











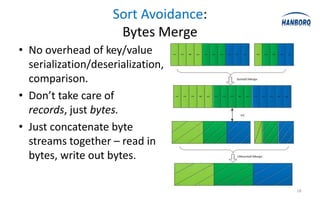
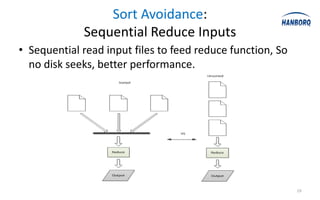
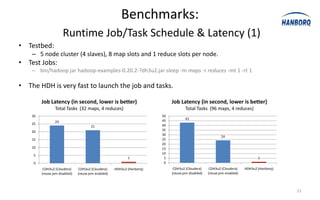
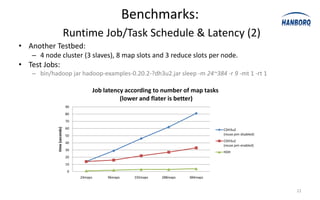
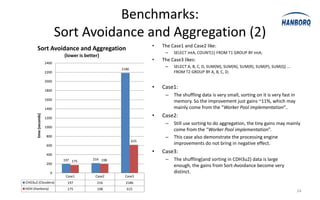
![Sort Avoidance:
Spilling and Partitioning
• When spills, records compare by partition only.
• Partition comparison using counting sort [O(n)], not quick sort
[O(nlog n)].
16](https://image.slidesharecdn.com/hanborqoptimizationsonhadoopmapreduce-20120216a-120215205232-phpapp01/85/Hanborq-Optimizations-on-Hadoop-MapReduce-16-320.jpg)



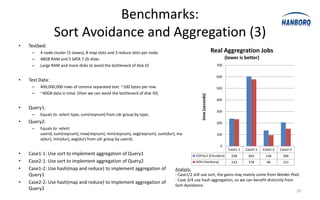

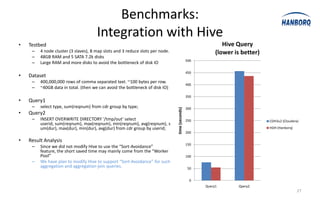






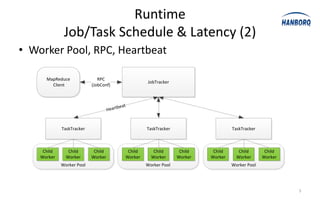
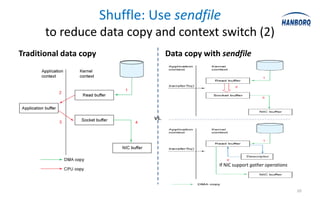
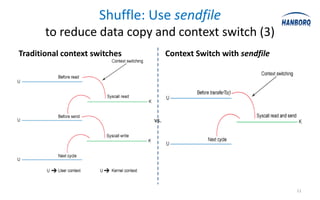
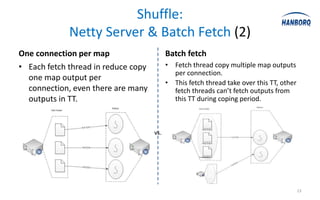
The document discusses optimizations for the Hadoop MapReduce framework, focusing on improving latency and performance by implementing features like a worker pool and efficient data transfer methods. It highlights the benefits of tuning configurations and making architectural changes to enhance data processing efficiency. The proposed 'hanborq distribution' aims to deliver a faster, simpler, and more robust version of Hadoop, particularly beneficial for enterprises struggling with MapReduce performance.














































![Resource Aware Scheduling for Hadoop [Final Presentation]](https://cdn.slidesharecdn.com/ss_thumbnails/fyppresentationfinal-120226092754-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)































