Download as PDF, PPTX









![Hands On: Connect Servers
[root@vagrant-testVM glusterfs]# gluster peer probe
192.168.121.66
peer probe: success.
[root@vagrant-testVM glusterfs]# gluster peer status
Number of Peers: 1
Hostname: 192.168.121.66
Uuid: 95aee0b5-c816-445b-8dbc-f88da7e95660
State: Accepted peer request (Connected)](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-14-320.jpg)
![Hands On: Server Volume Setup
[root@vagrant-testVM glusterfs]# gluster volume create fubar
replica 2 testvm:/d/backends/fubar{0,1} force
volume create: fubar: success: please start the volume to
access data
[root@vagrant-testVM glusterfs]# gluster volume info fubar
... (see for yourself)
[root@vagrant-testVM glusterfs]# gluster volume status fubar
Volume fubar is not started](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-15-320.jpg)
![Hands On: Server Volume Setup
[root@vagrant-testVM glusterfs]# gluster volume start fubar
volume start: fubar: success
[root@vagrant-testVM glusterfs]# gluster volume status fubar
Status of volume: fubar
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick testvm:/d/backends/fubar0 49152 0 Y 13104
Brick testvm:/d/backends/fubar1 49153 0 Y 13133
Self-heal Daemon on localhost N/A N/A Y 13163
Task Status of Volume fubar
------------------------------------------------------------------------------
There are no active volume tasks](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-16-320.jpg)
![Hands On: Client Volume Setup
[root@vagrant-testVM glusterfs]# mount -t glusterfs testvm:fubar
/mnt/glusterfs/0
[root@vagrant-testVM glusterfs]# df /mnt/glusterfs/0
Filesystem 1K-blocks Used Available Use% Mounted on
testvm:fubar 5232640 33280 5199360 1% /mnt/glusterfs/0
[root@vagrant-testVM glusterfs]# ls -a /mnt/glusterfs/0
. ..
[root@vagrant-testVM glusterfs]# ls -a /d/backends/fubar0
. .. .glusterfs](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-17-320.jpg)

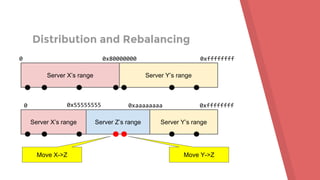

![Hands On: Adding a Brick
[root@vagrant-testVM glusterfs]# gluster volume create xyzzy
testvm:/d/backends/xyzzy{0,1}
[root@vagrant-testVM glusterfs]# getfattr -d -e hex
-m trusted.glusterfs.dht /d/backends/xyzzy{0,1}
# file: d/backends/xyzzy0
trusted.glusterfs.dht=0x0000000100000000000000007ffffffe
# file: d/backends/xyzzy1
trusted.glusterfs.dht=0x00000001000000007fffffffffffffff](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-22-320.jpg)
![Hands On: Adding a Brick
[root@vagrant-testVM glusterfs]# gluster volume add-brick xyzzy
testvm:/d/backends/xyzzy2
volume add-brick: success
[root@vagrant-testVM glusterfs]# gluster volume rebalance xyzzy
fix-layout start
volume rebalance: xyzzy: success: Rebalance on xyzzy has been started
successfully. Use rebalance status command to check status of the
rebalance process.
ID: 88782248-7c12-4ba8-97f6-f5ce6815963](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-23-320.jpg)
![Hands On: Adding a Brick
[root@vagrant-testVM glusterfs]# getfattr -d -e hex -m
trusted.glusterfs.dht /d/backends/xyzzy{0,1,2}
# file: d/backends/xyzzy0
trusted.glusterfs.dht=0x00000001000000000000000055555554
# file: d/backends/xyzzy1
trusted.glusterfs.dht=0x0000000100000000aaaaaaaaffffffff
# file: d/backends/xyzzy2
trusted.glusterfs.dht=0x000000010000000055555555aaaaaaa9](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-24-320.jpg)


![Split Brain (what it looks like)
[root@vagrant-testVM glusterfs]# ls /mnt/glusterfs/0
ls: cannot access /mnt/glusterfs/0/best-sf: Input/output error
best-sf
[root@vagrant-testVM glusterfs]# cat /mnt/glusterfs/0/best-sf
cat: /mnt/glusterfs/0/best-sf: Input/output error
[root@vagrant-testVM glusterfs]# cat /d/backends/fubar0/best-sf
star trek
[root@vagrant-testVM glusterfs]# cat /d/backends/fubar1/best-sf
star wars
What the...?](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-28-320.jpg)






![Hands On: Quota
[root@vagrant-testVM glusterfs]# gluster volume quota xyzzy enable
volume quota : success
[root@vagrant-testVM glusterfs]# gluster volume quota xyzzy soft-timeout 0
volume quota : success
[root@vagrant-testVM glusterfs]# gluster volume quota xyzzy hard-timeout 0
volume quota : success
[root@vagrant-testVM glusterfs]# gluster volume quota xyzzy
limit-usage /john 100MB
volume quota : success](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-38-320.jpg)
![Hands On: Quota
[root@vagrant-testVM glusterfs]# gluster volume quota xyzzy list
Path Hard-limit Soft-limit
-----------------------------------------------------------------
/john 100.0MB 80%(80.0MB)
Used Available Soft-limit exceeded? Hard-limit exceeded?
--------------------------------------------------------------
0Bytes 100.0MB No No](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-39-320.jpg)
![Hands On: Quota
[root@vagrant-testVM glusterfs]# dd if=/dev/zero
of=/mnt/glusterfs/0/john/bigfile bs=1048576 count=85 conv=sync
85+0 records in
85+0 records out
89128960 bytes (89 MB) copied, 1.83037 s, 48.7 MB/s
[root@vagrant-testVM glusterfs]# grep -i john /var/log/glusterfs/bricks/*
/var/log/glusterfs/bricks/d-backends-xyzzy0.log:[2016-11-29 14:31:44.581934]
A [MSGID: 120004] [quota.c:4973:quota_log_usage] 0-xyzzy-quota: Usage
crossed soft limit: 80.0MB used by /john](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-40-320.jpg)
![Hands On: Quota
[root@vagrant-testVM glusterfs]# dd if=/dev/zero
of=/mnt/glusterfs/0/john/bigfile2 bs=1048576 count=85 conv=sync
dd: error writing '''/mnt/glusterfs/0/john/bigfile2''': Disk quota exceeded
[root@vagrant-testVM glusterfs]# gluster volume quota xyzzy list | cut -c
66-
Used Available Soft-limit exceeded? Hard-limit exceeded?
--------------------------------------------------------------
101.9MB 0Bytes Yes Yes](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-41-320.jpg)

![Hands On: Snapshots
[root@vagrant-testVM glusterfs]# fallocate -l $((100*1024*1024))
/tmp/snap-brick0
[root@vagrant-testVM glusterfs]# losetup --show -f /tmp/snap-brick0
/dev/loop3
[root@vagrant-testVM glusterfs]# vgcreate snap-vg0 /dev/loop3
Volume group "snap-vg0" successfully created](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-43-320.jpg)
![Hands On: Snapshots
[root@vagrant-testVM glusterfs]# lvcreate -L 50MB -T /dev/snap-vg0/thinpool
Rounding up size to full physical extent 52.00 MiB
Logical volume "thinpool" created.
[root@vagrant-testVM glusterfs]# lvcreate -V 200MB -T /dev/snap-vg0/thinpool
-n snap-lv0
Logical volume "snap-lv0" created.
[root@vagrant-testVM glusterfs]# mkfs.xfs /dev/snap-vg0/snap-lv0
...
[root@vagrant-testVM glusterfs]# mount /dev/snap-vg0/snap-lv0
/d/backends/xyzzy0
...](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-44-320.jpg)
![Hands On: Snapshots
[root@vagrant-testVM glusterfs]# gluster volume create xyzzy
testvm:/d/backends/xyzzy{0,1} force
[root@vagrant-testVM glusterfs]# echo hello > /mnt/glusterfs/0/file1
[root@vagrant-testVM glusterfs]# echo hello > /mnt/glusterfs/0/file2
[root@vagrant-testVM glusterfs]# gluster snapshot create snap1 xyzzy
snapshot create: success: Snap snap1_GMT-2016.11.29-14.57.11 created
successfully
[root@vagrant-testVM glusterfs]# echo hello > /mnt/glusterfs/0/file3](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-45-320.jpg)
![Hands On: Snapshots
[root@vagrant-testVM glusterfs]# gluster snapshot activate
snap1_GMT-2016.11.29-14.57.11
Snapshot activate: snap1_GMT-2016.11.29-14.57.11: Snap activated
successfully
[root@vagrant-testVM glusterfs]# mount -t glusterfs
testvm:/snaps/snap1_GMT-2016.11.29-14.57.11/xyzzy /mnt/glusterfs/1
[root@vagrant-testVM glusterfs]# ls /mnt/glusterfs/1
file1 file2
[root@vagrant-testVM glusterfs]# echo hello > /mnt/glusterfs/1/file3
-bash: /mnt/glusterfs/1/file3: Read-only file system](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-46-320.jpg)
![Hands On: Snapshots
[root@vagrant-testVM glusterfs]# gluster snapshot clone clone1
snap1_GMT-2016.11.29-14.57.11
snapshot clone: success: Clone clone1 created successfully
[root@vagrant-testVM glusterfs]# gluster volume start clone1
volume start: clone1: success
[root@vagrant-testVM glusterfs]# mount -t glusterfs testvm:/clone1
/mnt/glusterfs/2
[root@vagrant-testVM glusterfs]# echo goodbye > /mnt/glusterfs/2/file3](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-47-320.jpg)
![Hands On: Snapshots
# Unmount and stop clone.
# Stop original volume - but leave snapshot activated!
[root@vagrant-testVM glusterfs]# gluster snapshot restore snap1_GMT-2016.11.29-14.57.11
Restore operation will replace the original volume with the snapshotted volume. Do you still want to
continue? (y/n) y
Snapshot restore: snap1_GMT-2016.11.29-14.57.11: Snap restored successfully
[root@vagrant-testVM glusterfs]# gluster volume start xyzzy
volume start: xyzzy: success
[root@vagrant-testVM glusterfs]# ls /mnt/glusterfs/0
file1 file2](https://image.slidesharecdn.com/glustertutorial-161206215425/85/Hands-On-Gluster-with-Jeff-Darcy-48-320.jpg)





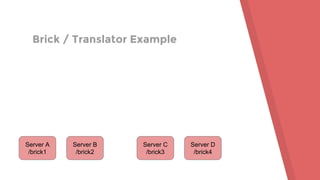
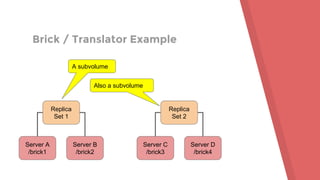
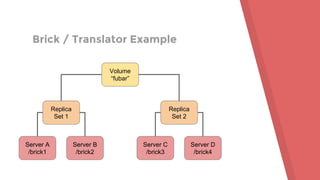
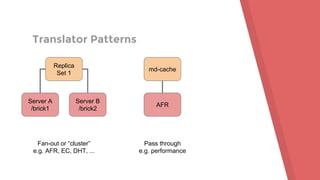
This document provides an agenda and overview for a Gluster tutorial presentation. It includes sections on Gluster basics, initial setup using test drives and VMs, extra Gluster features like snapshots and quota, and tips for maintenance and troubleshooting. Hands-on examples are provided to demonstrate creating a Gluster volume across two servers and mounting it as a filesystem. Terminology around bricks, translators, and the volume file are introduced.























































































