Download as ODP, PPTX














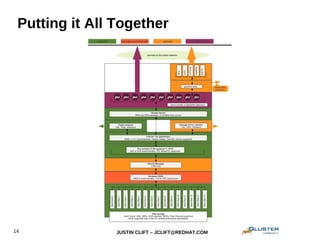





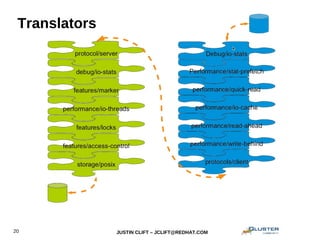



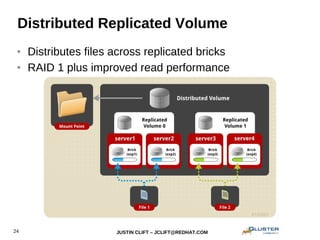
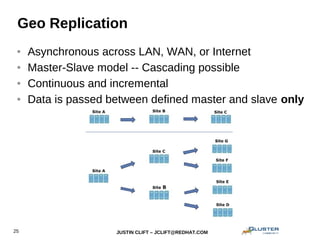


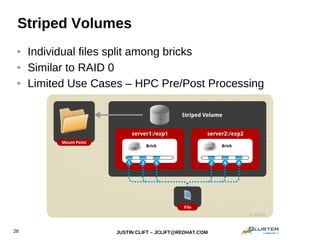
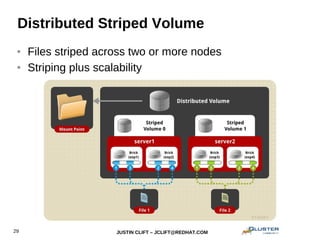
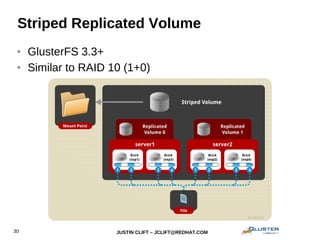









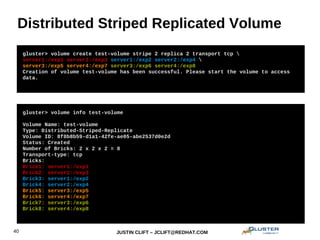




















This document provides an overview and introduction to GlusterFS for system administrators. It covers the key topics of GlusterFS technology, scaling, architecture, data distribution and redundancy features, administration tasks like adding nodes and volumes, and general use cases. The presentation is aimed at experienced sysadmins helping them understand and deploy GlusterFS distributed file systems.






































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



