





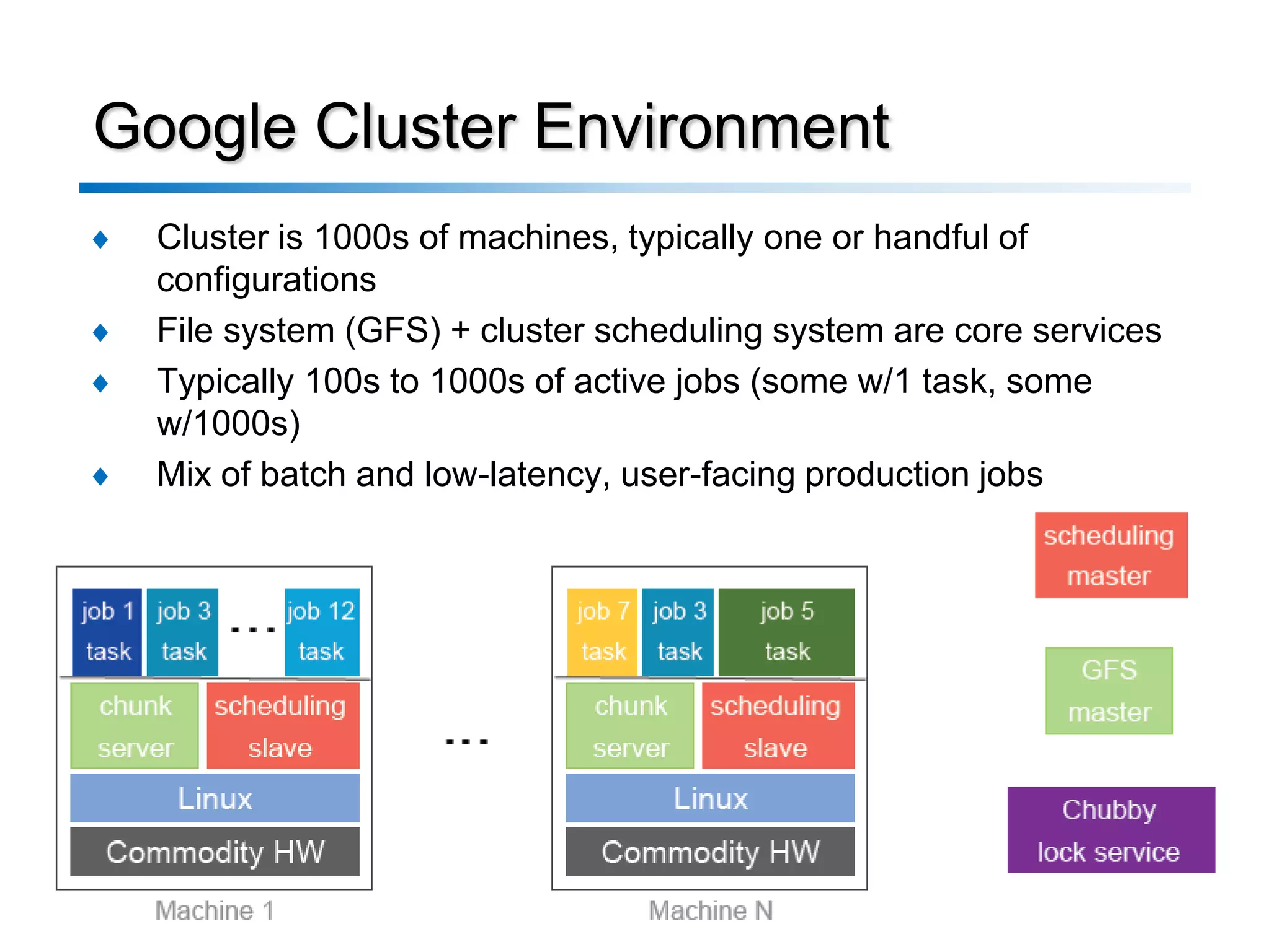





![Criticism
♦ D. DeWitt and M. Stonebraker badly criticized that
―MapReduce is a major step backwards‖[5].
– He first regarded it as a simple Extract-Transform-Load tool.
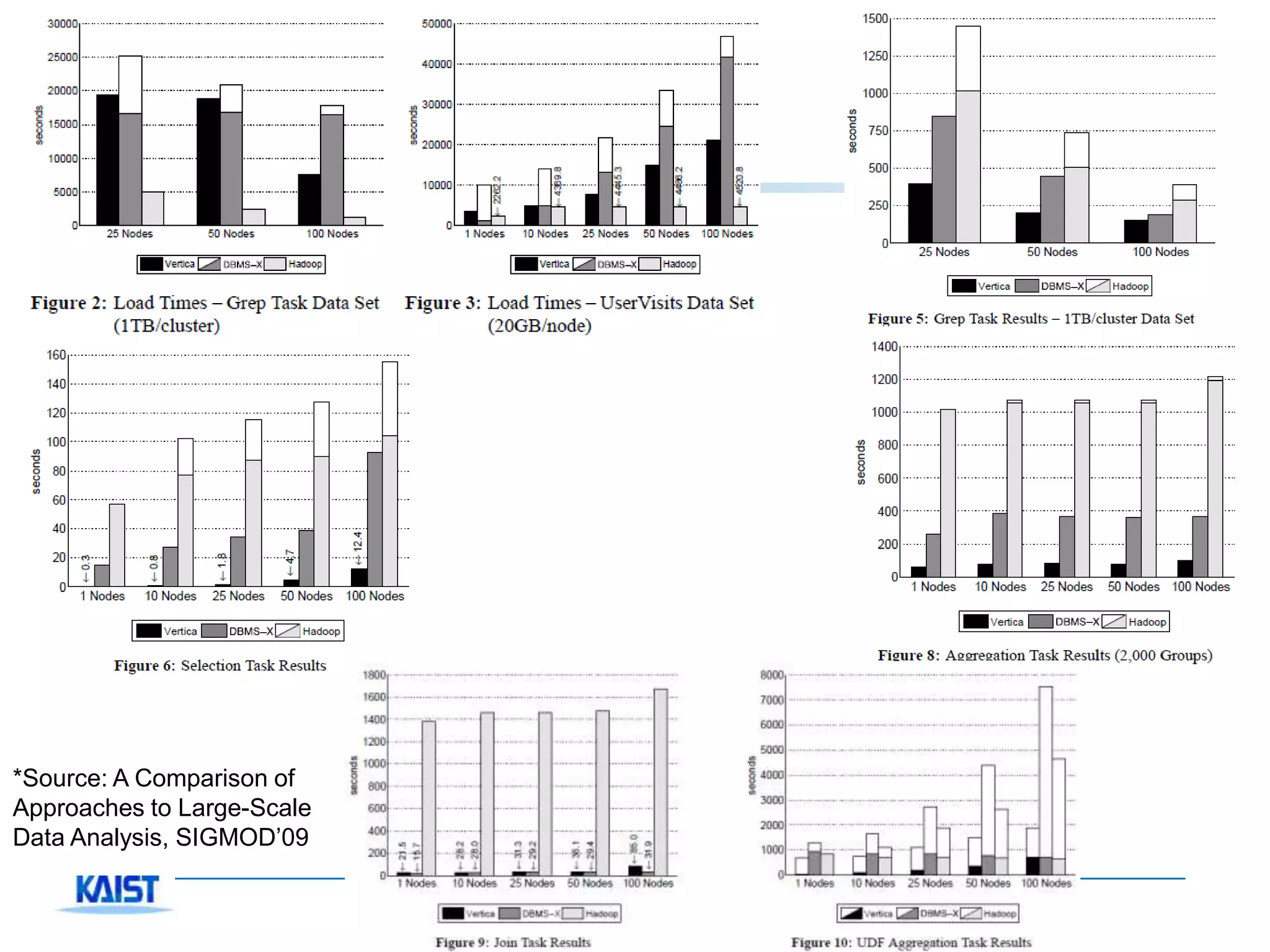
♦ A technical comparison was done by Pavlo and et
al.[6]
– Compared with a commercial row-wise DBMS and Vertica
– After that, technical debates btw. researchers vs.
practitioners are triggered
♦ CACM welcomed this technical debate, inviting both
sides in The Communications of ACM, Jan 2010[7,8]
Copyright © KAIST Database Lab. All Rights Reserved.](https://image.slidesharecdn.com/mapreduce-short-120102035113-phpapp02/75/MapReduce-A-useful-parallel-tool-that-still-has-room-for-improvement-27-2048.jpg)


![A Short List of Related Study
♦ Sacrifice of disk I/O for fault- ♦ A simple heuristic scheduling
tolerance – LATE, …
– Main difference against DBMS ♦ Relatively poor performance
♦ A single fixed dataflow – Adaptive and automatic performance
– Dryad, SCOPE, Nephele/PACT tuning.
– Map-Reduce-Merge for binary – Work sharing/Multiple jobs
operators » MRShare: Multi query processing
– Twister and HaLoop for iterative » Hive, Pig Latin
workload » fair/capacity sharing, ParaTimer
– Map-Join-Reduce and some join – Map-Join-Reduce
techniques – Join algorithms in MapReduce[Blanas-
SIGMOD’10]
♦ No schema
– Protocol buffer, JSON, XML, …. ♦ Cowork with other tools
– SQL/MapReduce, HadoopDB, Teradata
♦ No indexing
EDW’s Hadoop integration, ….
– HadoopDB, Hadoop++
♦ DBMS based on MR
♦ No high-level language
– Cheetah, Osprey, RICARDO(analytic
– Hive, Sawzall, SCOPE, Pig Latin, … , tool)
Jaql, Dryad/LINQ
♦ Other complements
♦ Blocking operators
– DREMEL, …
– MapReduce Online, Mortar
Copyright © KAIST Database Lab. All Rights Reserved.](https://image.slidesharecdn.com/mapreduce-short-120102035113-phpapp02/75/MapReduce-A-useful-parallel-tool-that-still-has-room-for-improvement-31-2048.jpg)










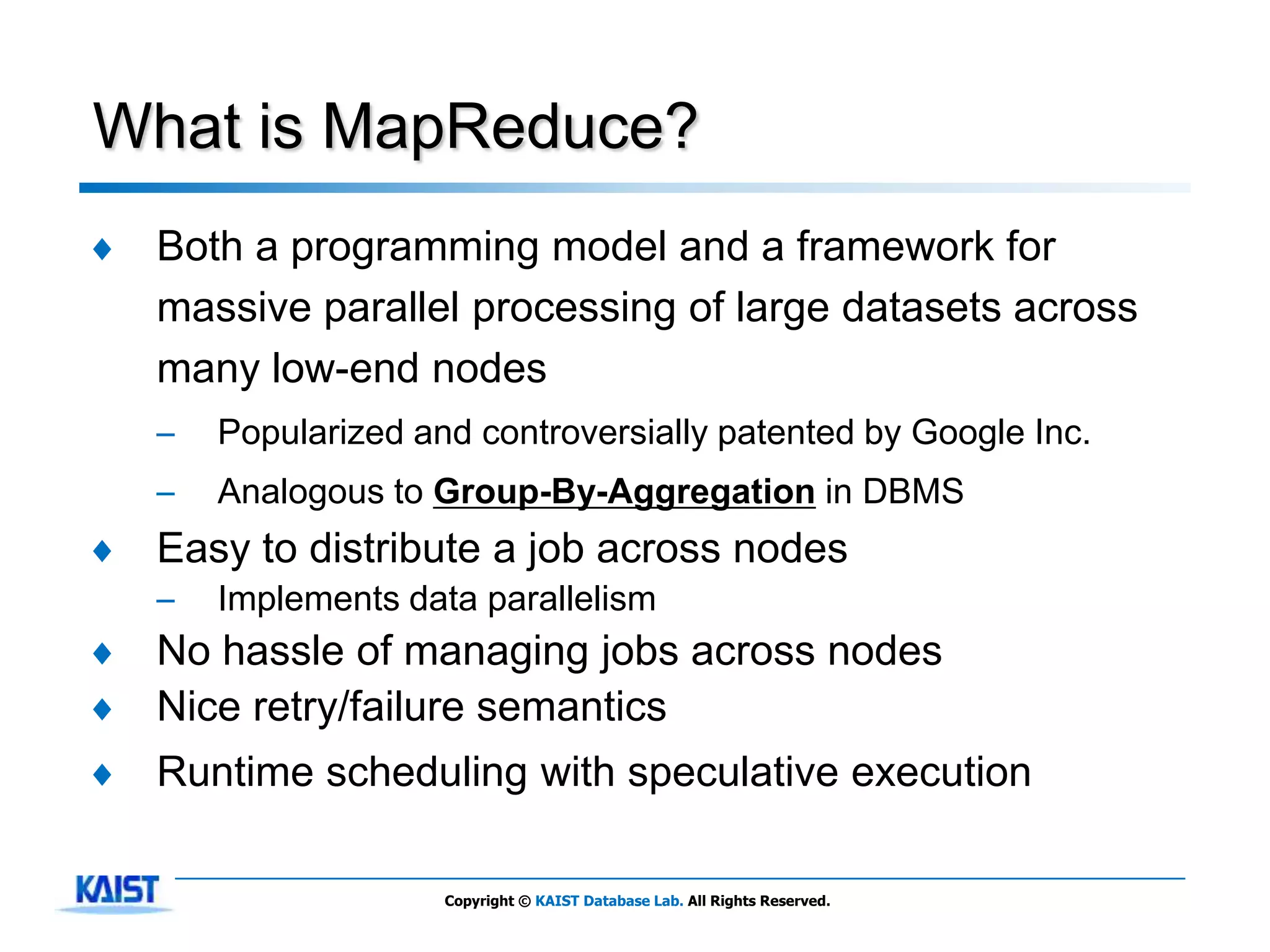
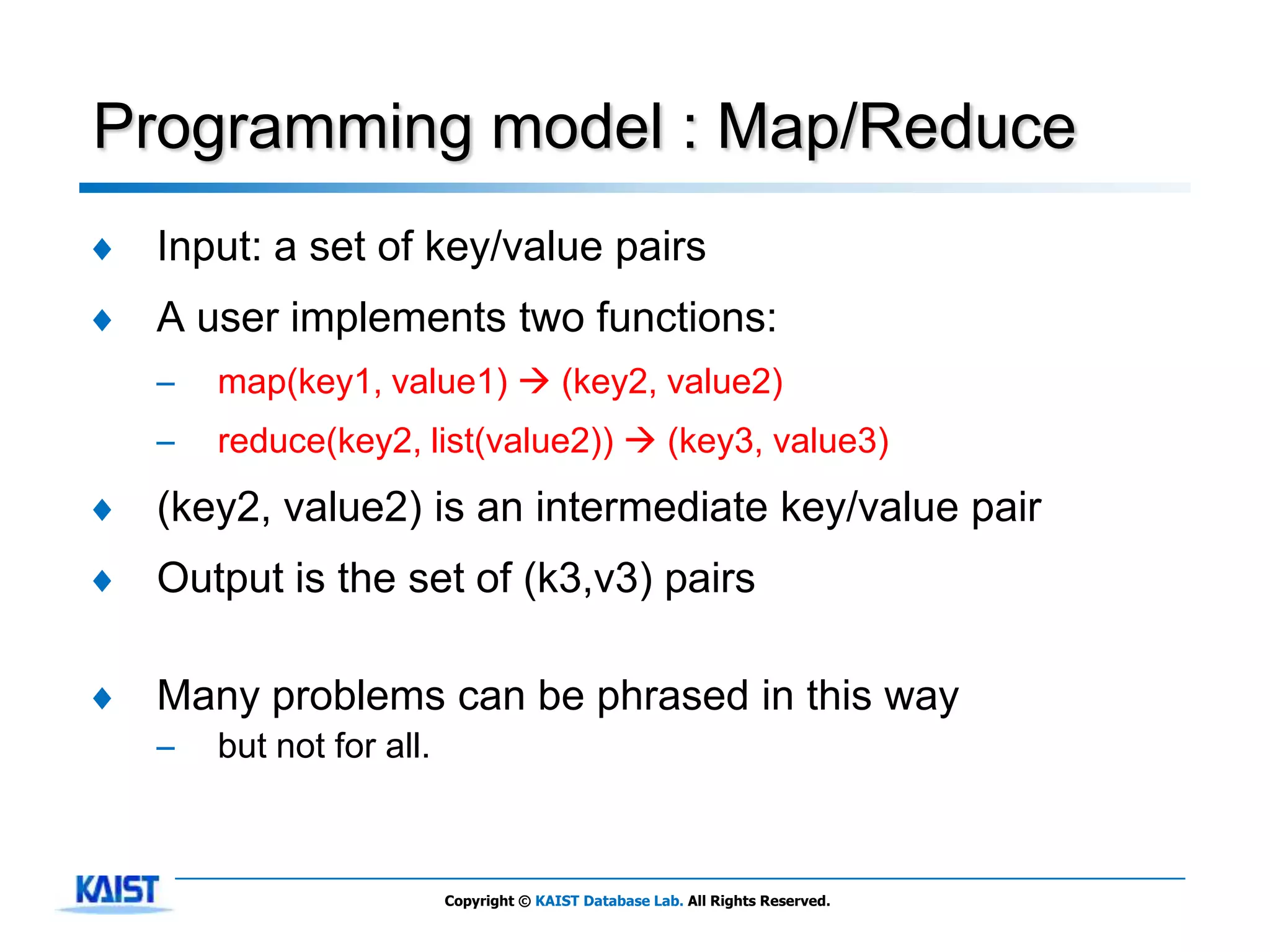
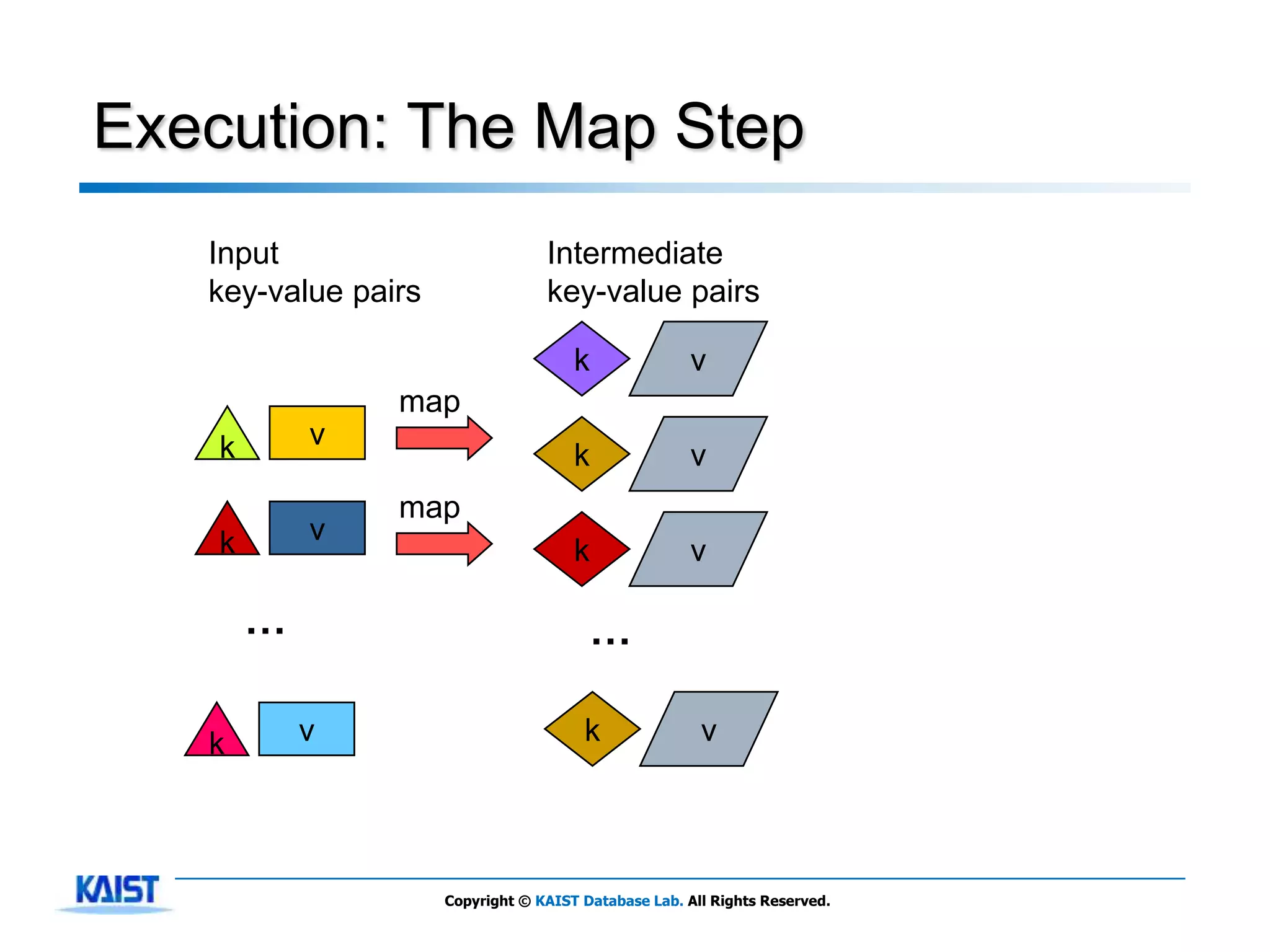
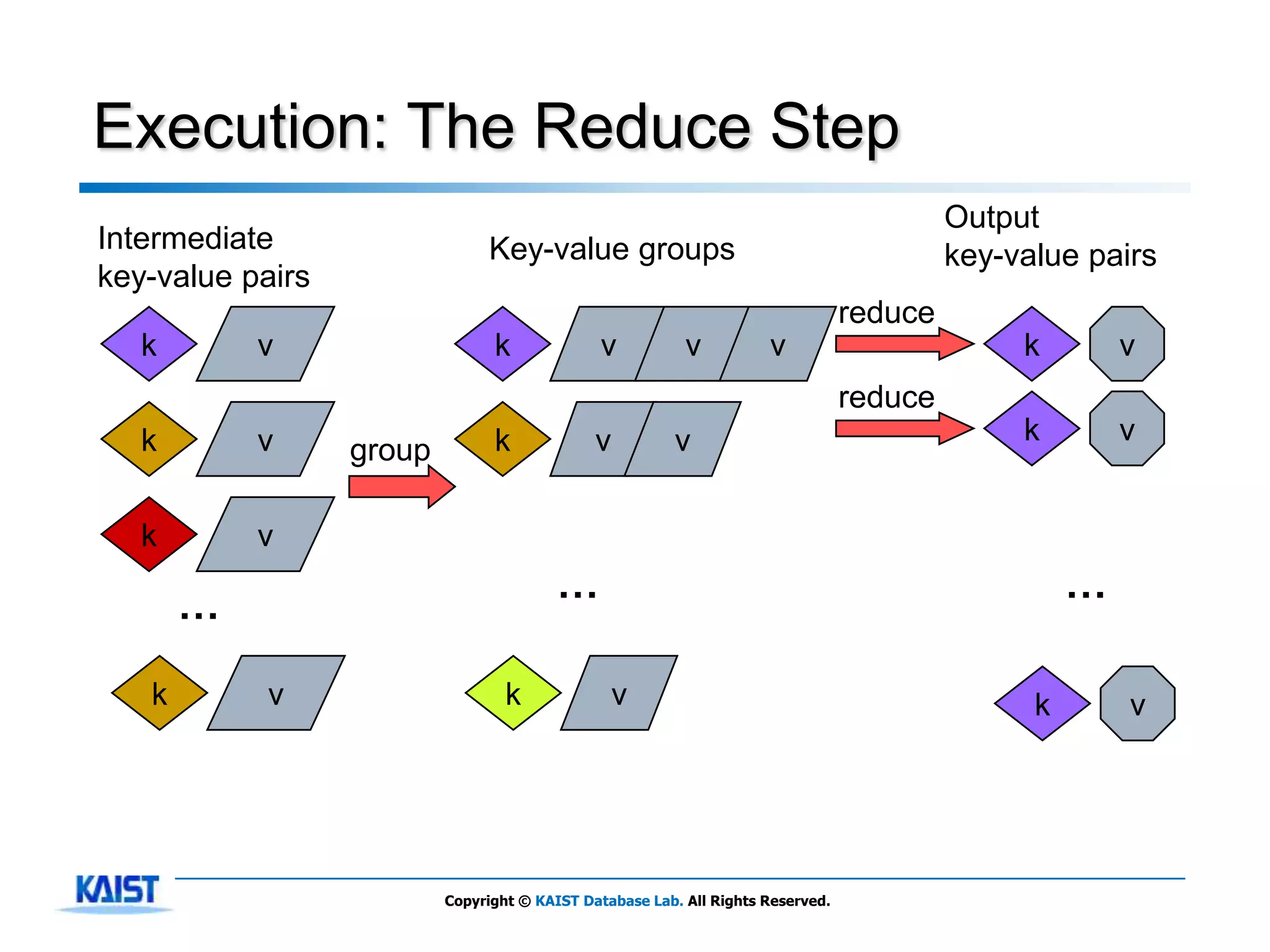
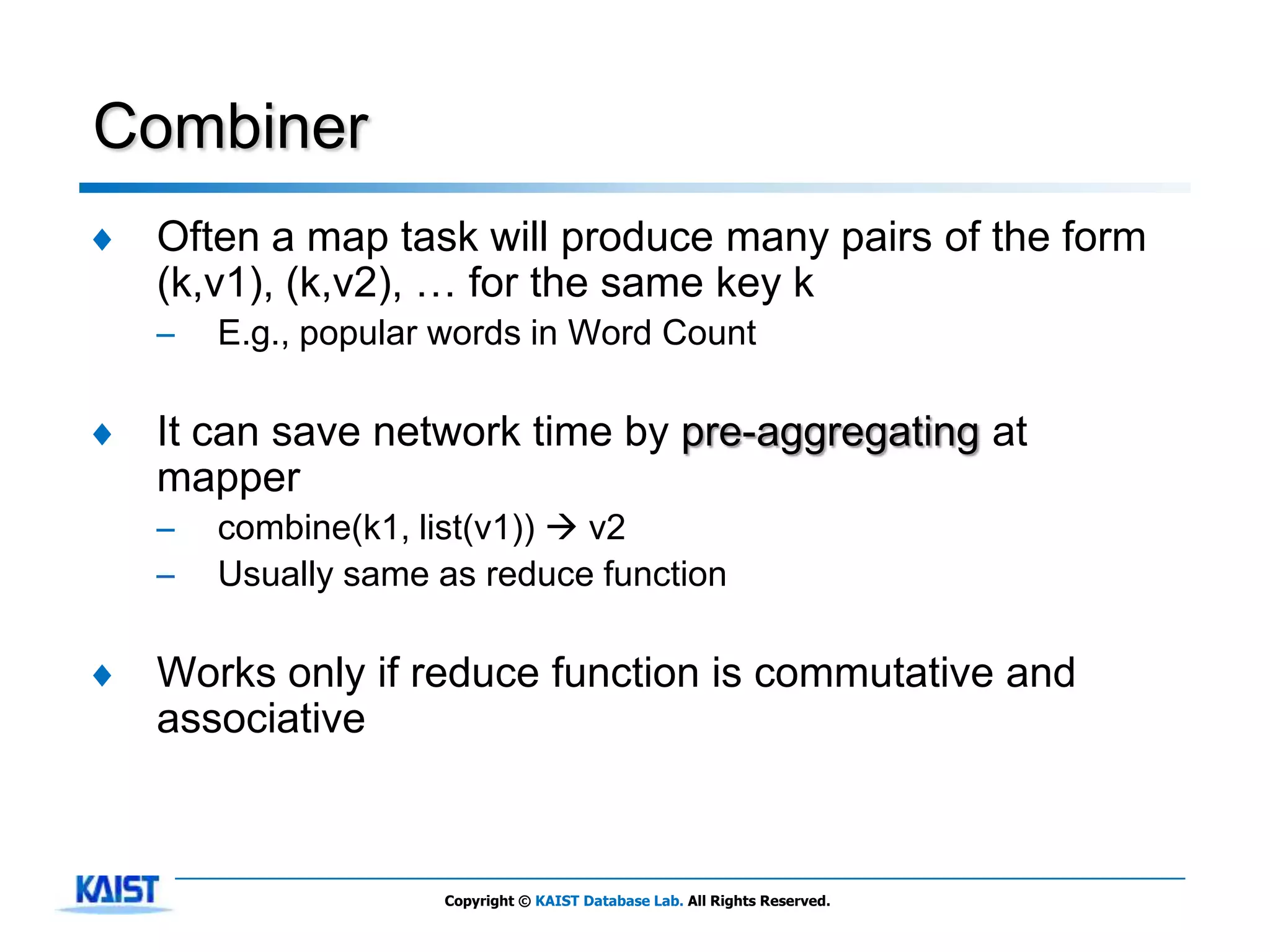
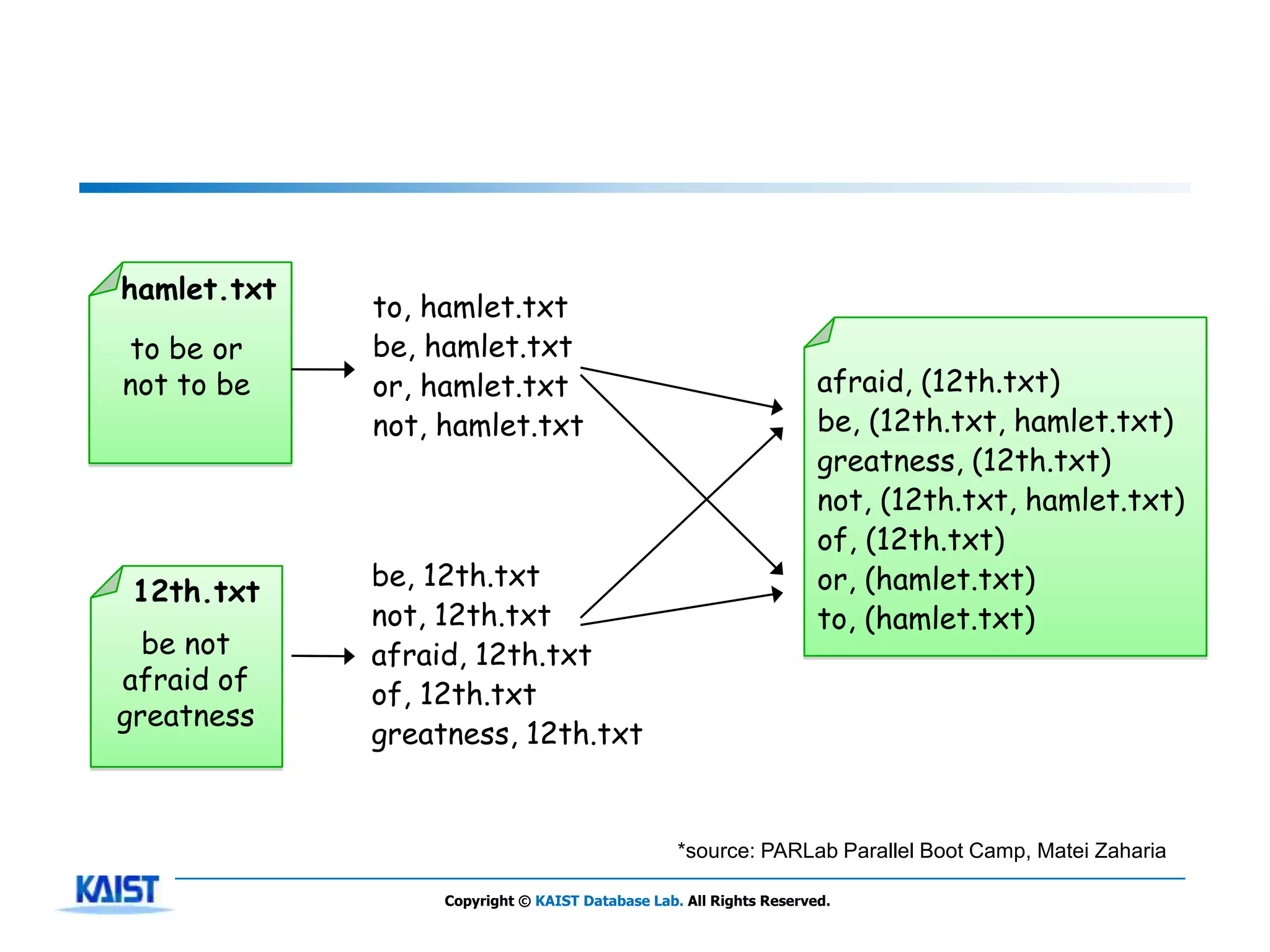
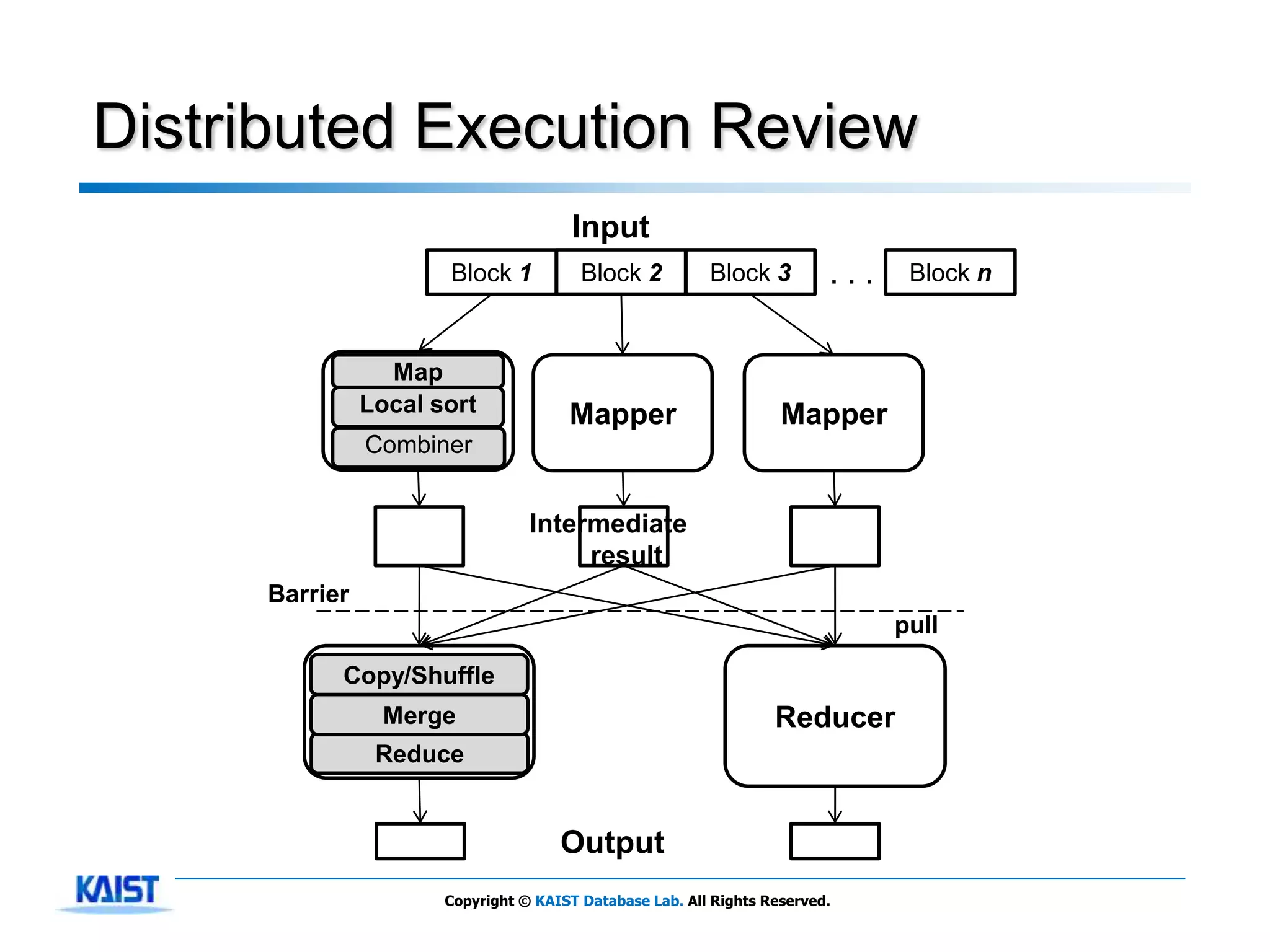
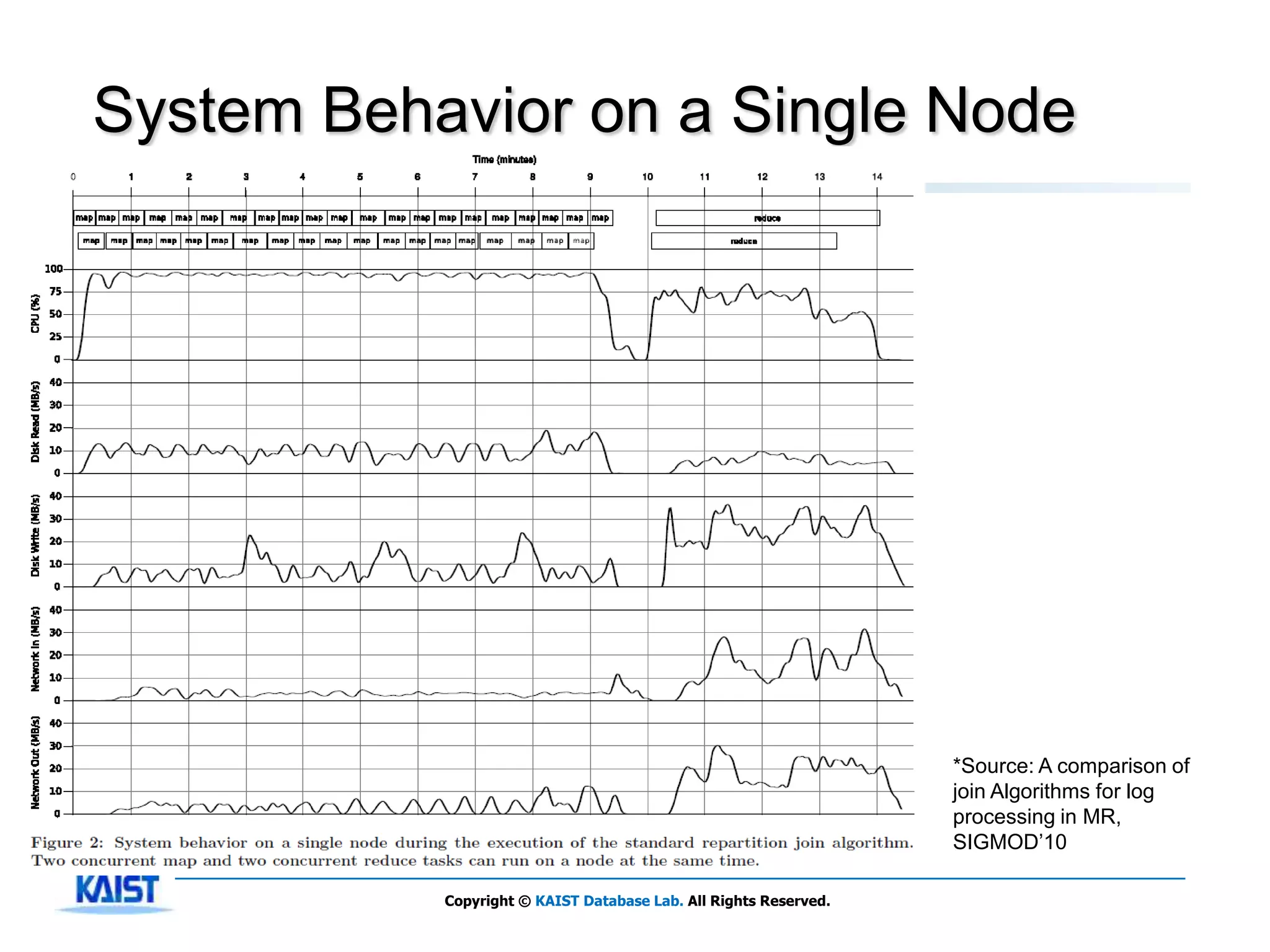
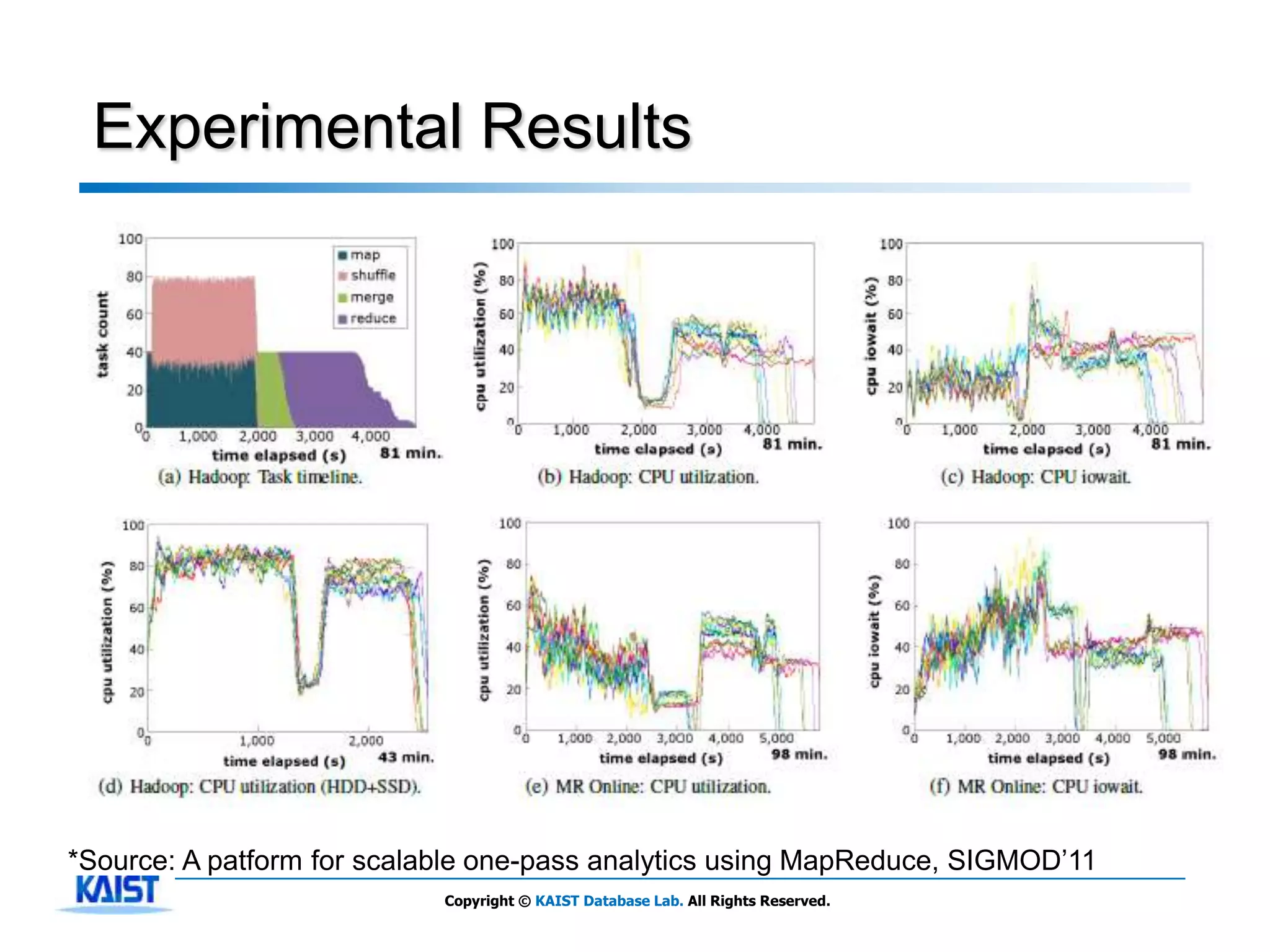
The document discusses MapReduce, a framework for processing large datasets in parallel. It provides an overview of MapReduce's basic principles, surveys research to improve the conventional MapReduce framework, and describes research projects ongoing at KAIST. The key points are that MapReduce provides automatic parallelization, fault tolerance, and distributed processing of large datasets across commodity computer clusters. It also introduces the map and reduce functions that define MapReduce jobs.
























































![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)










![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)

