![June 14, 2012
Optimizing MapReduce Job
Performance
Todd Lipcon [@tlipcon]](https://image.slidesharecdn.com/mrperf-120618124706-phpapp01/85/Hadoop-Summit-2012-Optimizing-MapReduce-Job-Performance-1-320.jpg)
![June 14, 2012
Optimizing MapReduce Job
Performance
Todd Lipcon [@tlipcon]](https://image.slidesharecdn.com/mrperf-120618124706-phpapp01/75/Hadoop-Summit-2012-Optimizing-MapReduce-Job-Performance-1-2048.jpg)




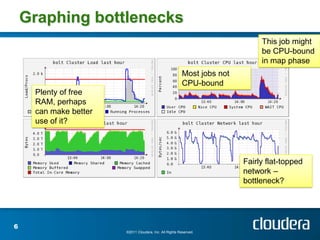
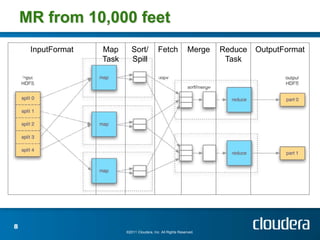
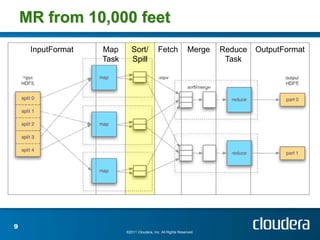
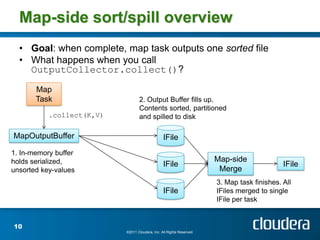
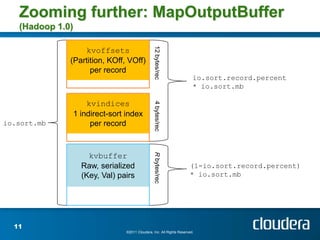







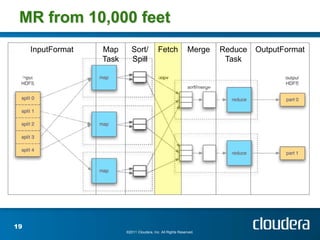


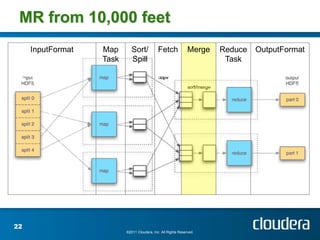
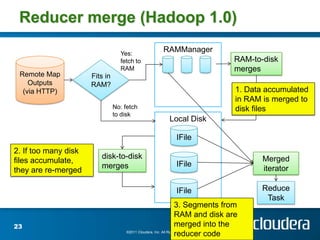





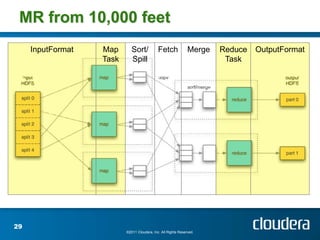





The document discusses optimizing MapReduce job performance, emphasizing the importance of understanding the framework's internals and measuring job metrics for tuning. It outlines techniques for managing memory spills, reducing fetch bottlenecks, and configuring task settings to enhance performance. The presentation also advises focusing tuning efforts on significant bottlenecks and considering resource scaling to improve job efficiency.















![Resource Aware Scheduling for Hadoop [Final Presentation]](https://cdn.slidesharecdn.com/ss_thumbnails/fyppresentationfinal-120226092754-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







































































