Gluster is an open-source distributed scale-out storage system. It uses commodity hardware and has no centralized metadata server. Key concepts include bricks (storage units on servers), volumes (logical collections of bricks), and a trusted storage pool of nodes. Main volume types are distributed, replicated, distributed replicated, and striped. To set up Gluster, install packages, start services, create a storage pool, make volumes, and mount them on clients.





![Trusted storage pool
A trusted network of nodes that host storage resources
Trusted storage pool commands
Add new node:
- gluster peer probe [node] command is used to add nodes to the
trusted storage pool
Remove node:
- gluster peer detach [node] command is used to remove nodes from
the trusted storage pool](https://image.slidesharecdn.com/gluster2015-160505195645/85/Gluster-Storage-5-320.jpg)






![Creating a Distributed Volume
gluster volume create NEW-VOLNAME [transport [tcp | rdma | tcp,rdma]] NEW-BRICK...
For example, to create a distributed volume with four storage servers using TCP:
# gluster volume create test-volume server1:/exp1 server2:/exp2
server3:/exp3 server4:/exp4
Creation of test-volume has been successful
Please start the volume to access data](https://image.slidesharecdn.com/gluster2015-160505195645/85/Gluster-Storage-14-320.jpg)

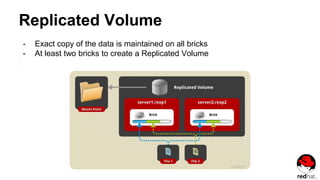
![Create a Replicated Volume
gluster volume create NEW-VOLNAME [replica COUNT] [transport [tcp | rdma |
tcp,rdma]] NEW-BRICK...
For example, to create a replicated volume with two storage servers:
# gluster volume create test-volume replica 2 transport tcp server1:/exp1
server2:/exp2
Creation of test-volume has been successful
Please start the volume to access data](https://image.slidesharecdn.com/gluster2015-160505195645/85/Gluster-Storage-17-320.jpg)
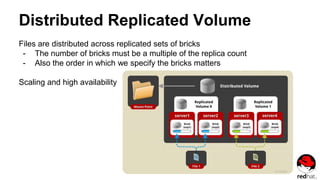
![Create a Distributed Replicated Volume
gluster volume create NEW-VOLNAME [replica COUNT] [transport [tcp | rdma |
tcp,rdma]] NEW-BRICK...
# gluster volume create test-volume replica 2 transport tcp
server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4
Creation of test-volume has been successful
Please start the volume to access data](https://image.slidesharecdn.com/gluster2015-160505195645/85/Gluster-Storage-19-320.jpg)

![Create a Striped Volume
gluster volume create NEW-VOLNAME [stripe COUNT] [transport [tcp | dma | tcp,rdma]]
NEW-BRICK...
For example, to create a striped volume across two storage servers:
# gluster volume create test-volume stripe 2 transport tcp server1:/exp1
server2:/exp2
Creation of test-volume has been successful
Please start the volume to access data](https://image.slidesharecdn.com/gluster2015-160505195645/85/Gluster-Storage-21-320.jpg)



















![[OpenInfra Days Korea 2018] Day 2 - CEPH 운영자를 위한 Object Storage Performance T...](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradayobjectstorageperformancefinal2-180704062033-thumbnail.jpg?width=640&height=640&fit=bounds)



















































