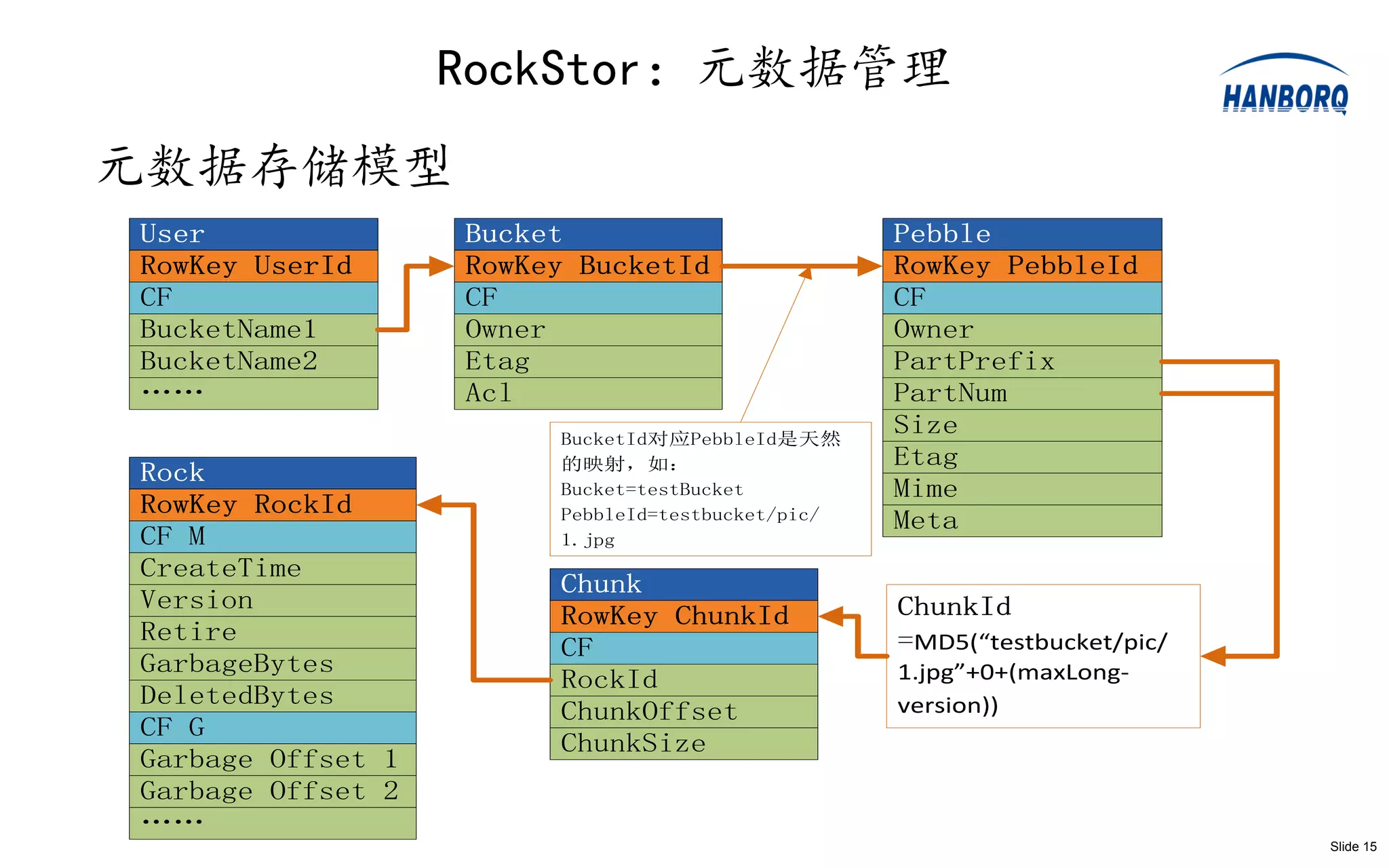
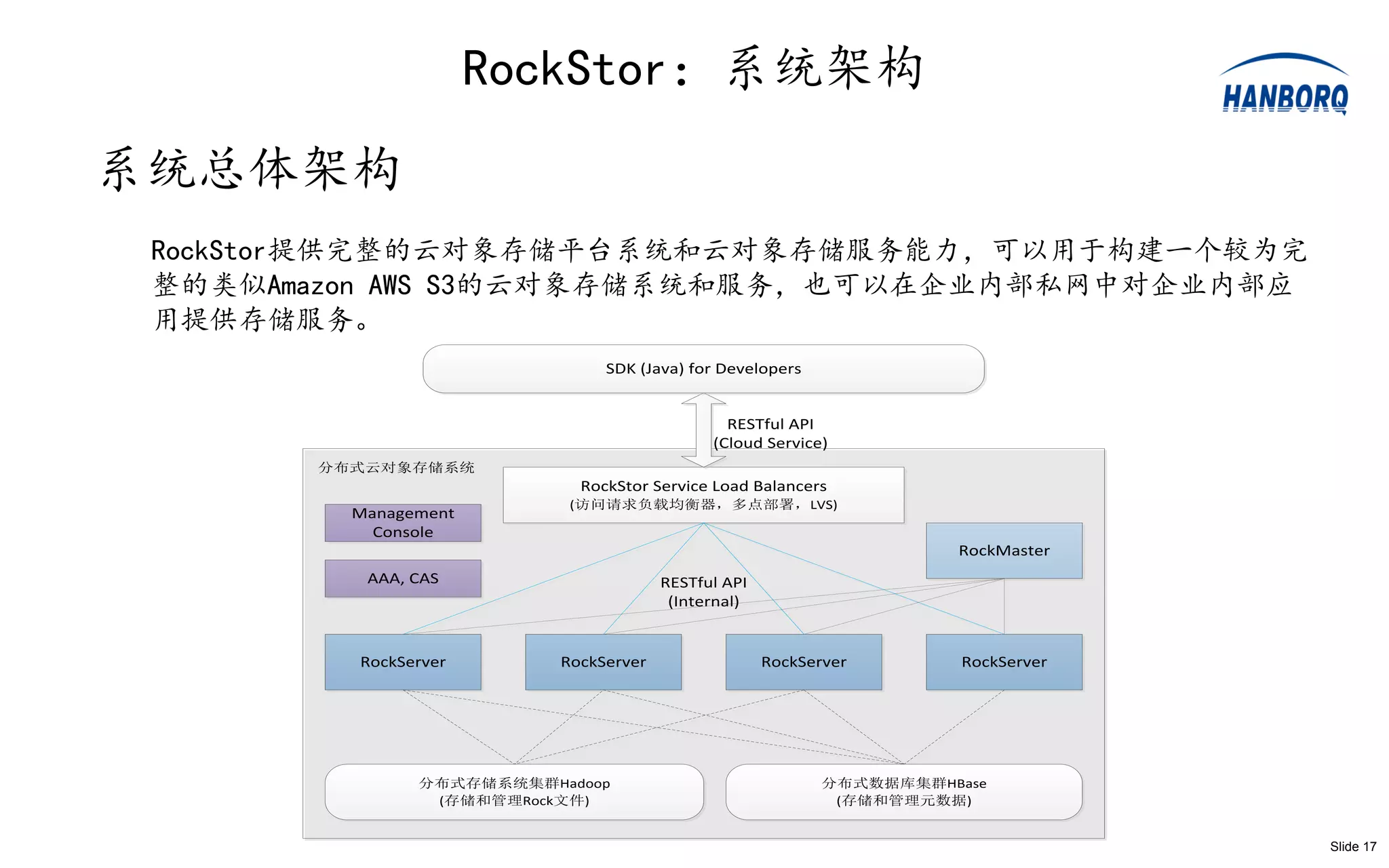
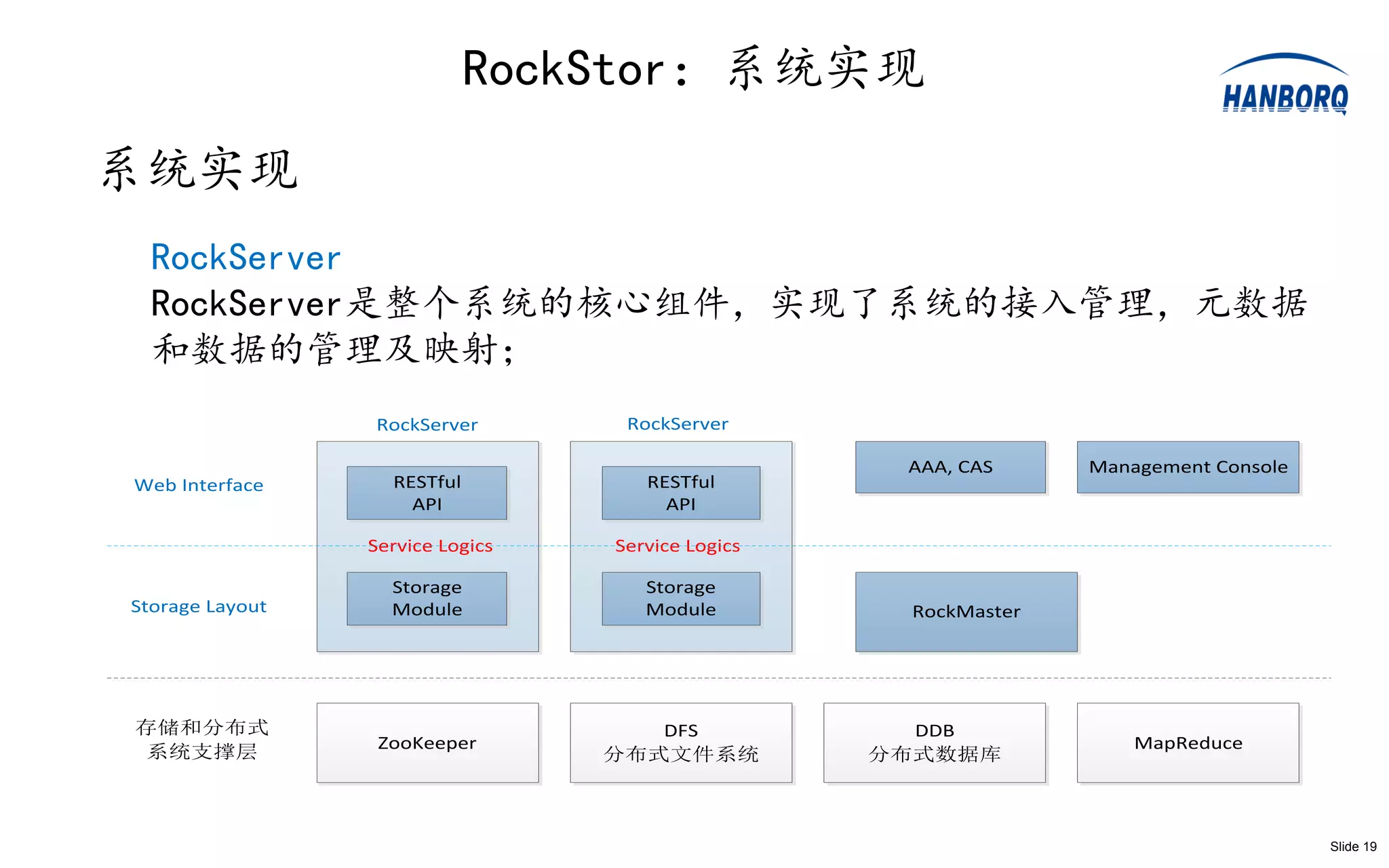
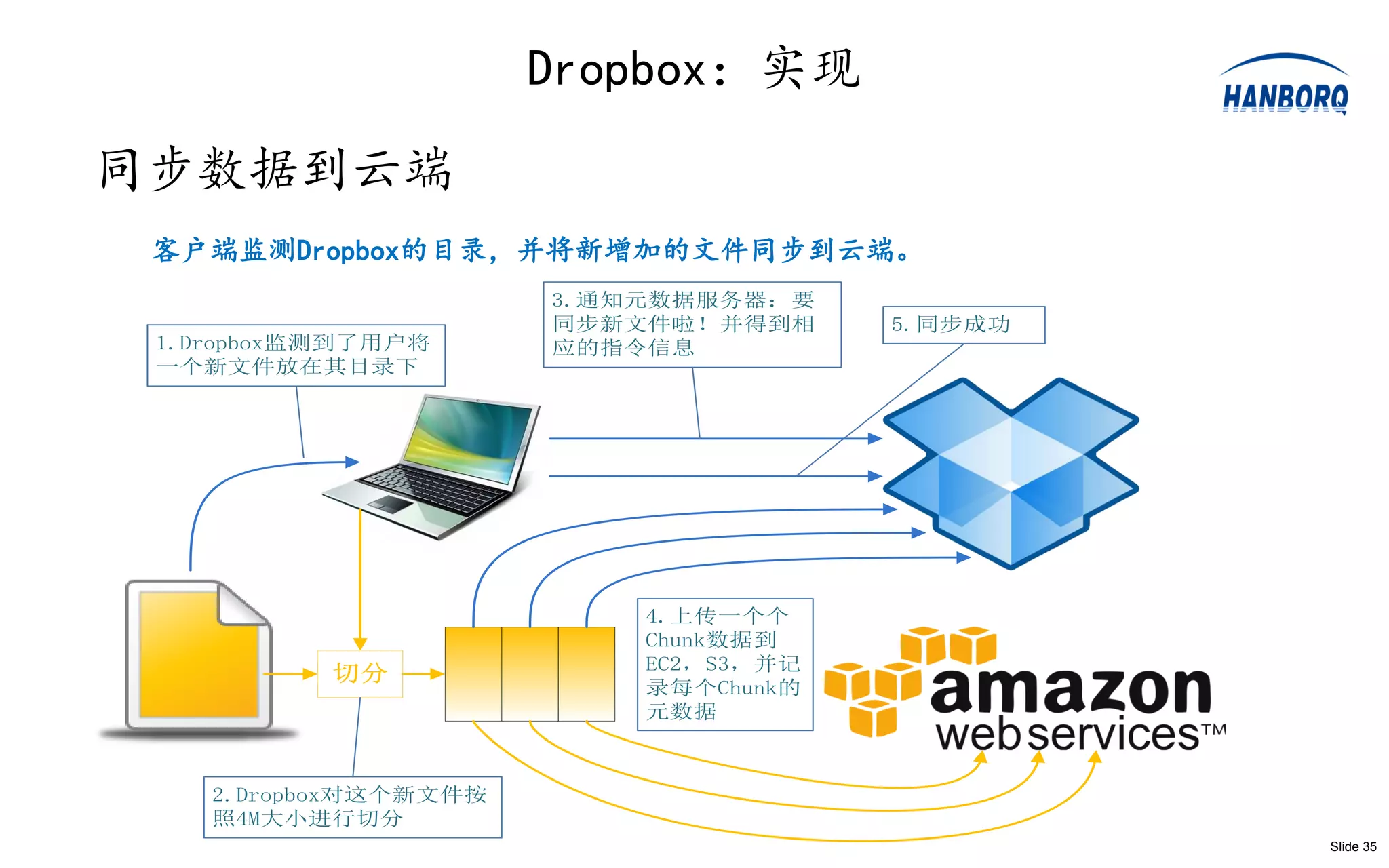
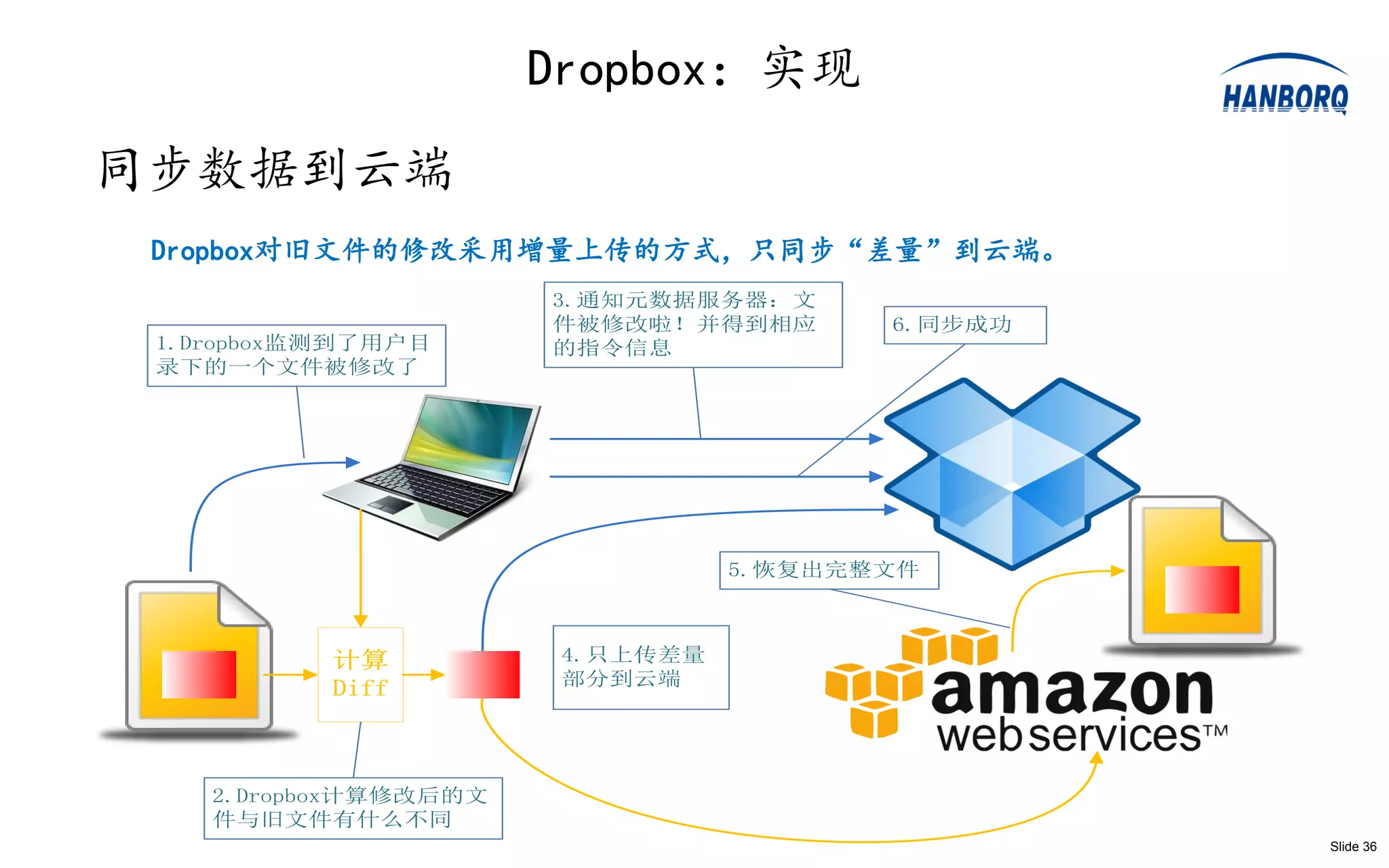
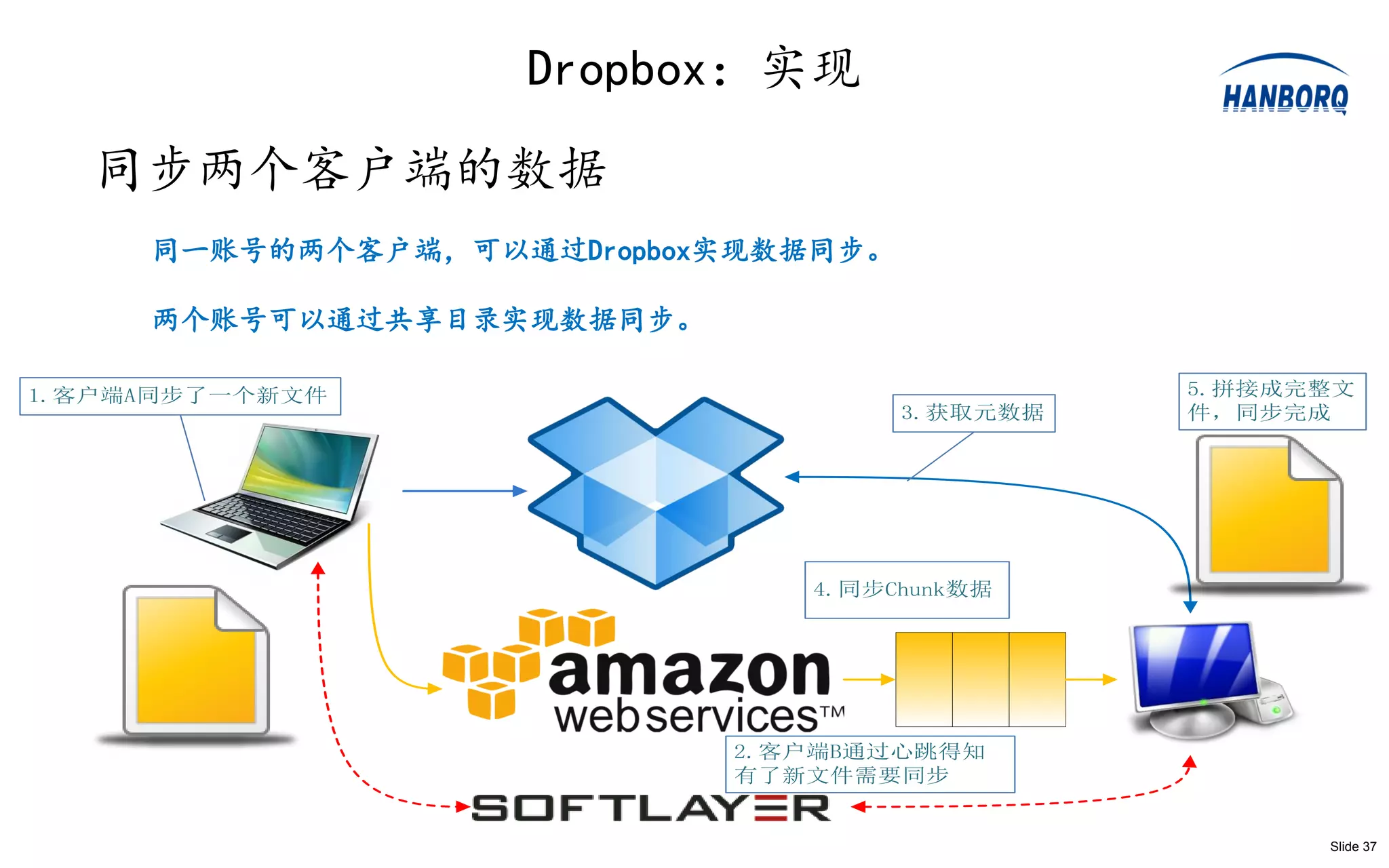
RockStor:系统实现
系统实现
RockServer
RockServer是整个系统的核心组件,实现了系统的接入管理,元数据
和数据的管理及映射;
RockServer RockServer
AAA, CAS Management Console
Web Interface RESTful RESTful
API API
Service Logics Service Logics
Storage Storage
Storage Layout Module Module RockMaster
存储和分布式 DFS DDB
系统支撑层 ZooKeeper MapReduce
分布式文件系统 分布式数据库
Slide 19
20.
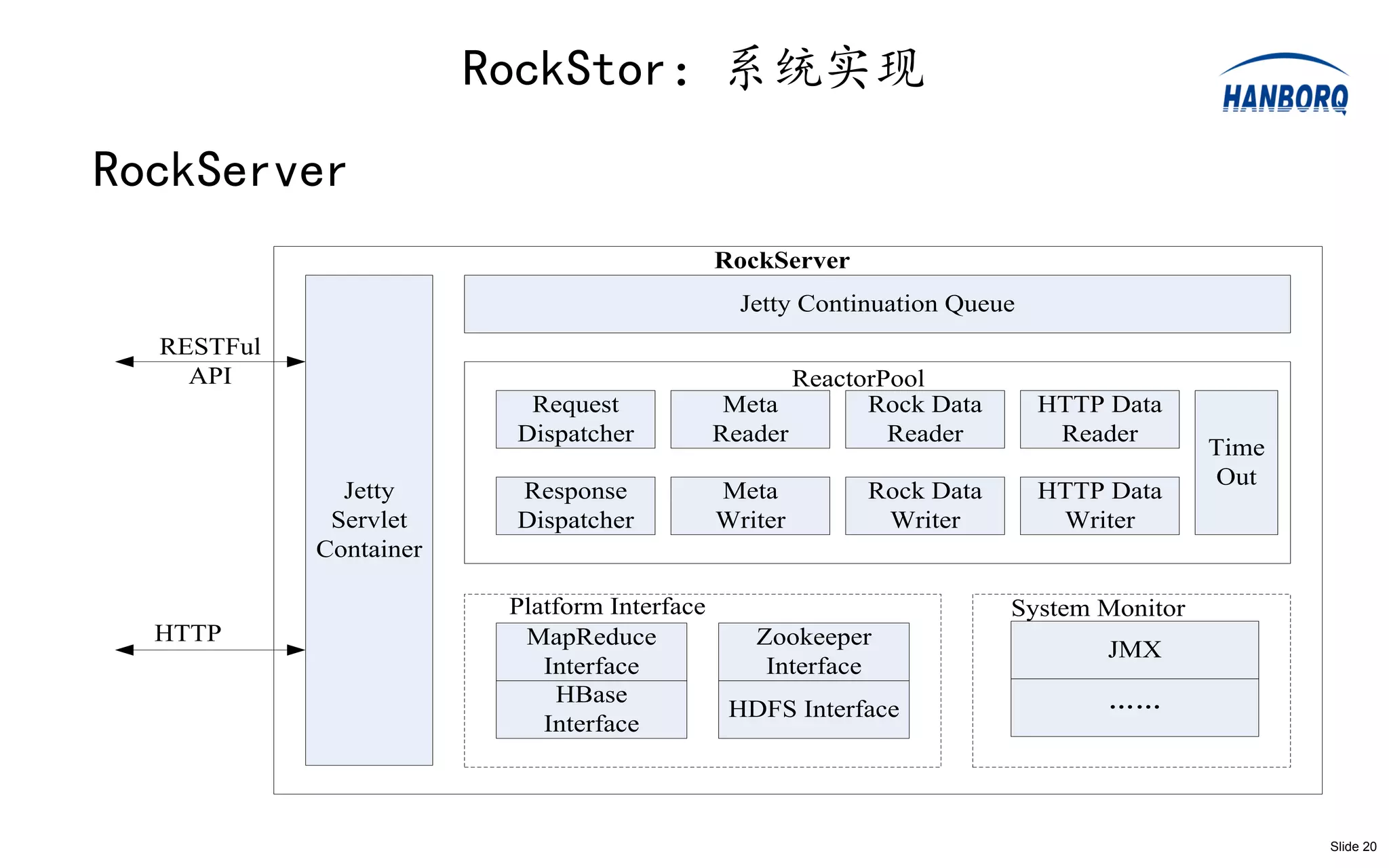
RockStor:系统实现
RockServer
RockServer
Jetty Continuation Queue
RESTFul
API ReactorPool
Request Meta Rock Data HTTP Data
Dispatcher Reader Reader Reader
Time
Out
Jetty Response Meta Rock Data HTTP Data
Servlet Dispatcher Writer Writer Writer
Container
Platform Interface System Monitor
HTTP MapReduce Zookeeper
JMX
Interface Interface
HBase
HDFS Interface ……
Interface
Slide 20
RockStor:系统实现
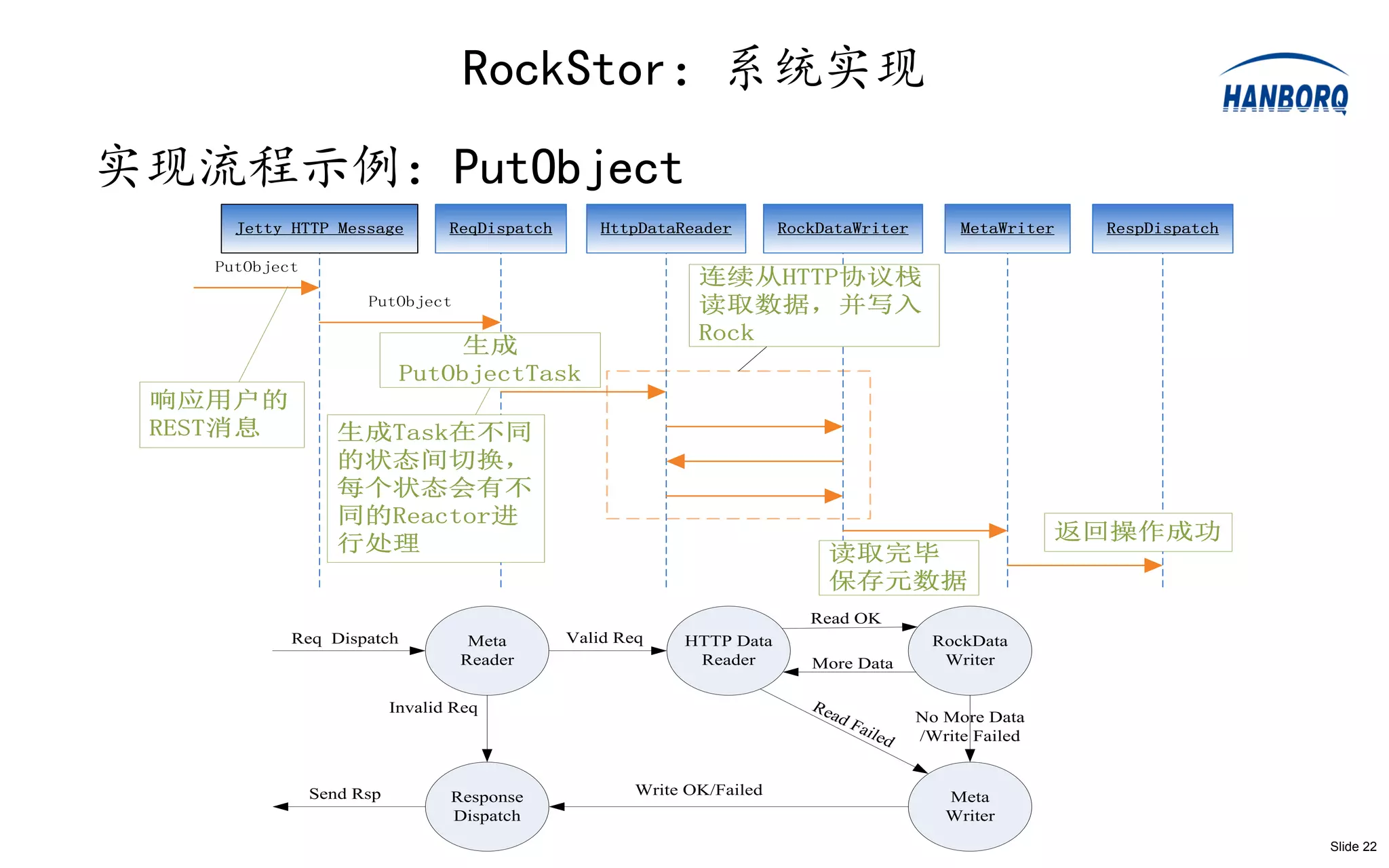
实现流程示例:PutObject
Jetty HTTP Message ReqDispatch HttpDataReader RockDataWriter MetaWriter RespDispatch
PutObject
连续从HTTP协议栈
PutObject 读取数据,并写入
Rock
生成
PutObjectTask
响应用户的
REST消息 生成Task在不同
的状态间切换,
每个状态会有不
同的Reactor进
返回操作成功
行处理 读取完毕
保存元数据
Read OK
Req Dispatch Meta Valid Req HTTP Data RockData
Reader Reader More Data Writer
Invalid Req Re
ad No More Data
F aile
d /Write Failed
Send Rsp Response Write OK/Failed Meta
Dispatch Writer
Slide 22
23.
RockStor:系统实现
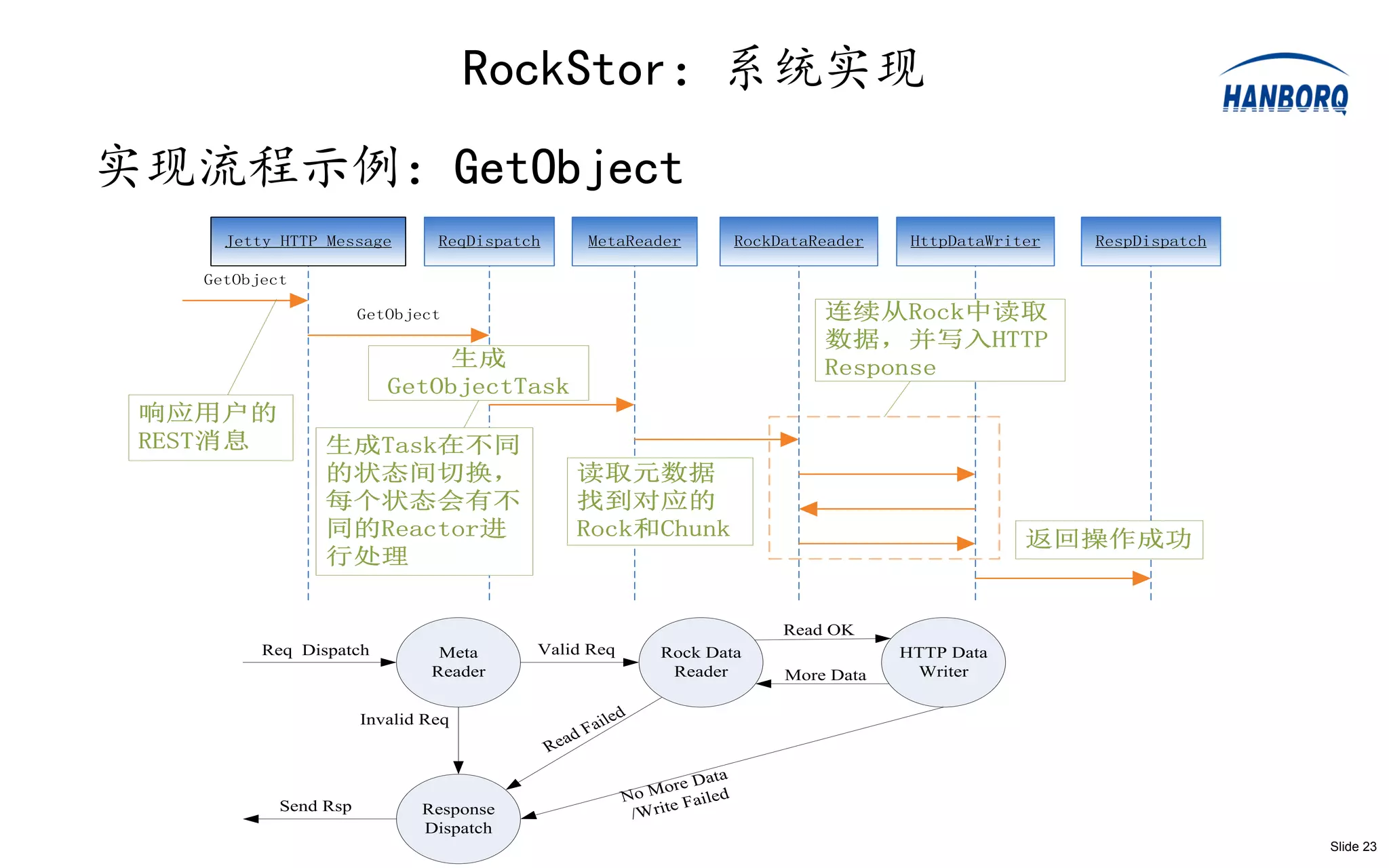
实现流程示例:GetObject
Jetty HTTP Message ReqDispatch MetaReader RockDataReader HttpDataWriter RespDispatch
GetObject
GetObject 连续从Rock中读取
数据,并写入HTTP
生成 Response
GetObjectTask
响应用户的
REST消息 生成Task在不同
的状态间切换, 读取元数据
每个状态会有不 找到对应的
同的Reactor进 Rock和Chunk 返回操作成功
行处理
Read OK
Req Dispatch Meta Valid Req Rock Data HTTP Data
Reader Reader More Data Writer
Invalid Req led
Fai
ad
Re
ata
ore D
No M Failed
Send Rsp e
Response /Writ
Dispatch
Slide 23
Further Readings
• AmazonAWS S3 Developer Guide
(http://docs.amazonwebservices.com/AmazonS3/latest/dev/Welcome.html?r=3378)
• Amazon Patent on S3
(http://www.freepatentsonline.com/y2007/0156842.html)
• Facebook Paper on Haystack for Photo Storage
(http://static.usenix.org/events/osdi10/tech/full_papers/Beaver.pdf)
41.
Homework (1)
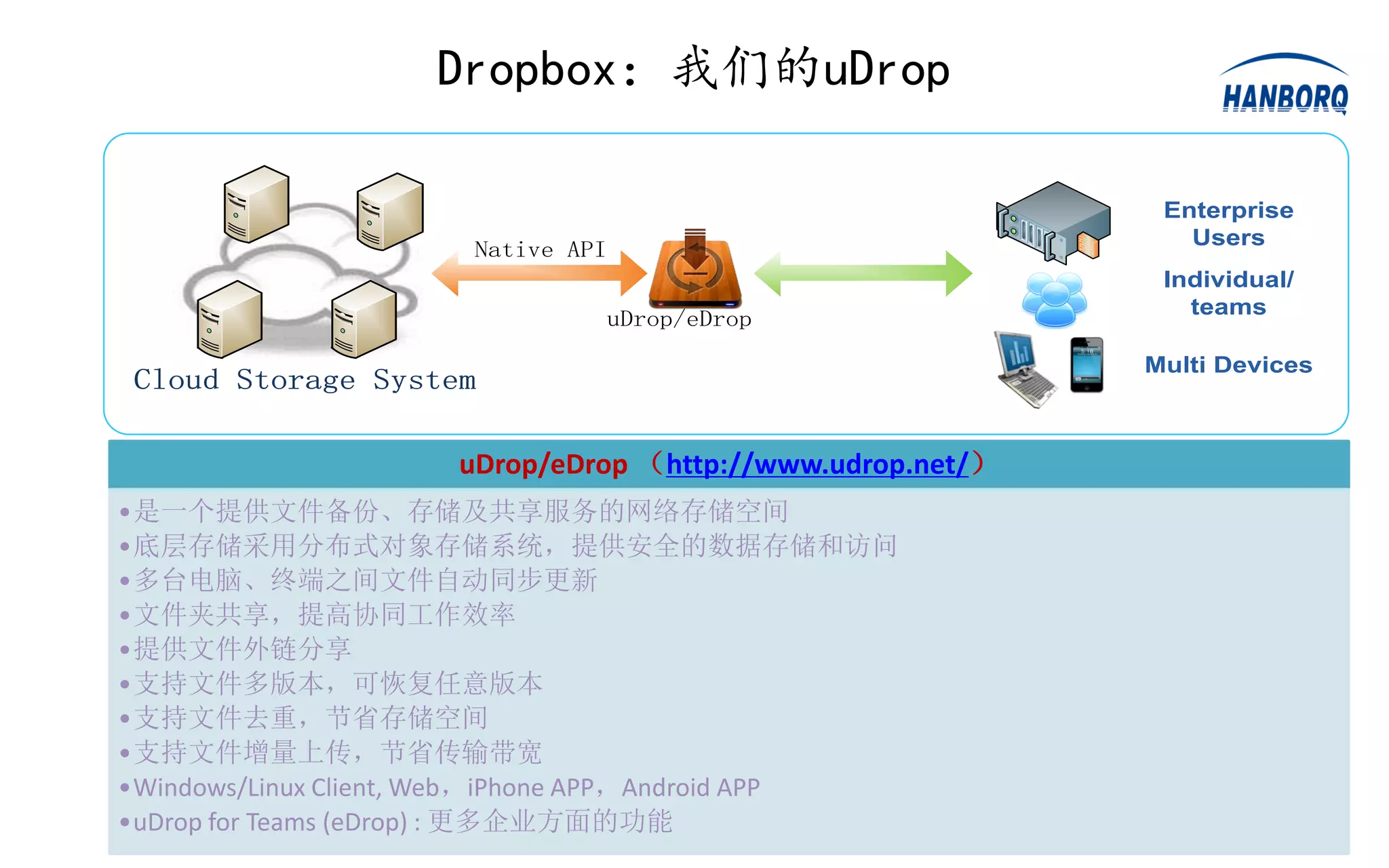
• Installa Dropbox on your computer and Play with it;
• Look into its local SQLite on how Dropbox segments
documents/files and how it represents them;
• Formulate the serve-side logic on how Dropbox re-assembles
segments into a document.
42.
Homework (2)
• Whatare the differences in objects’ meta data
structures and organizations implementation between
RockStor and S3?
(You’d read into the codes of RockStor and patent
presentation of S3 )