Downloaded 4,356 times




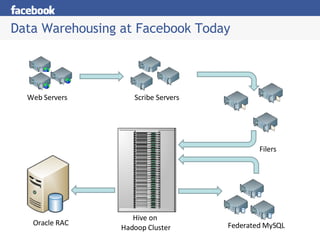


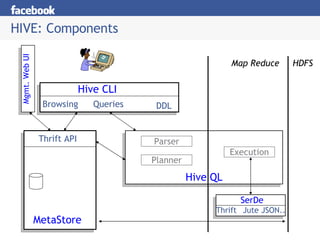
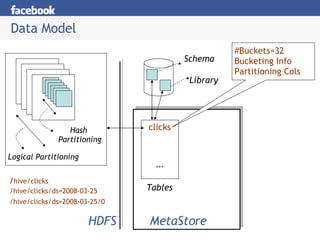

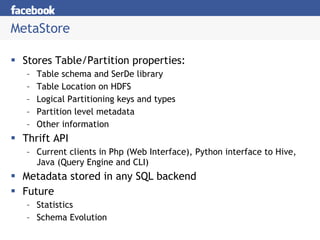


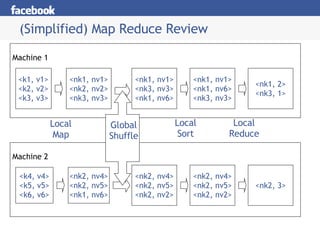


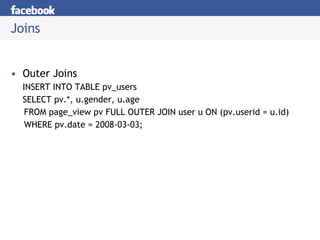

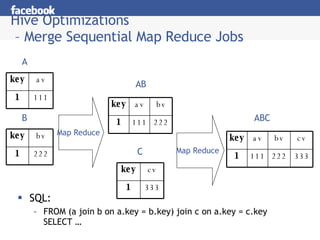
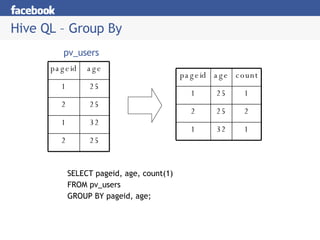
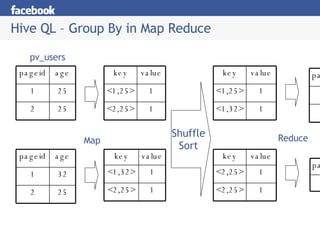

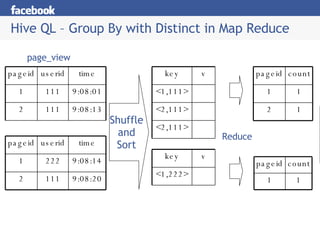



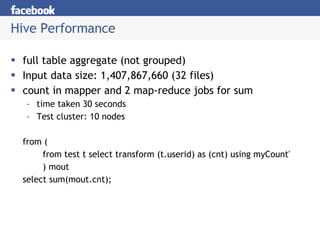


Hive is a data warehousing system built on Hadoop that allows users to query data using SQL. It addresses issues with using Hadoop for analytics like programmability and metadata. Hive uses a metastore to manage metadata and supports structured data types, SQL queries, and custom MapReduce scripts. At Facebook, Hive is used for analytics tasks like summarization, ad hoc analysis, and data mining on over 180TB of data processed daily across a Hadoop cluster.



















































































