Download as PDF, PPTX






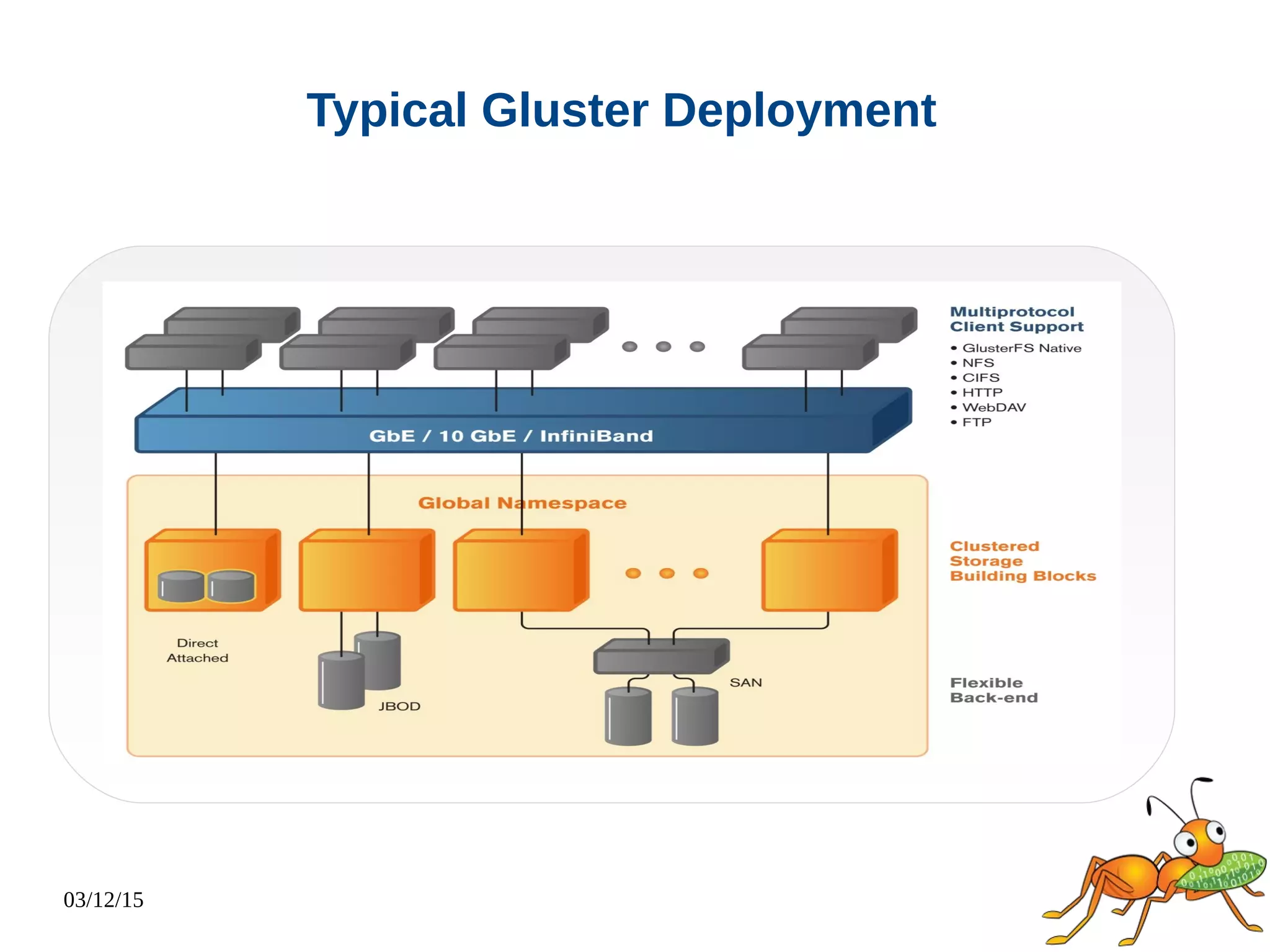


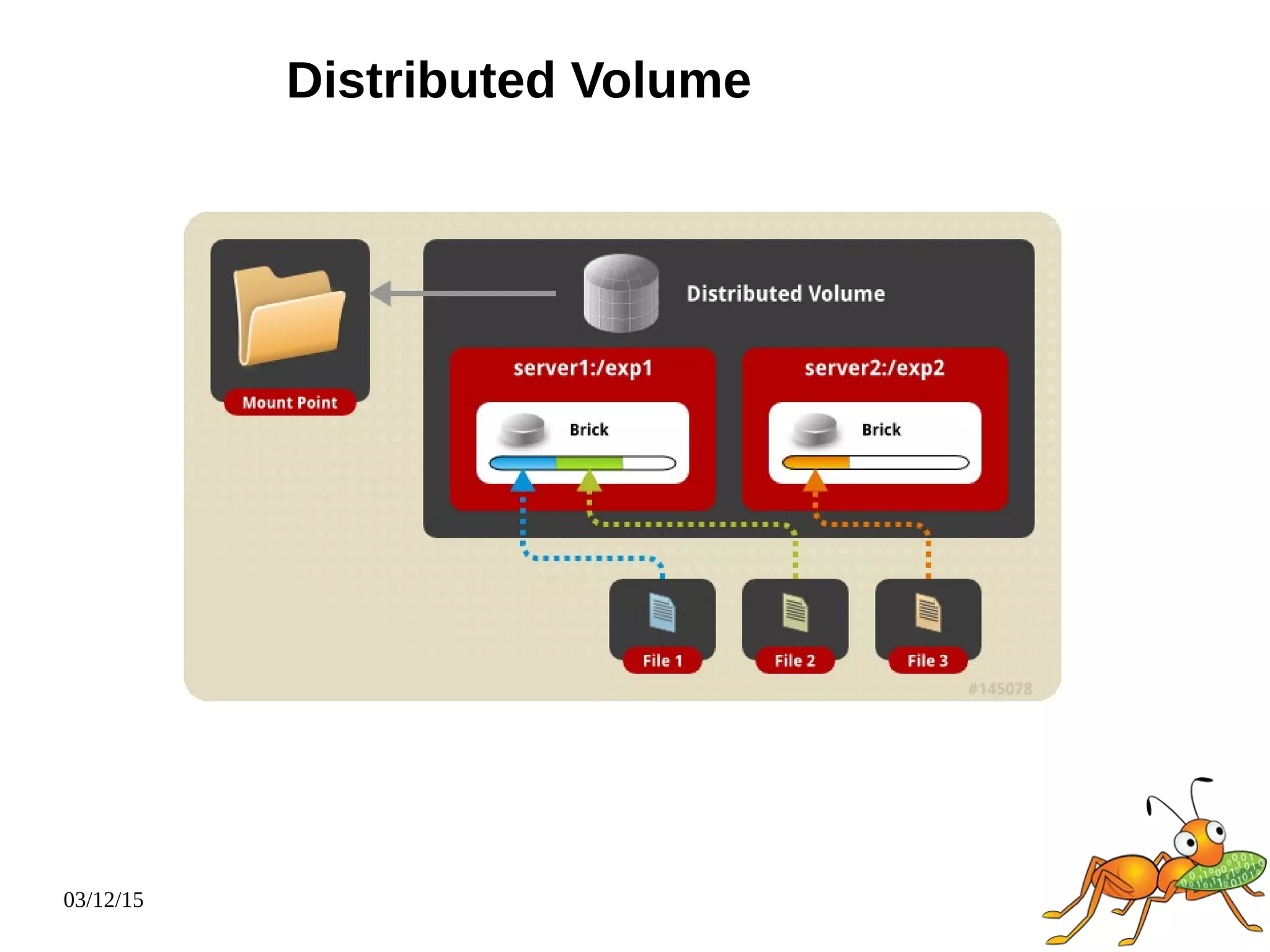
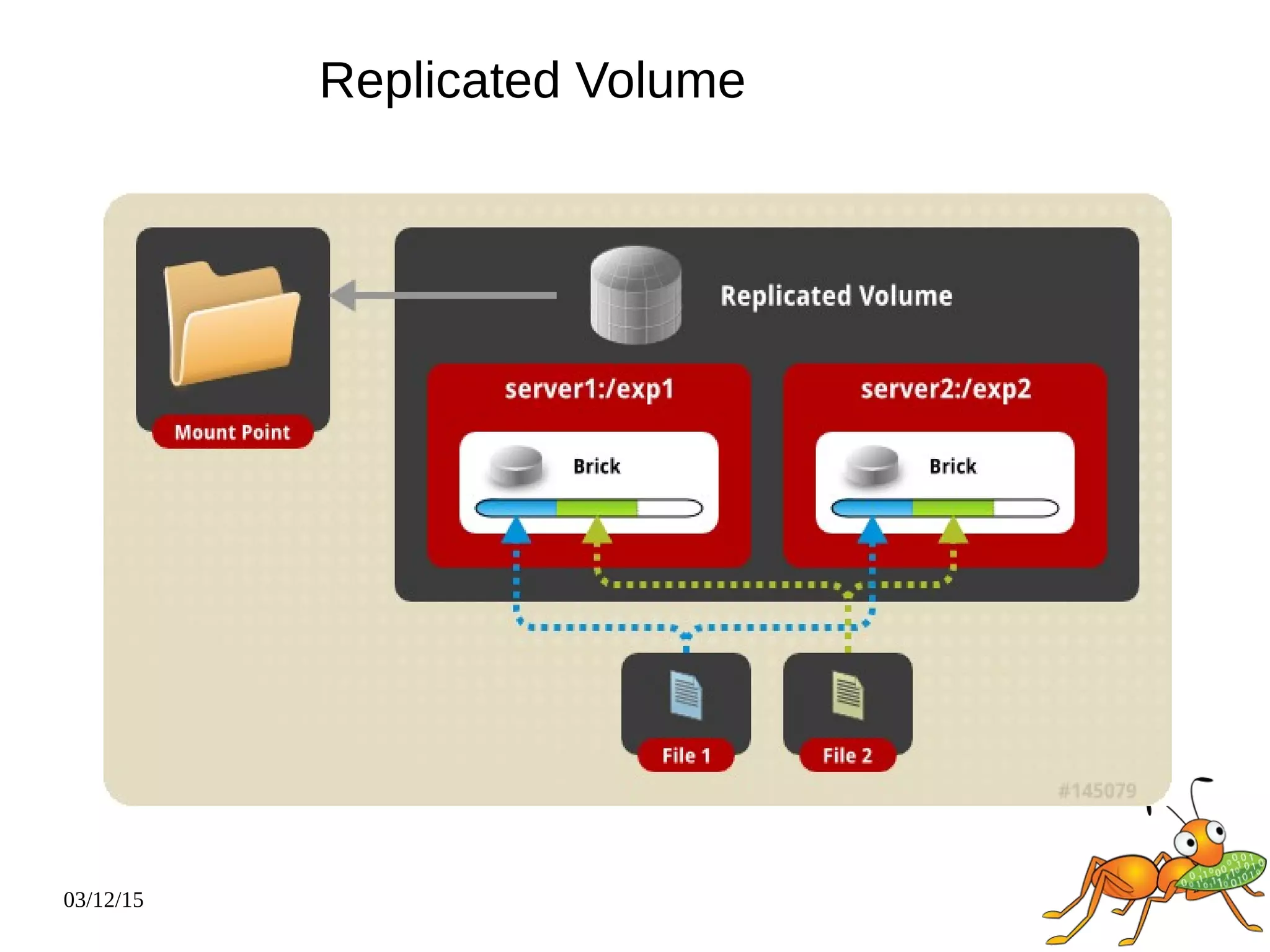
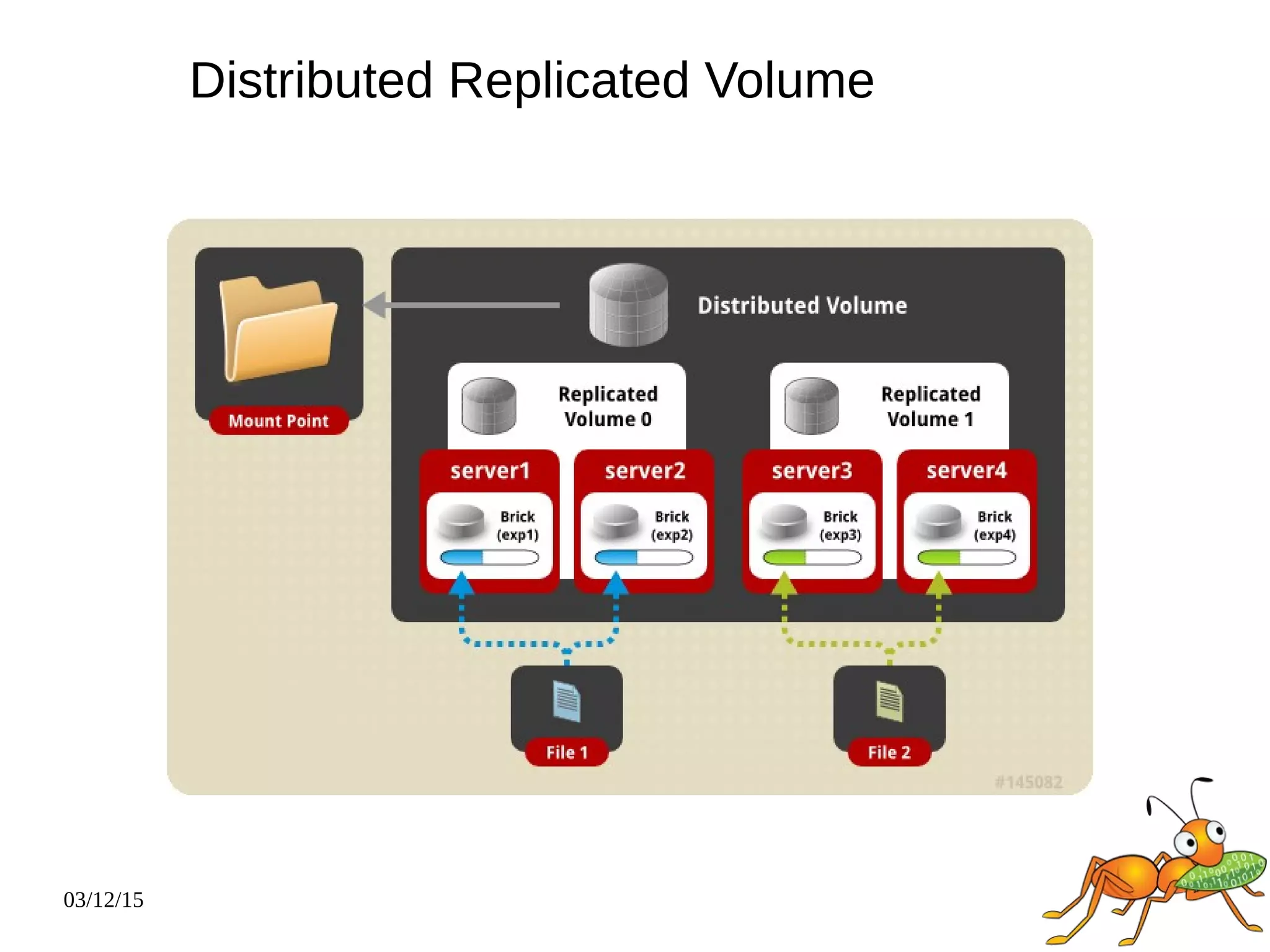


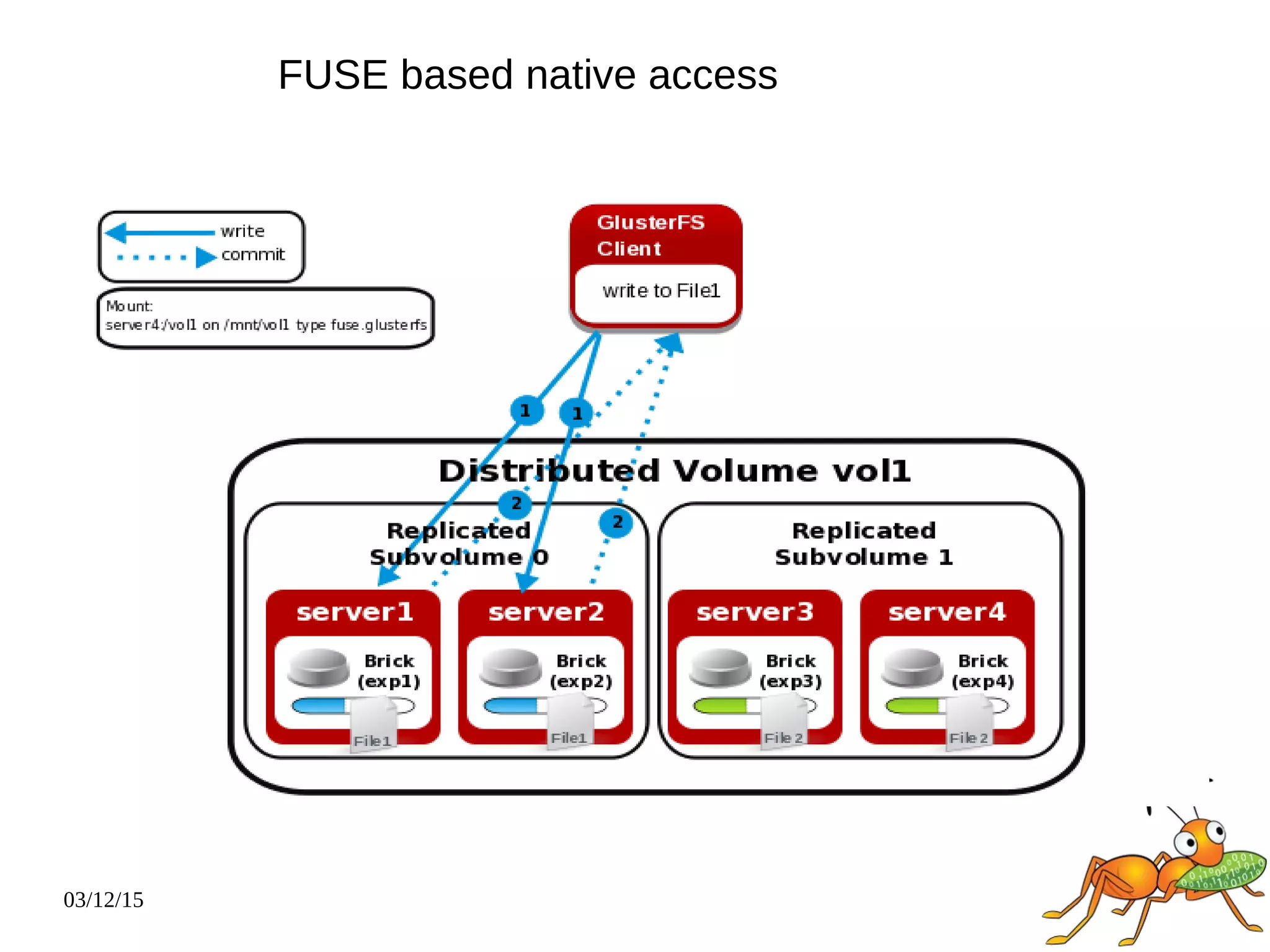
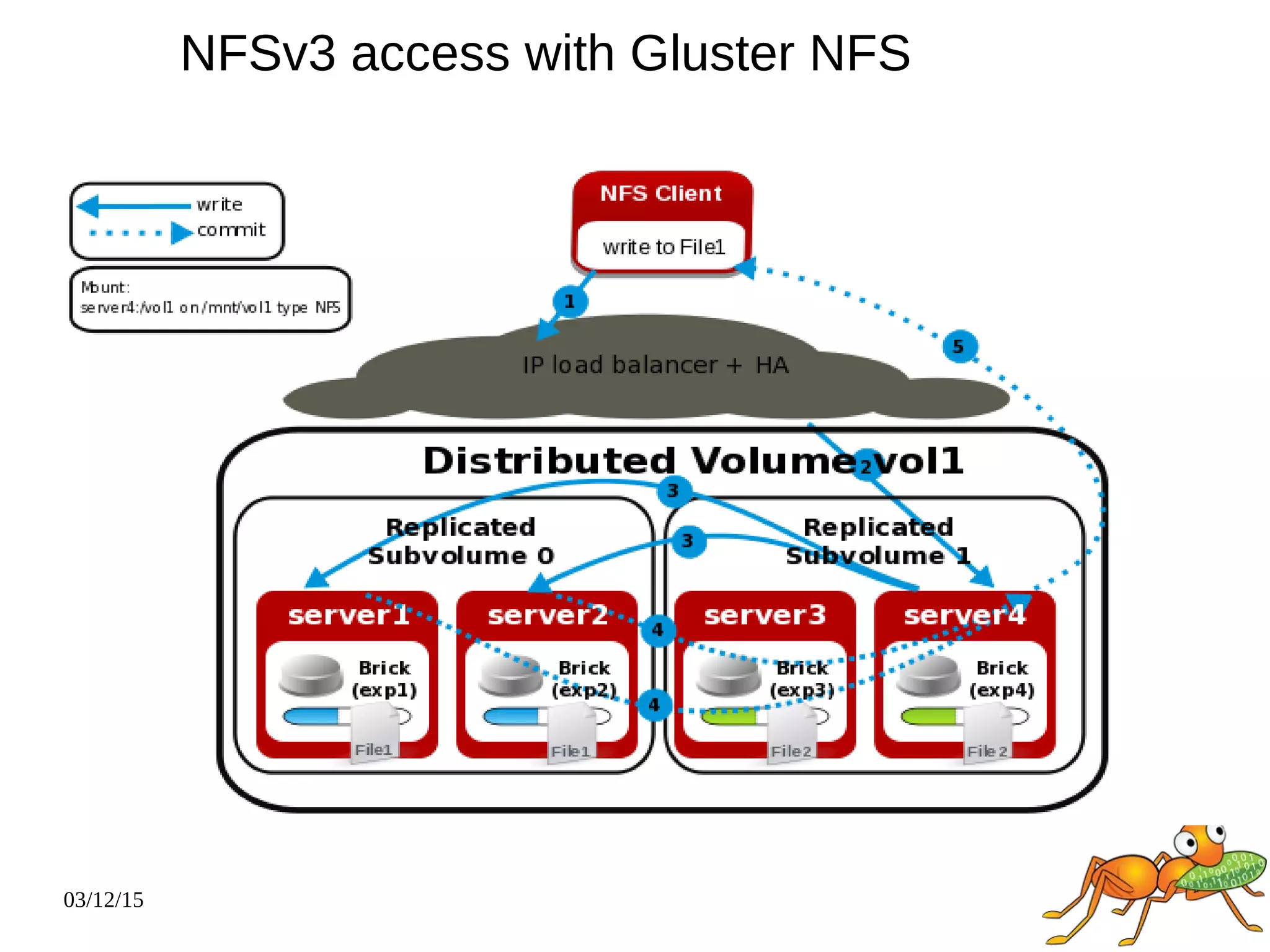
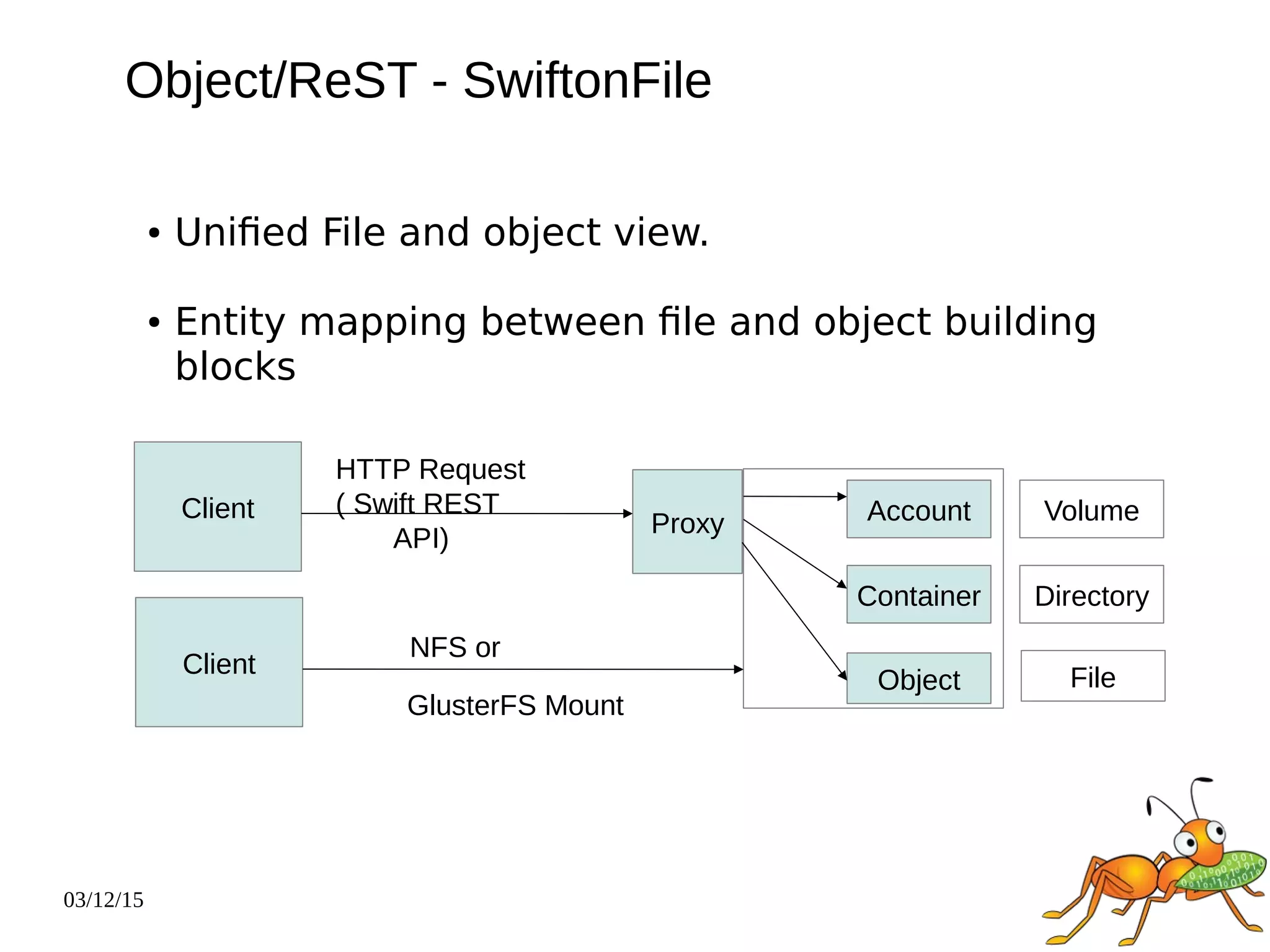
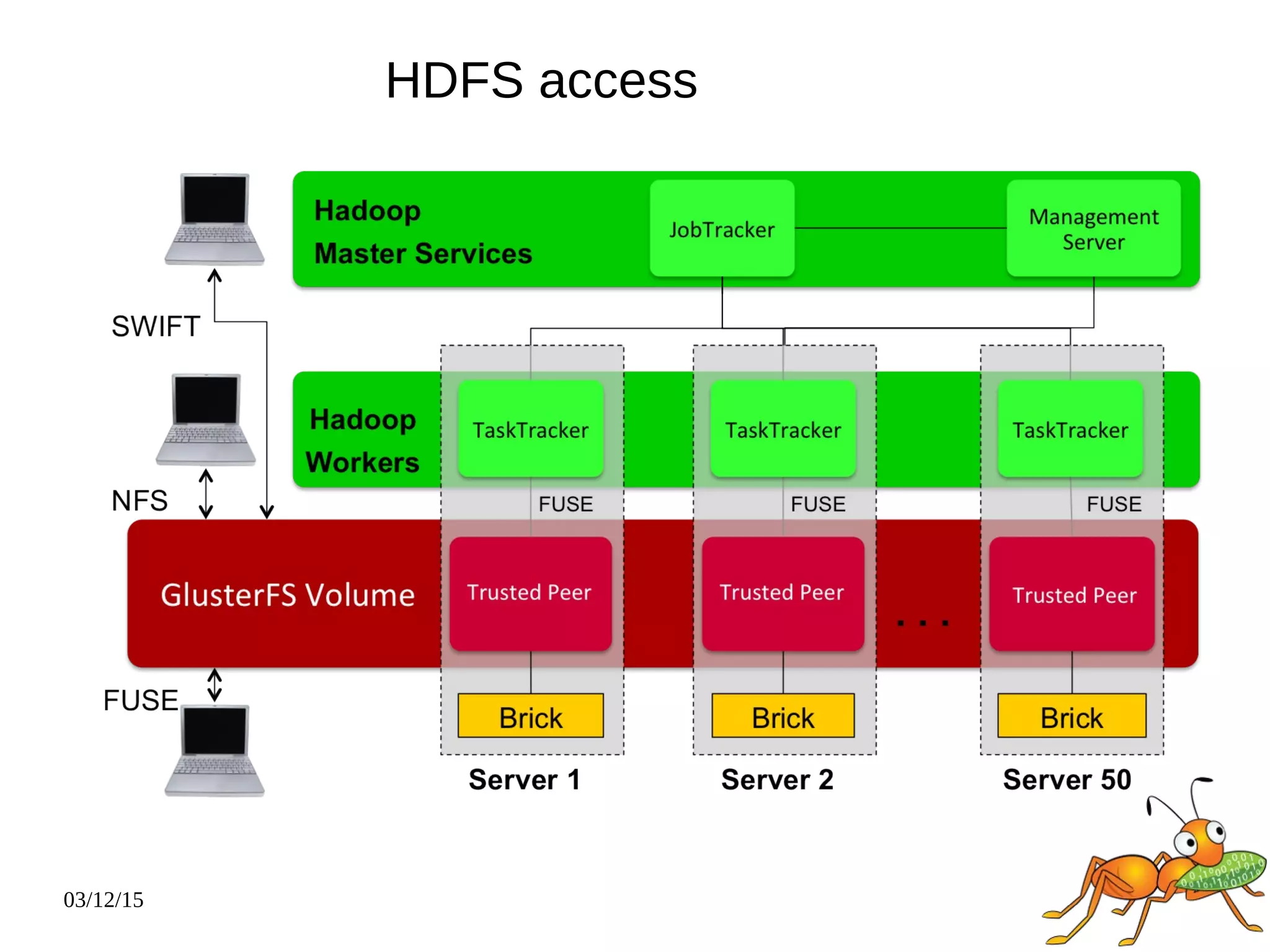
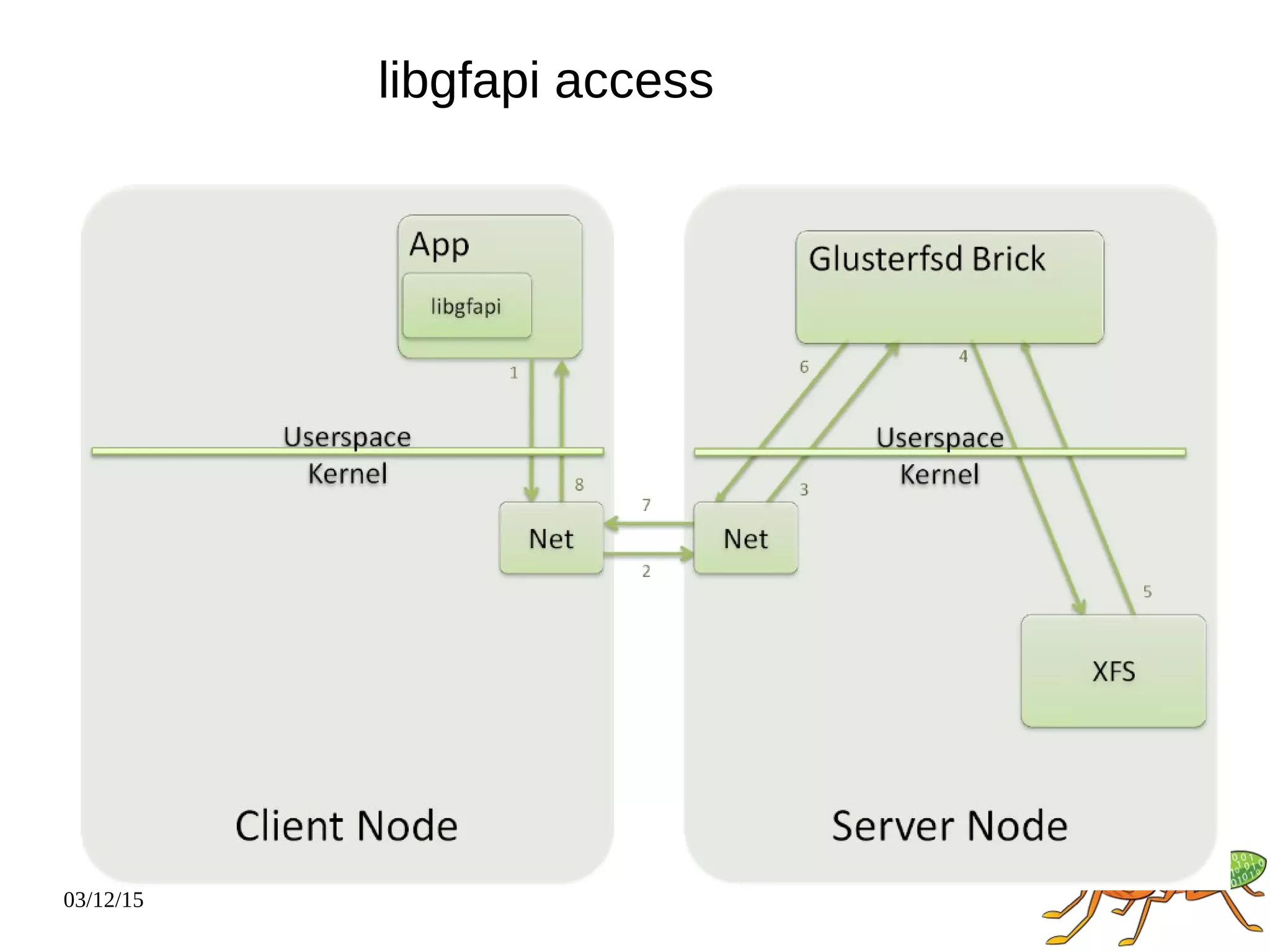
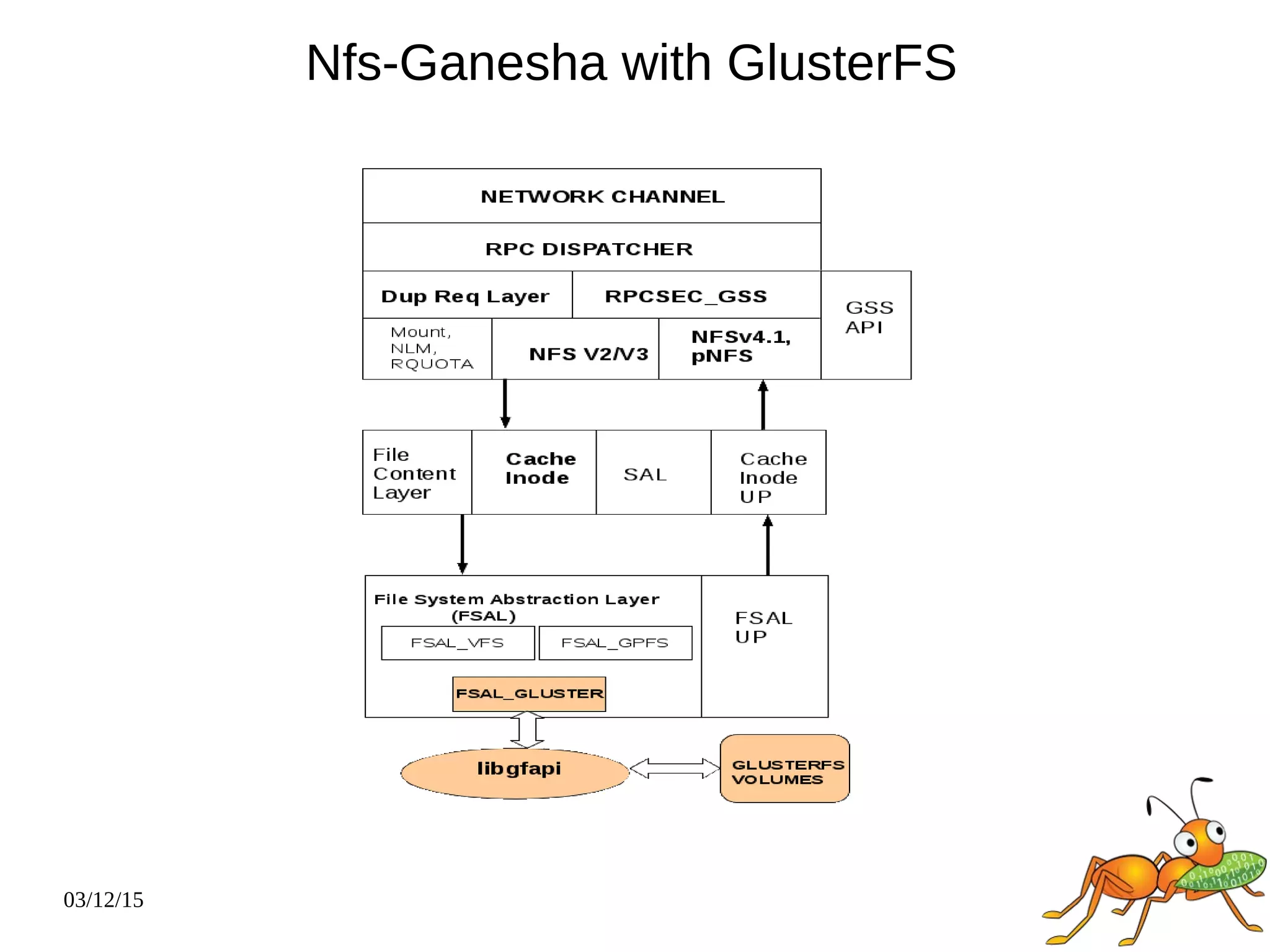
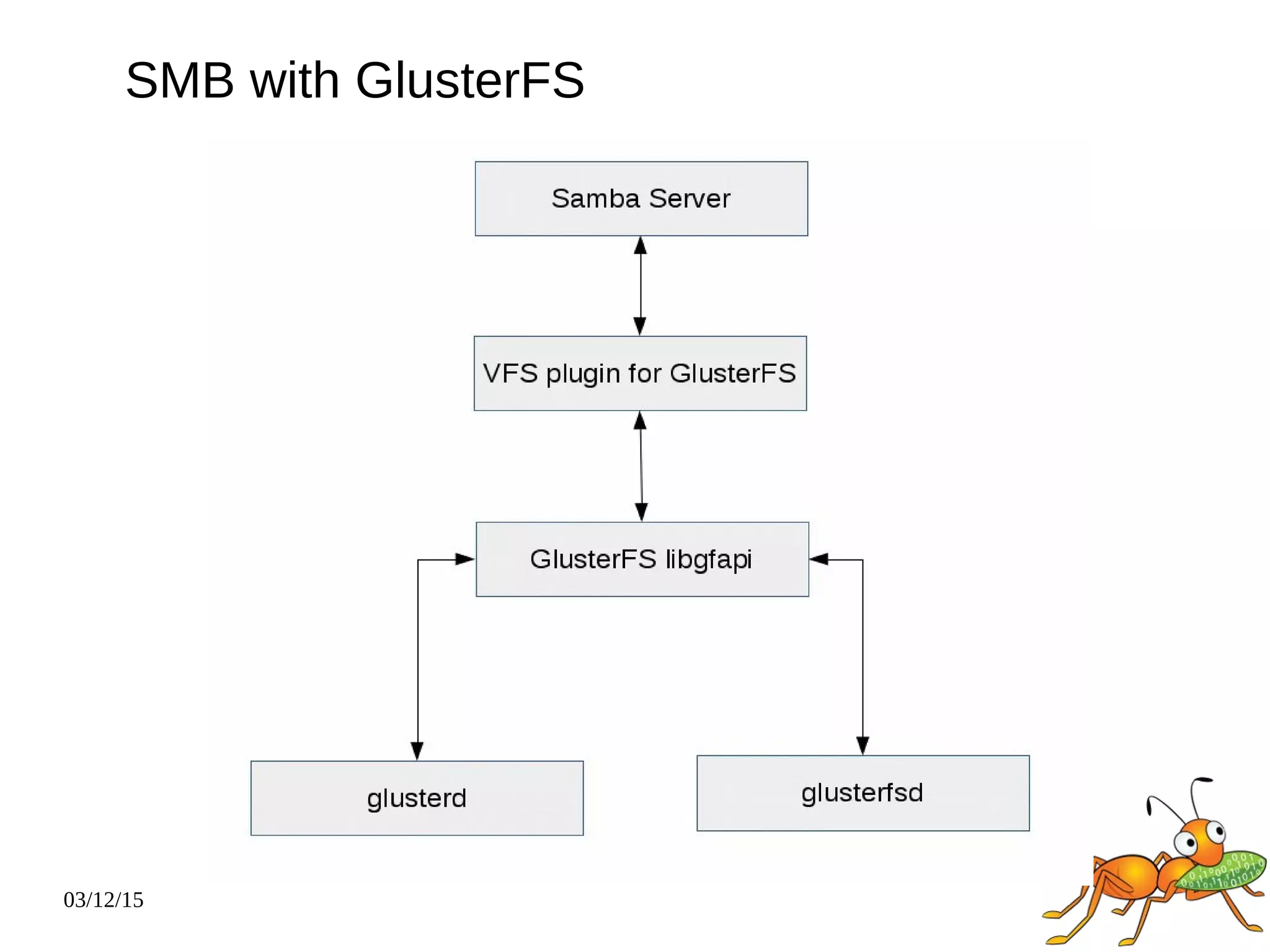
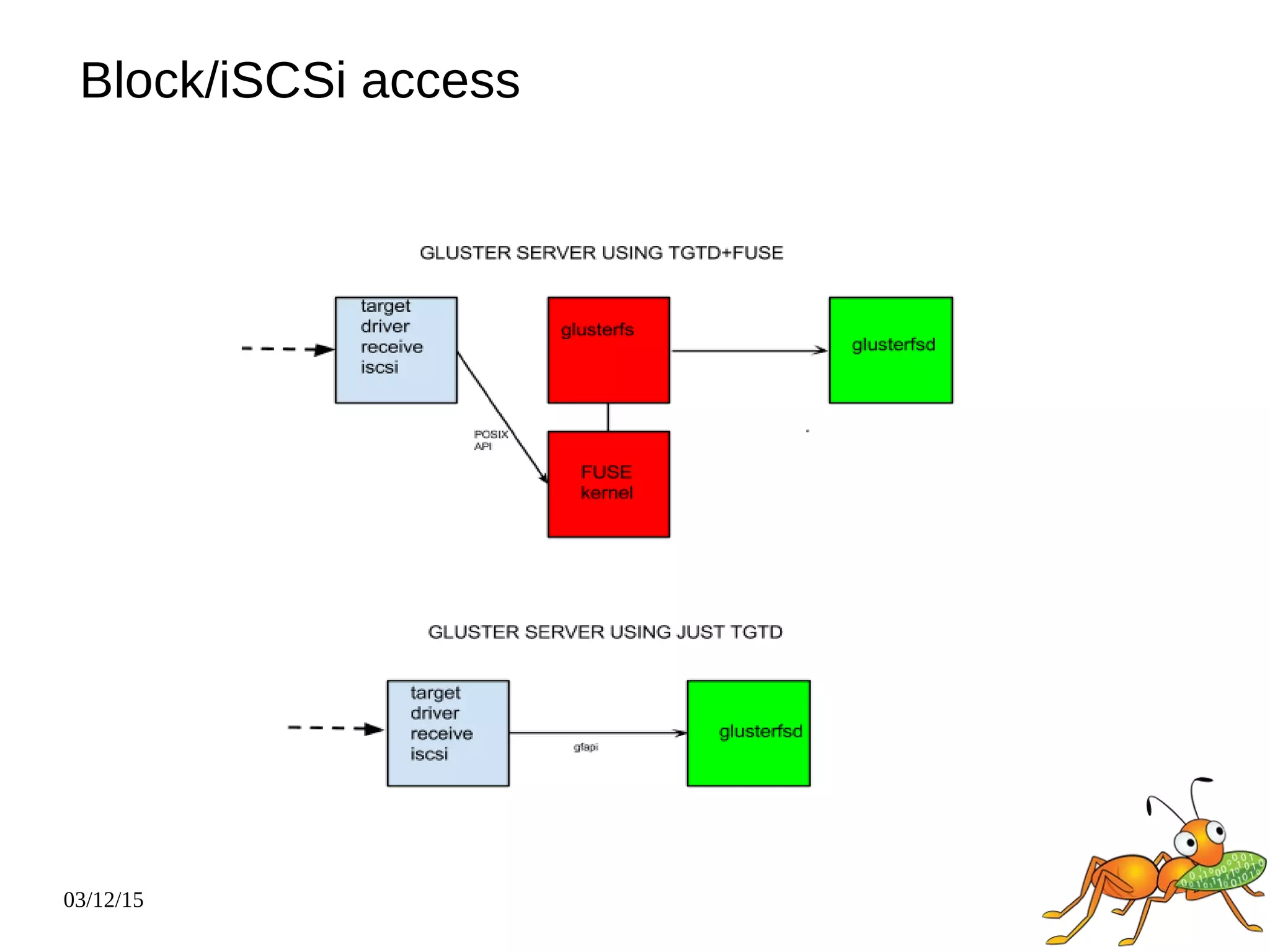


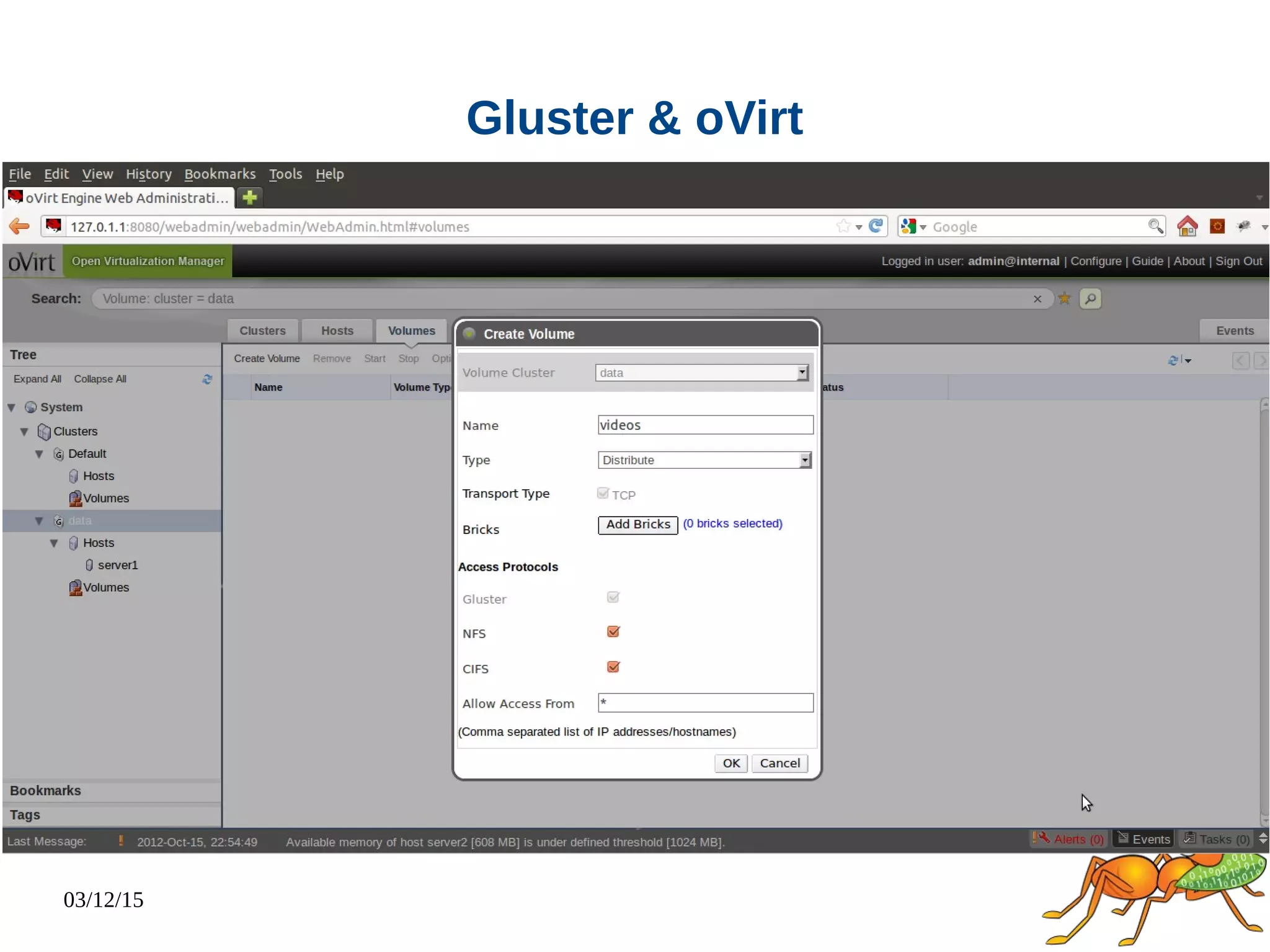



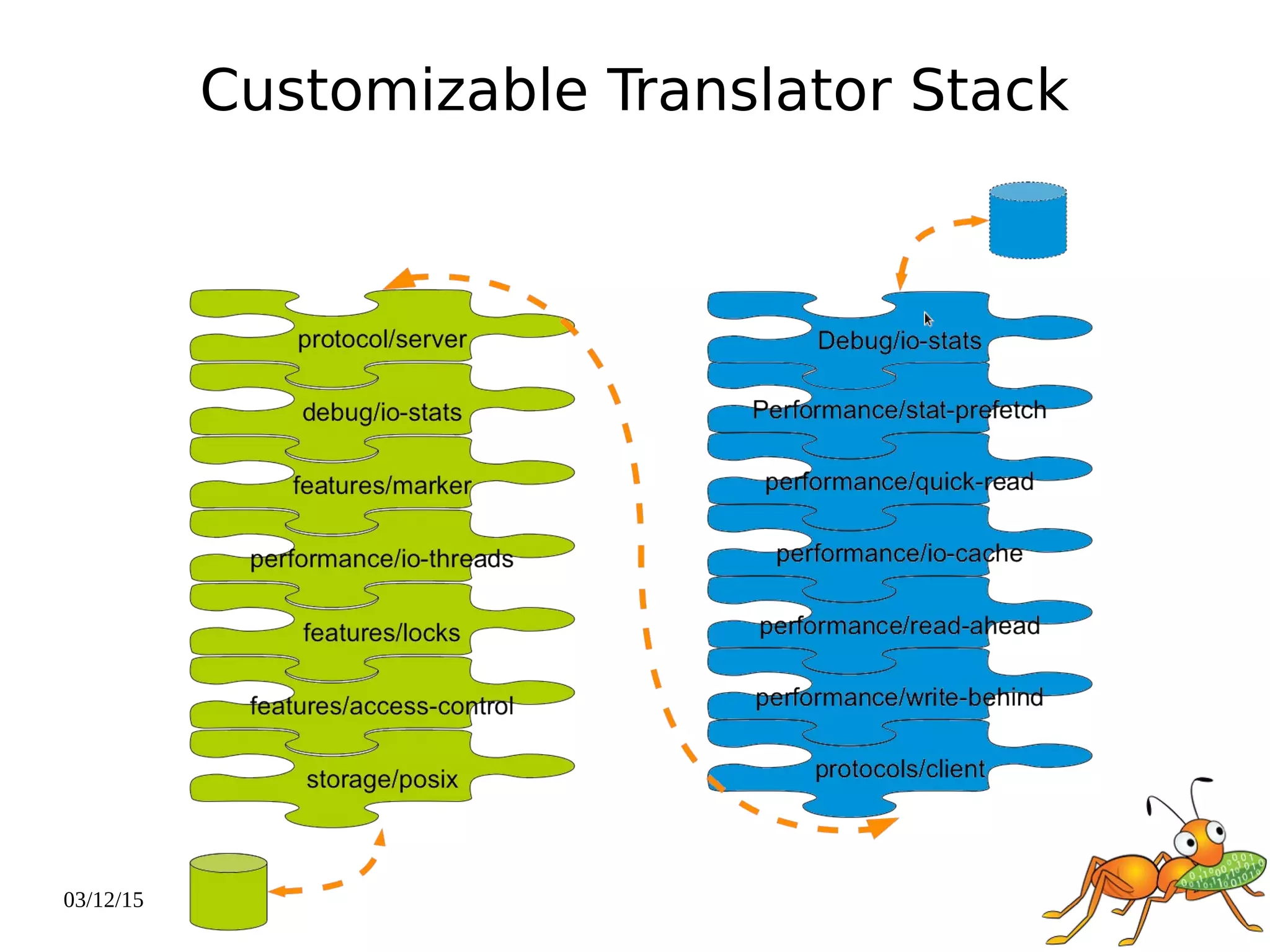

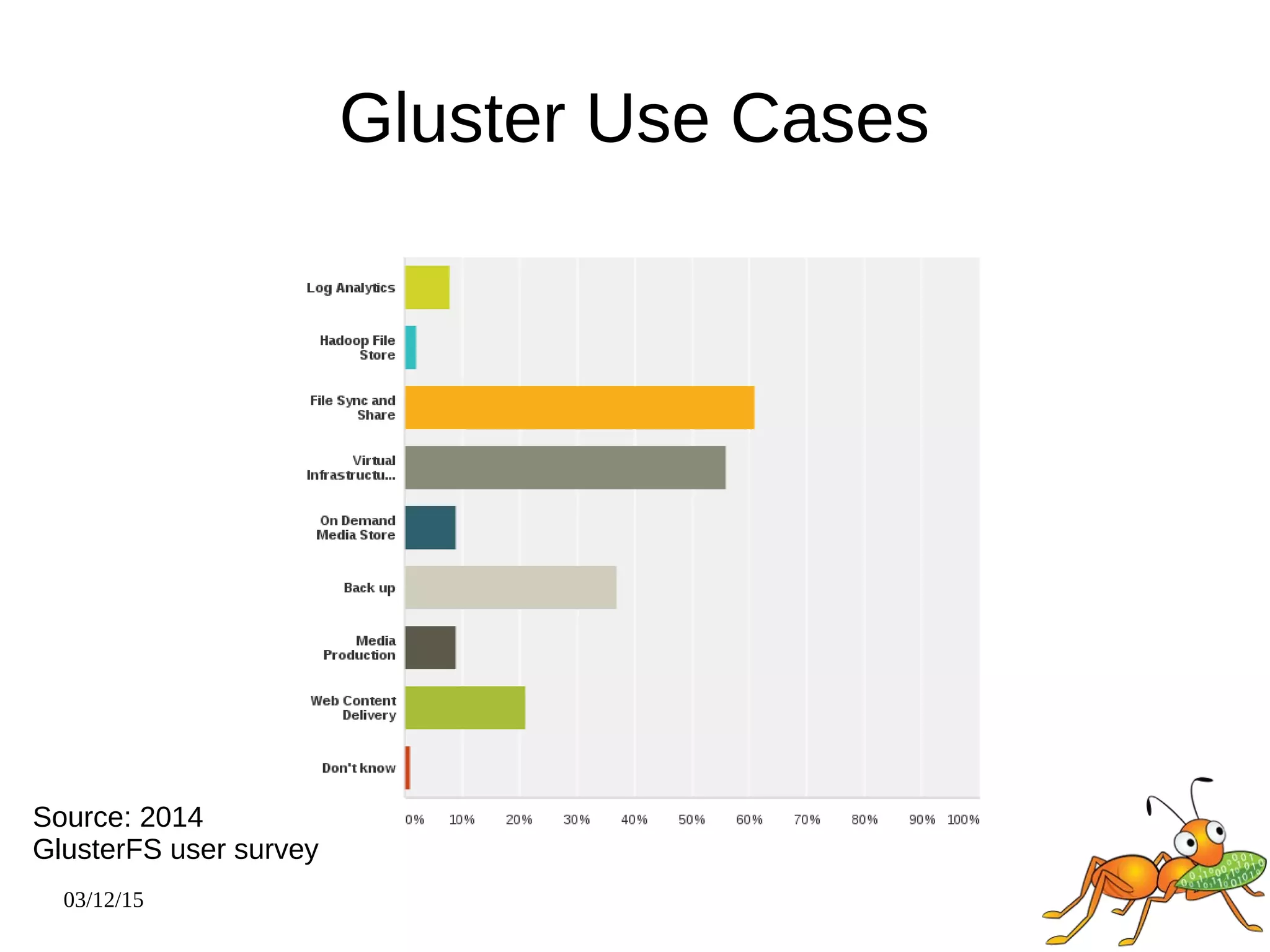




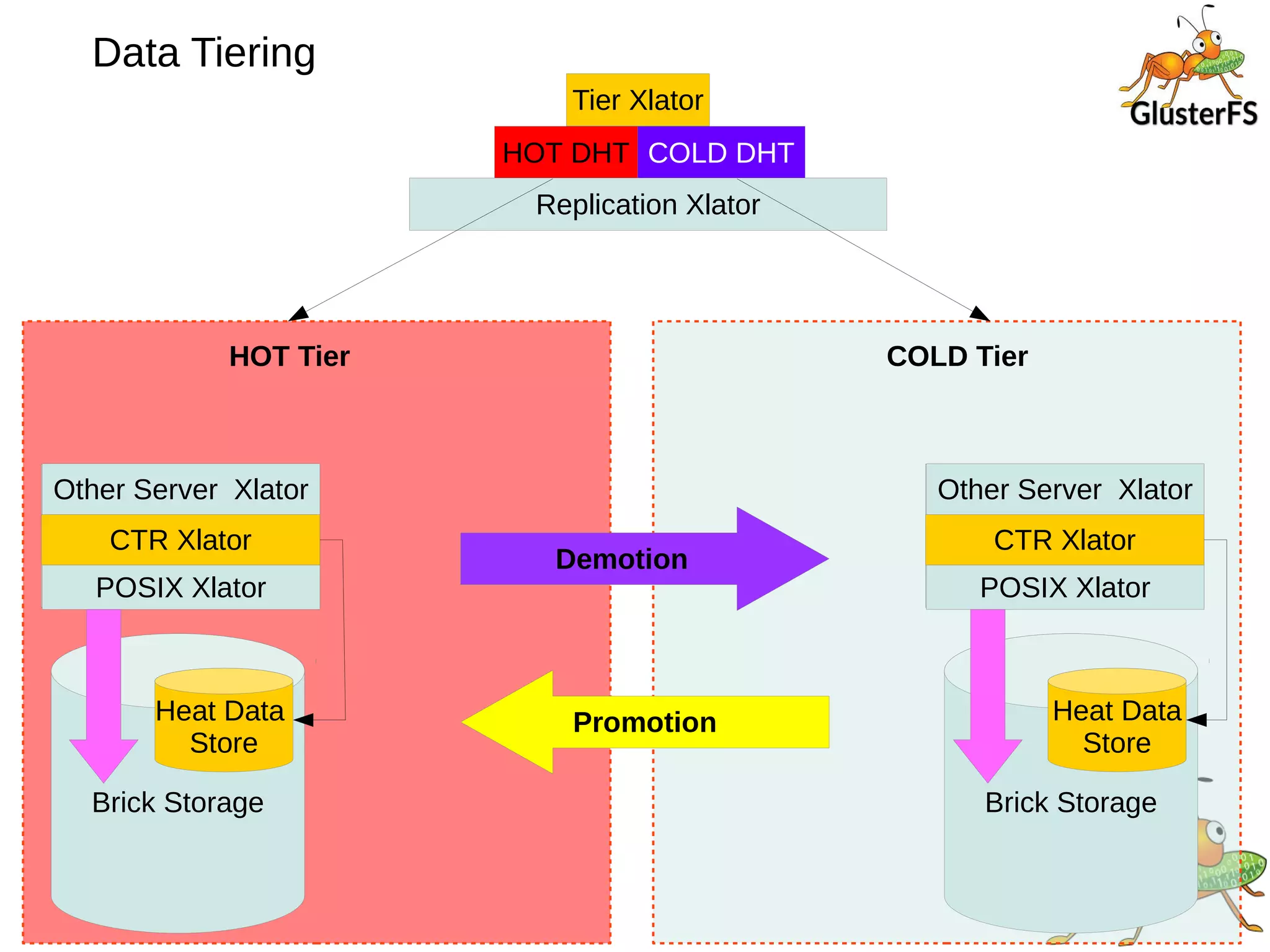










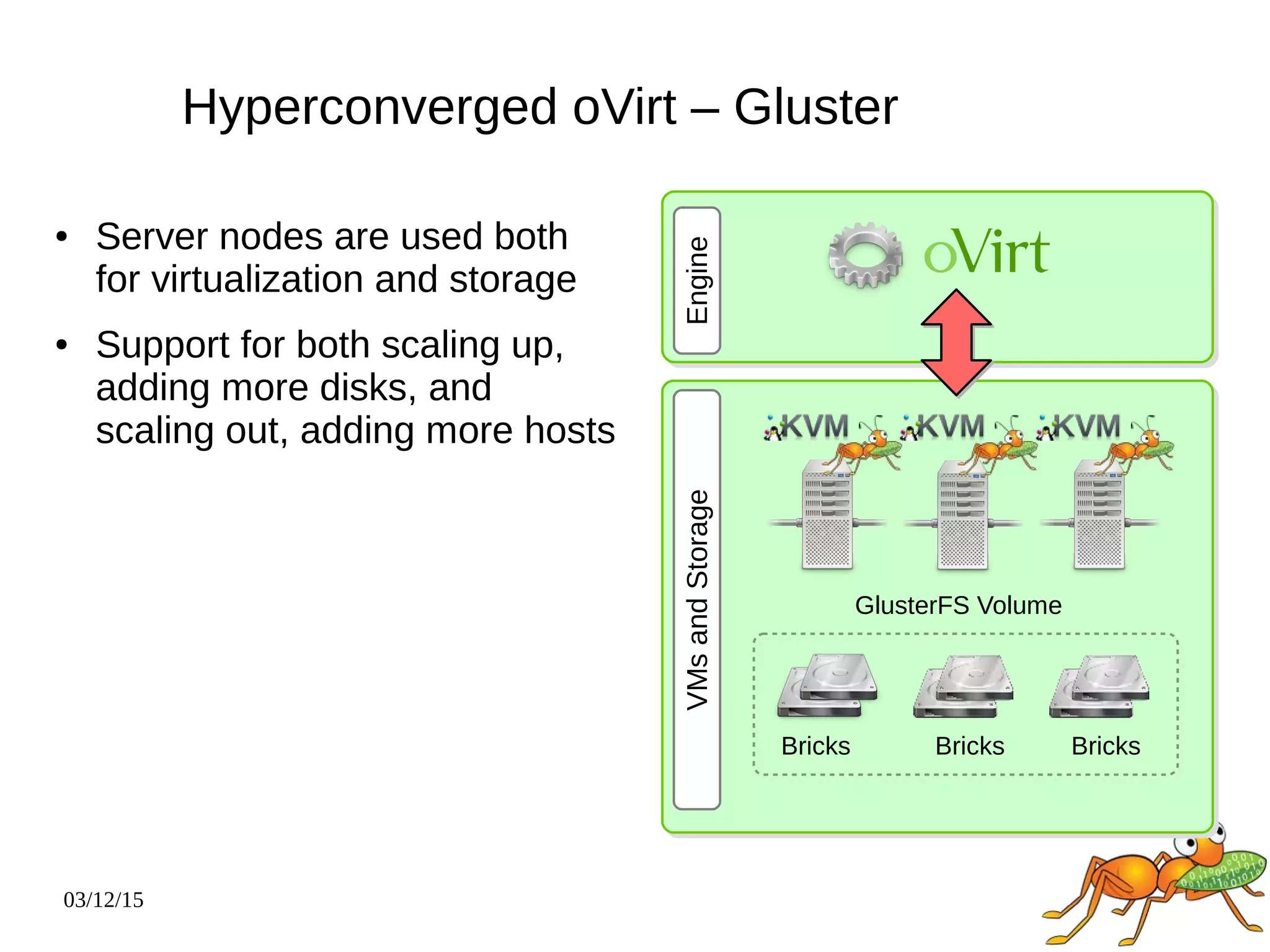

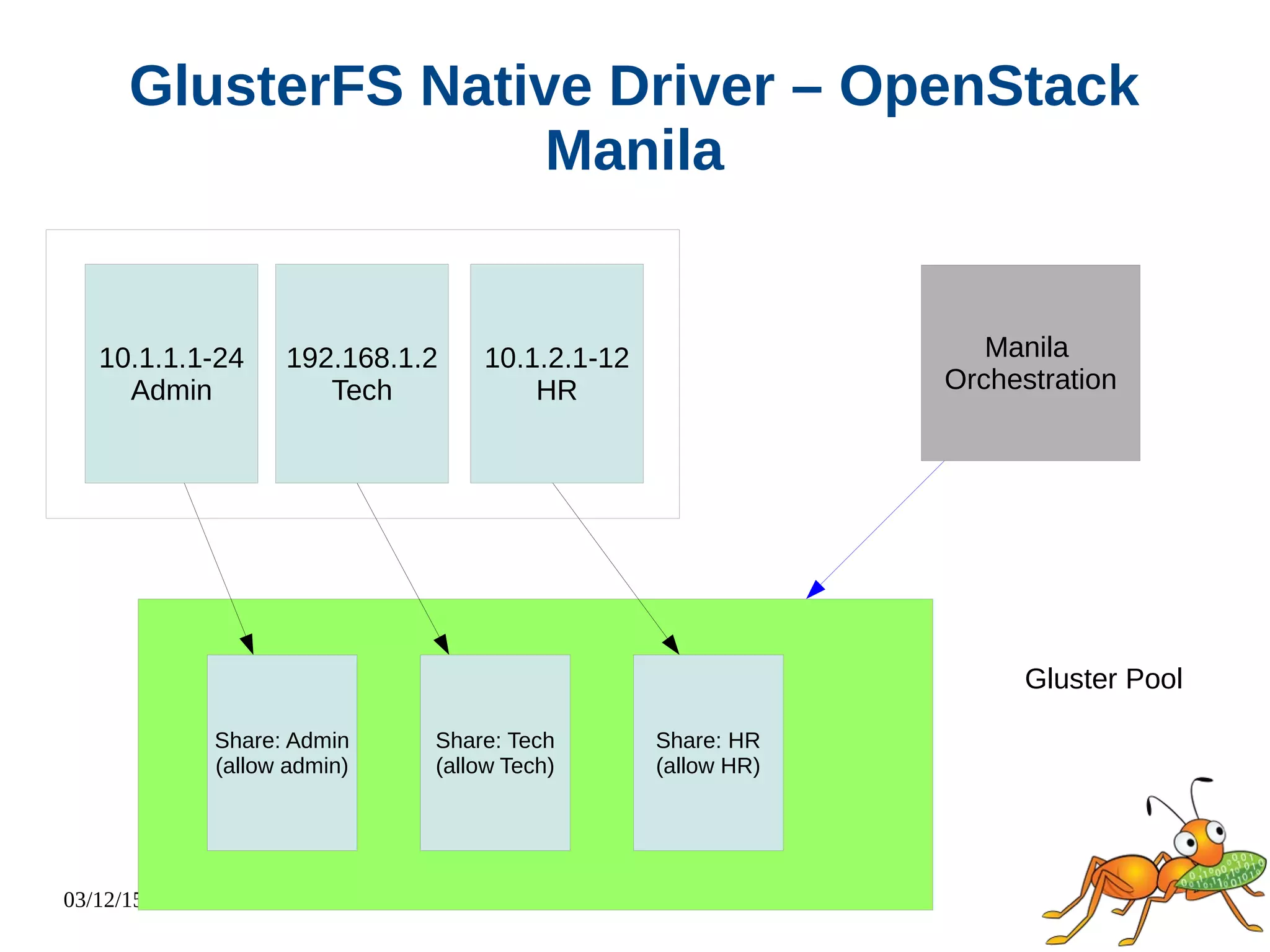
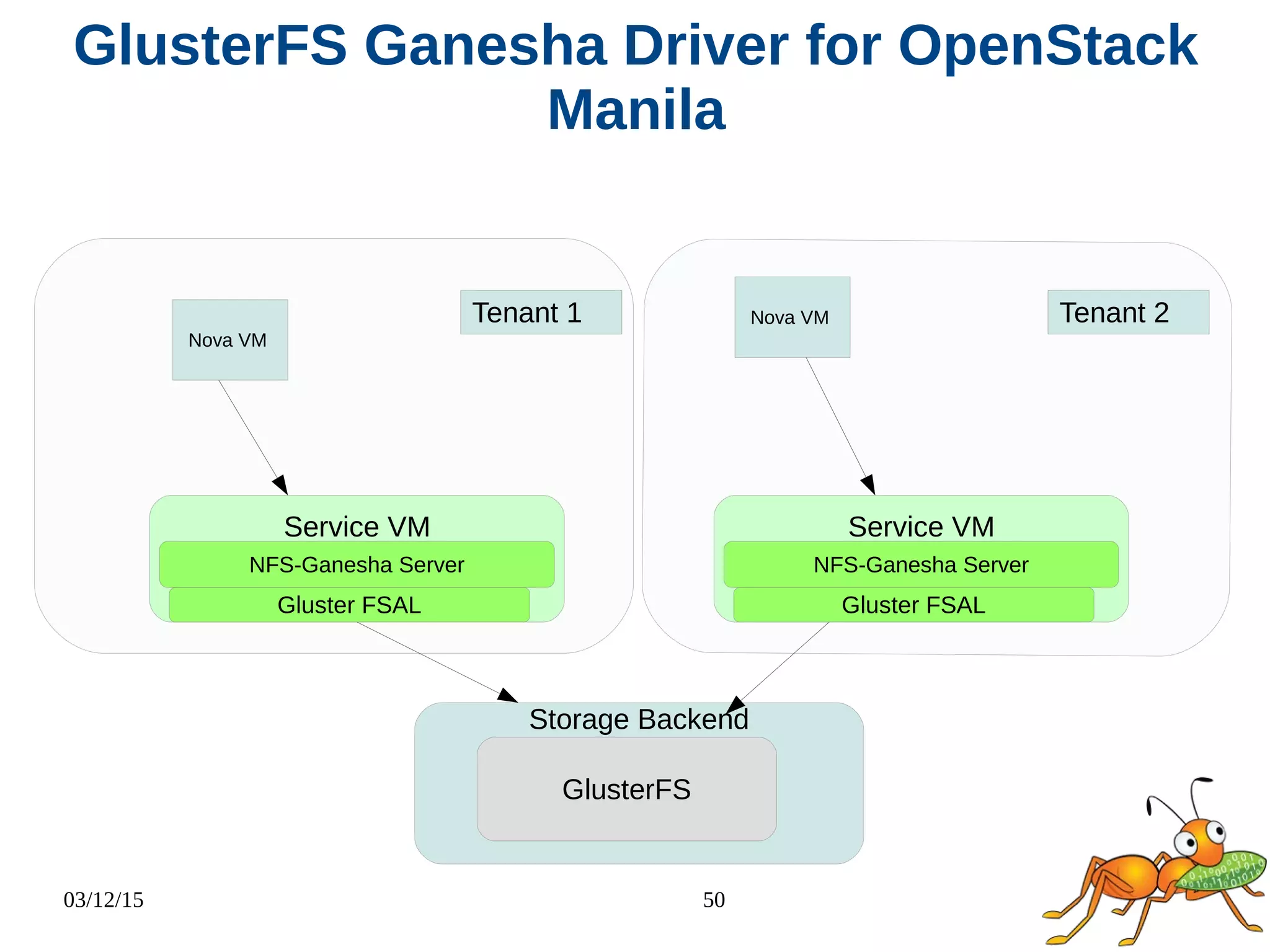



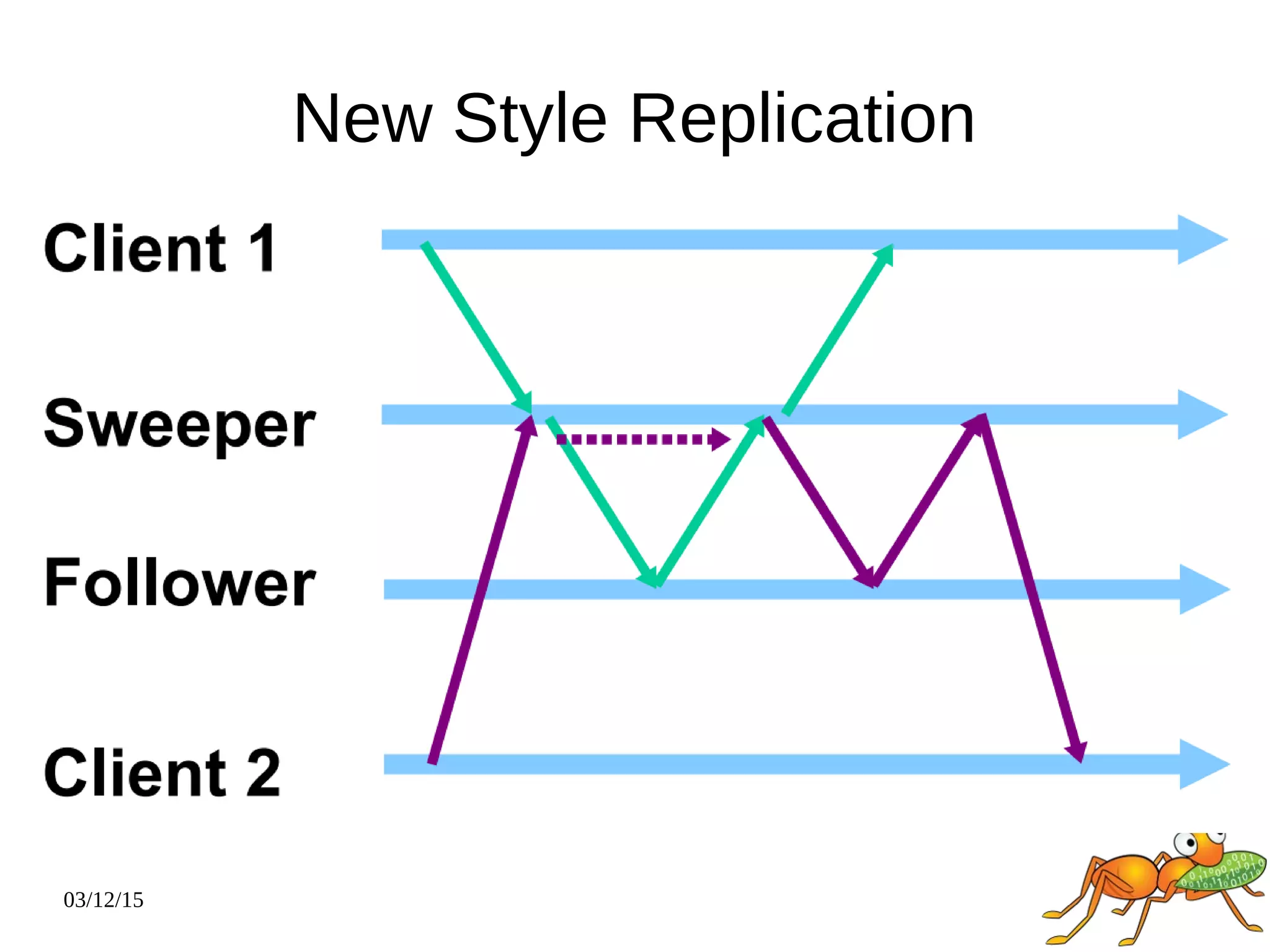








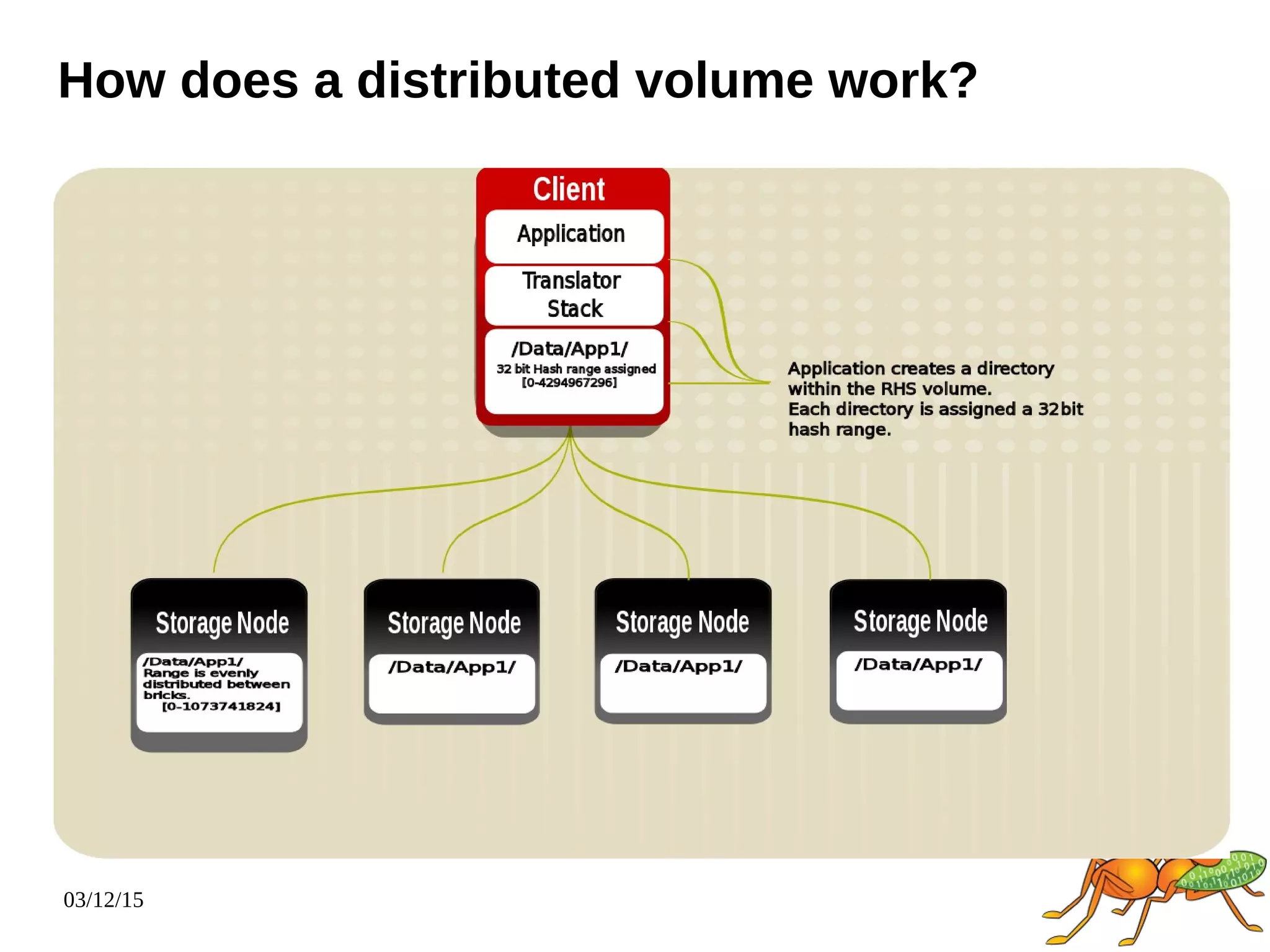
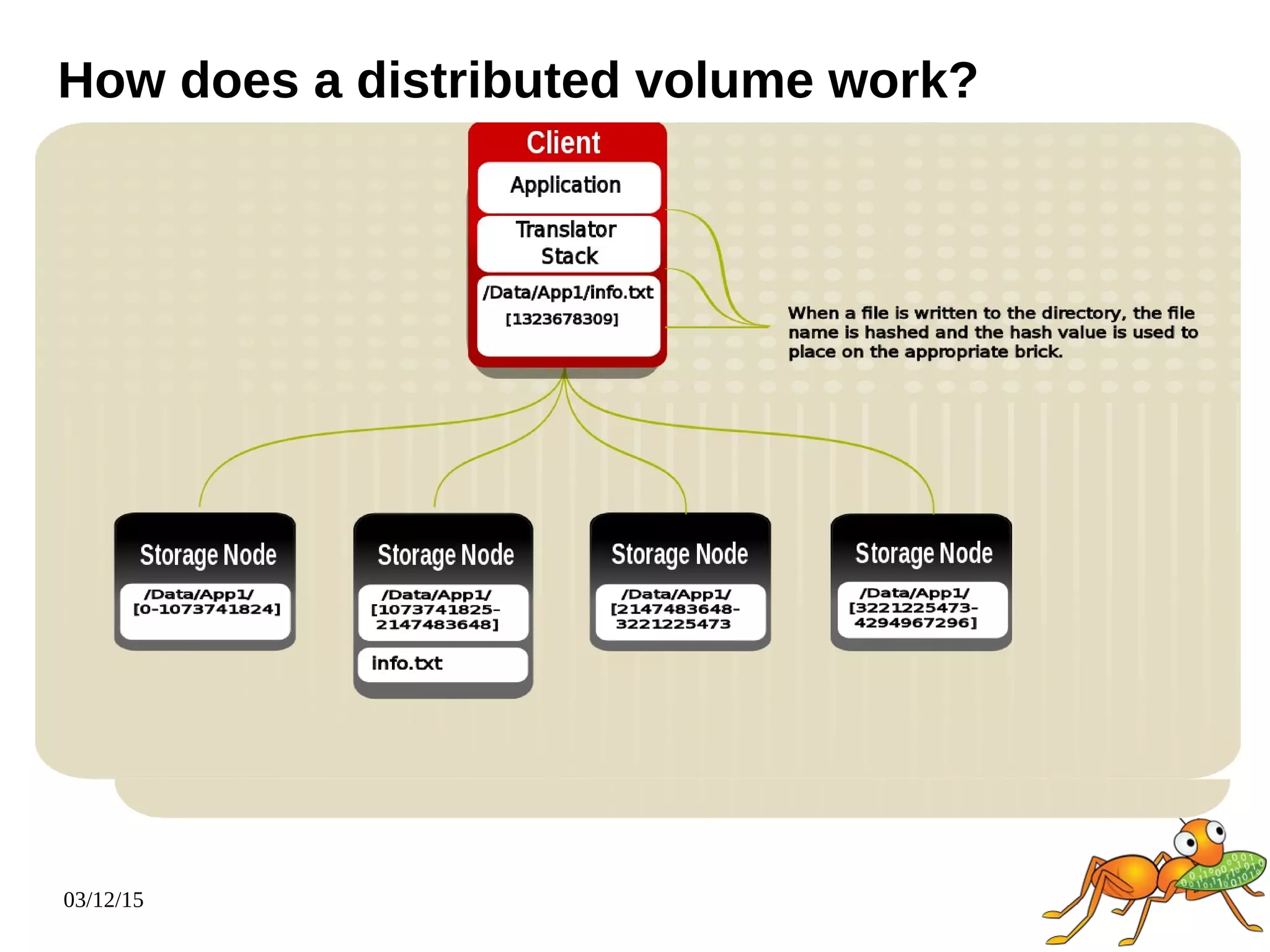
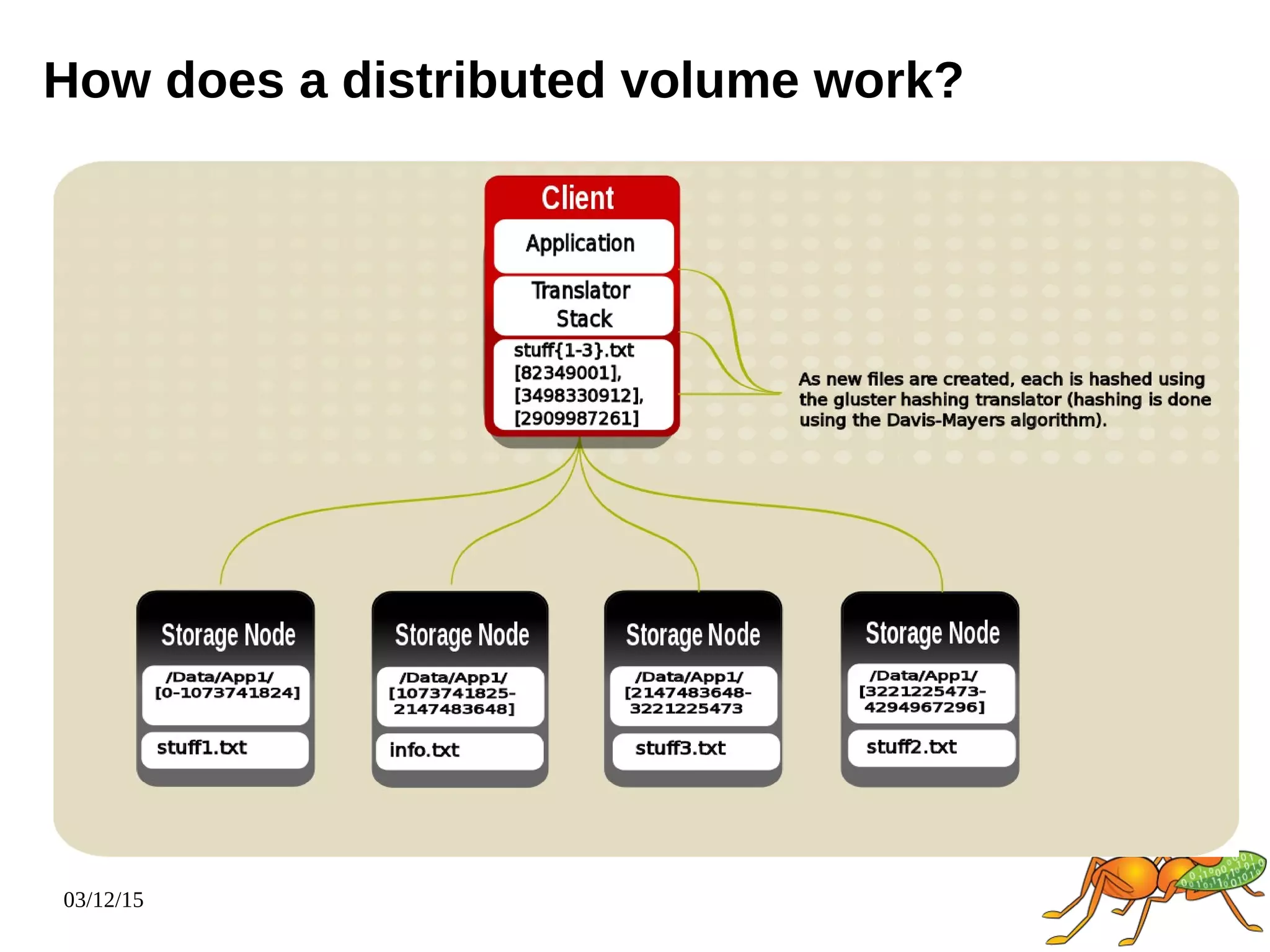
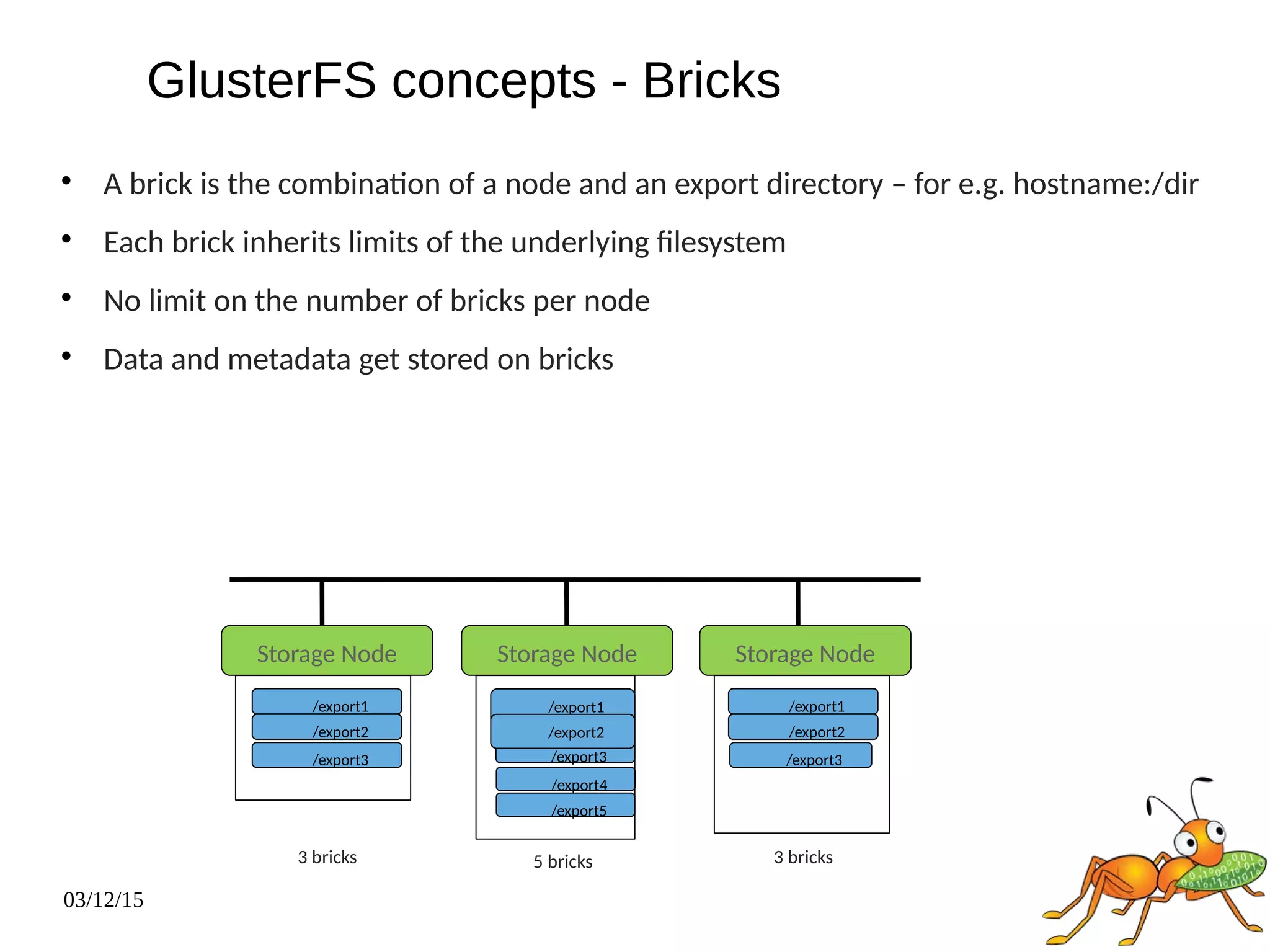

The document provides an overview and future directions of Gluster distributed storage system. It discusses why Gluster is useful given increasing data volumes. It defines Gluster as a scale-out distributed storage system that aggregates storage over a network to provide a unified namespace. It outlines typical deployments and architecture, and describes various volume types like distributed, replicated, dispersed. It also covers access mechanisms, features, use cases and monitoring integration. Finally, it discusses recent releases and new features in development like data tiering, bitrot detection and sharding to improve performance and capabilities.









































































