Download as PDF, PPTX








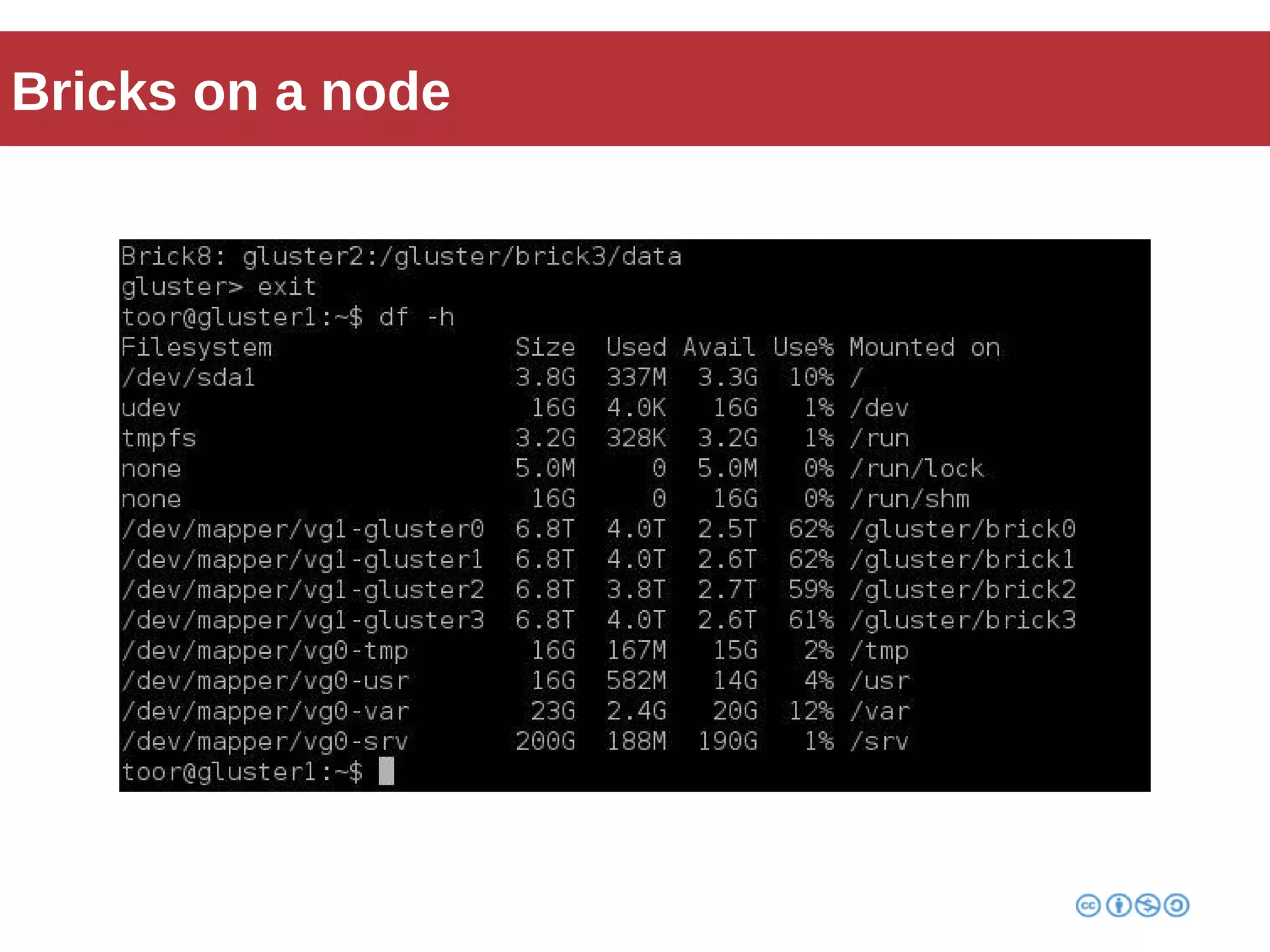

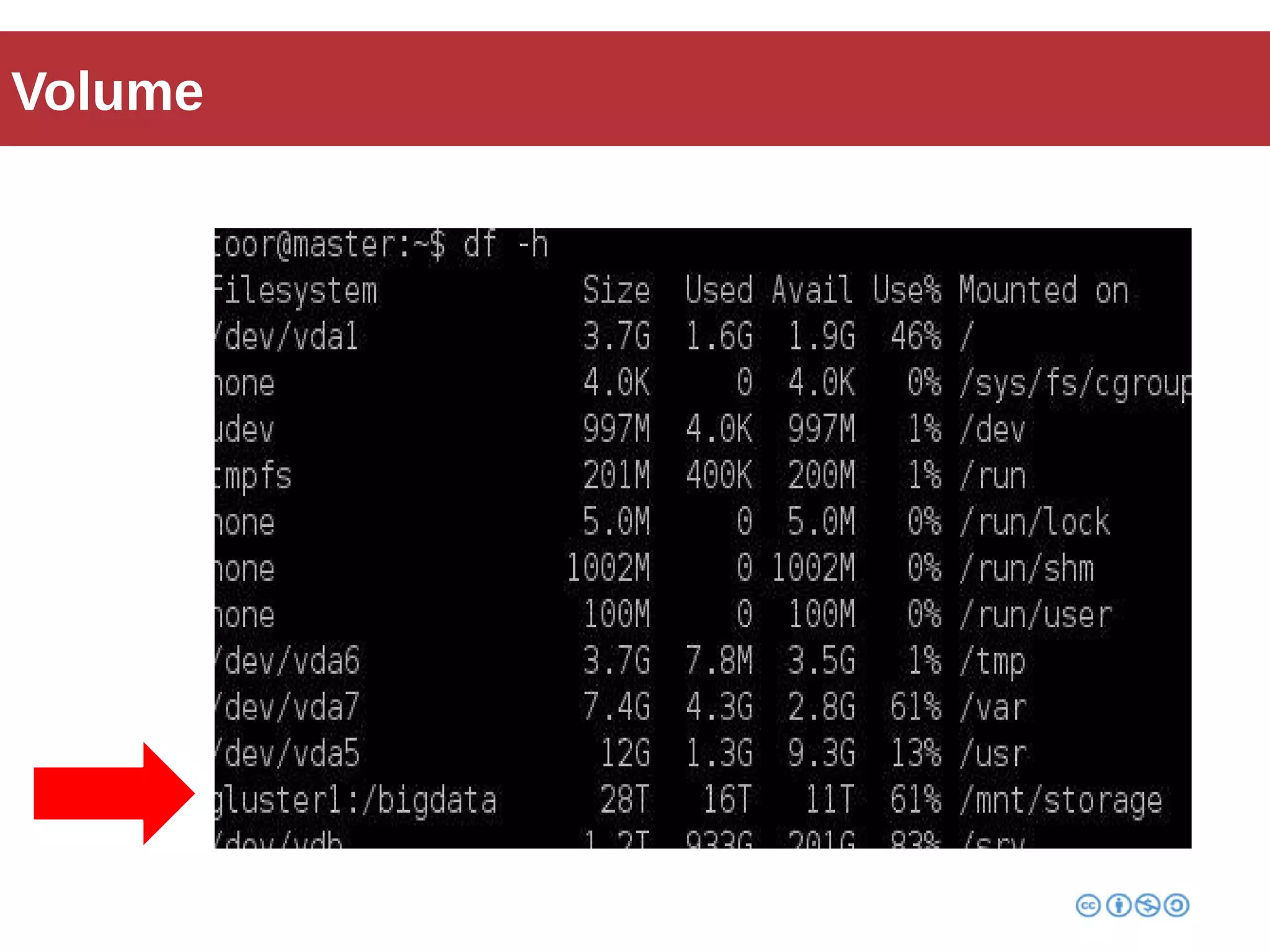


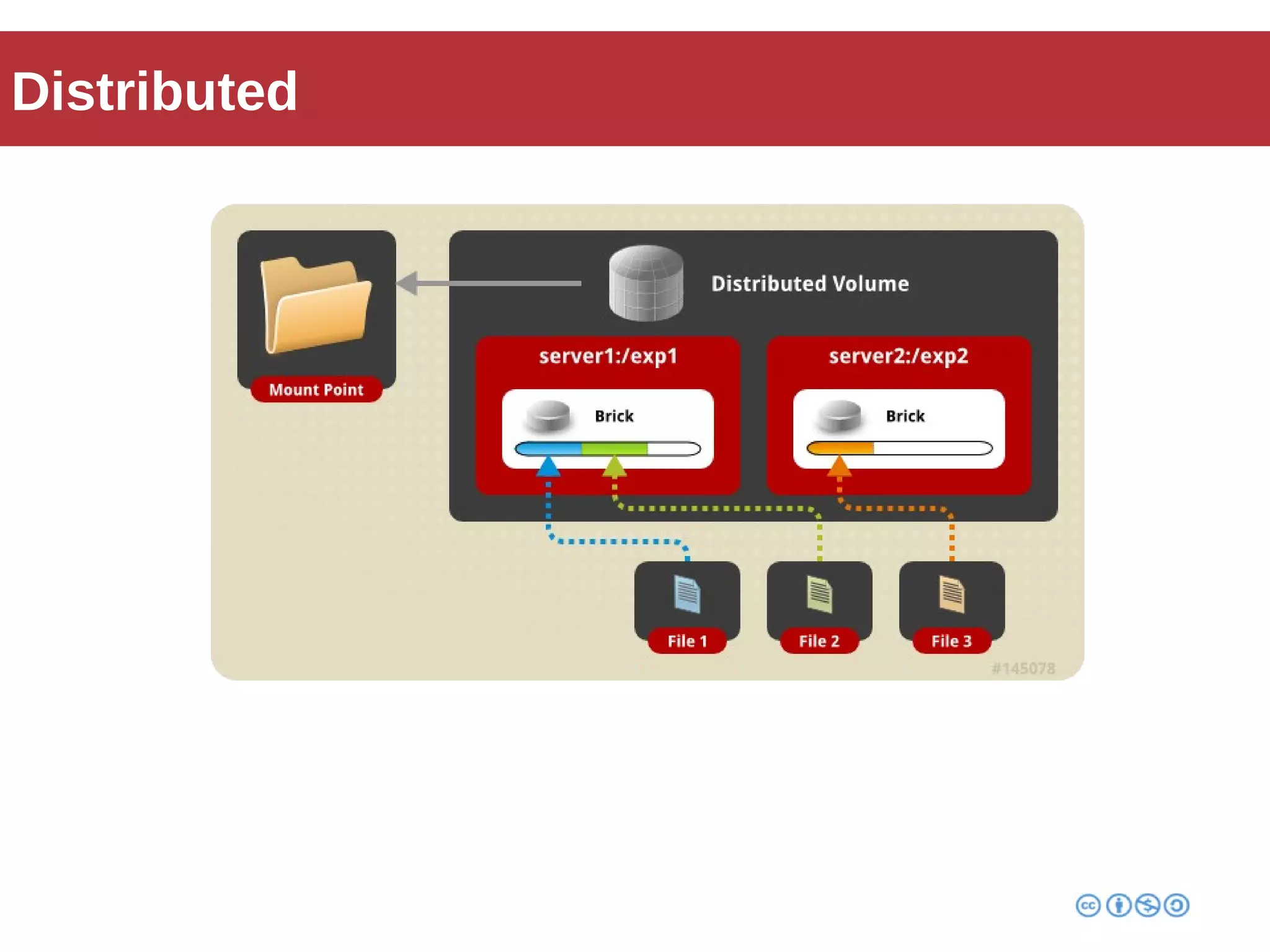

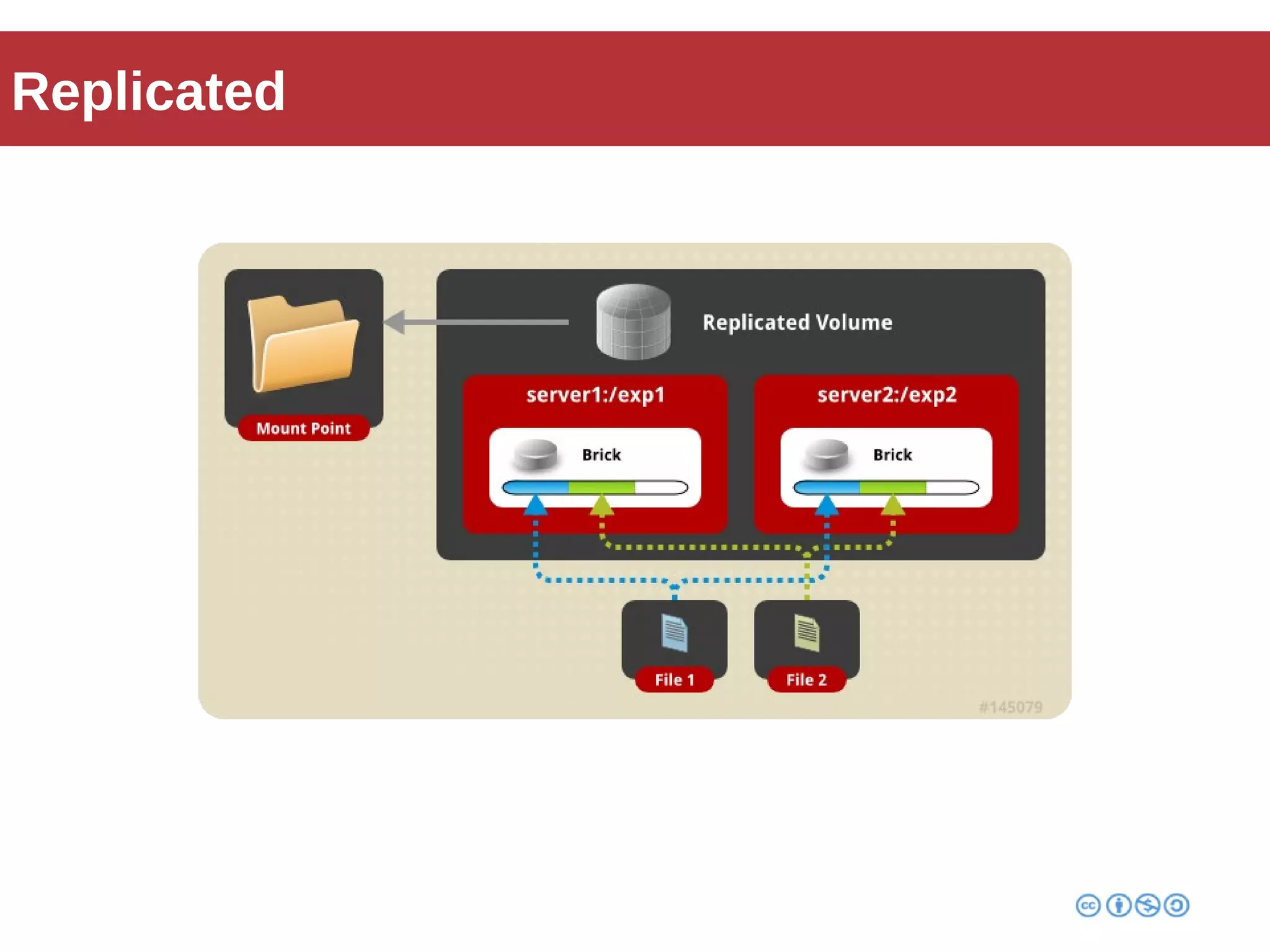

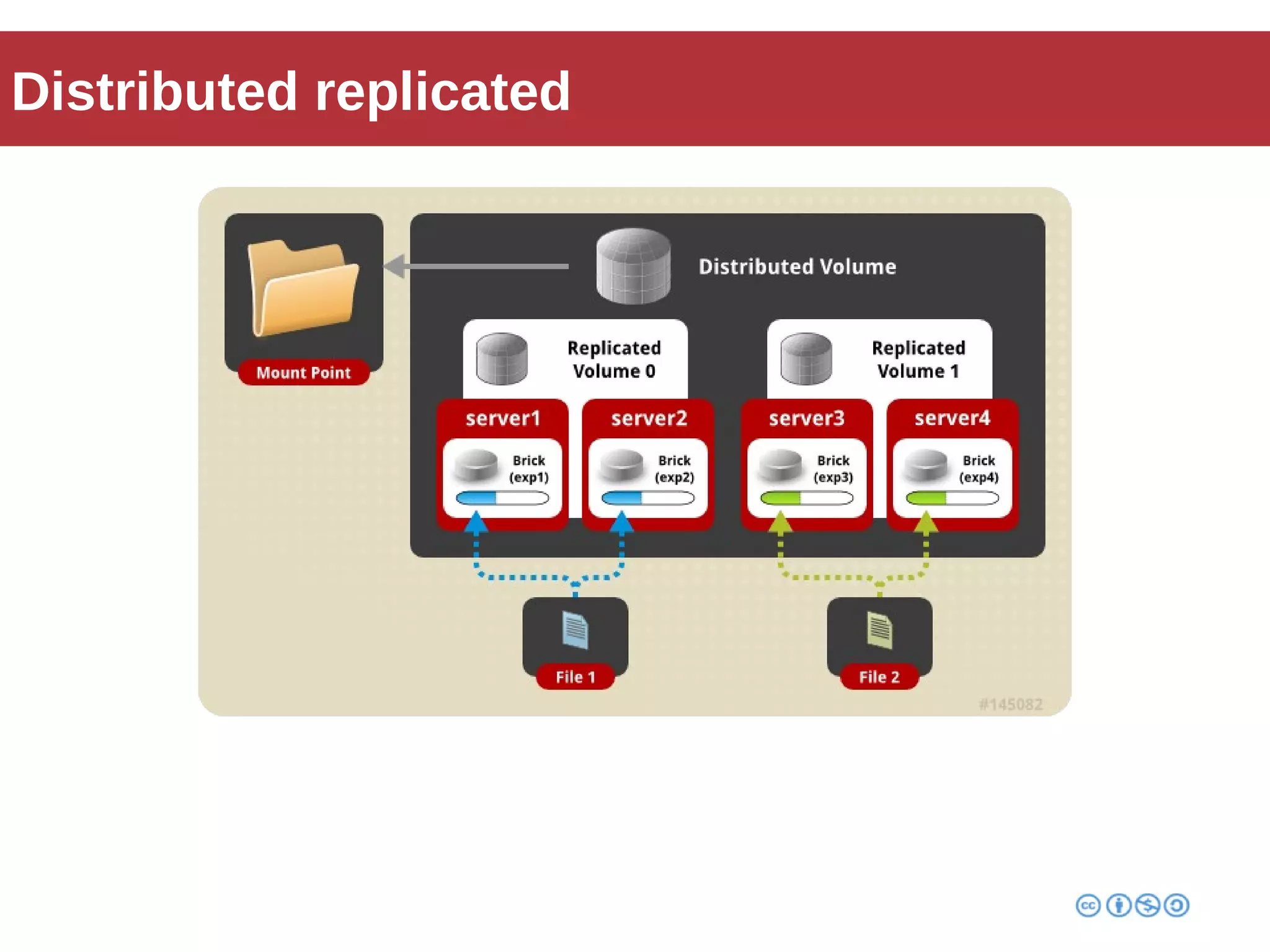

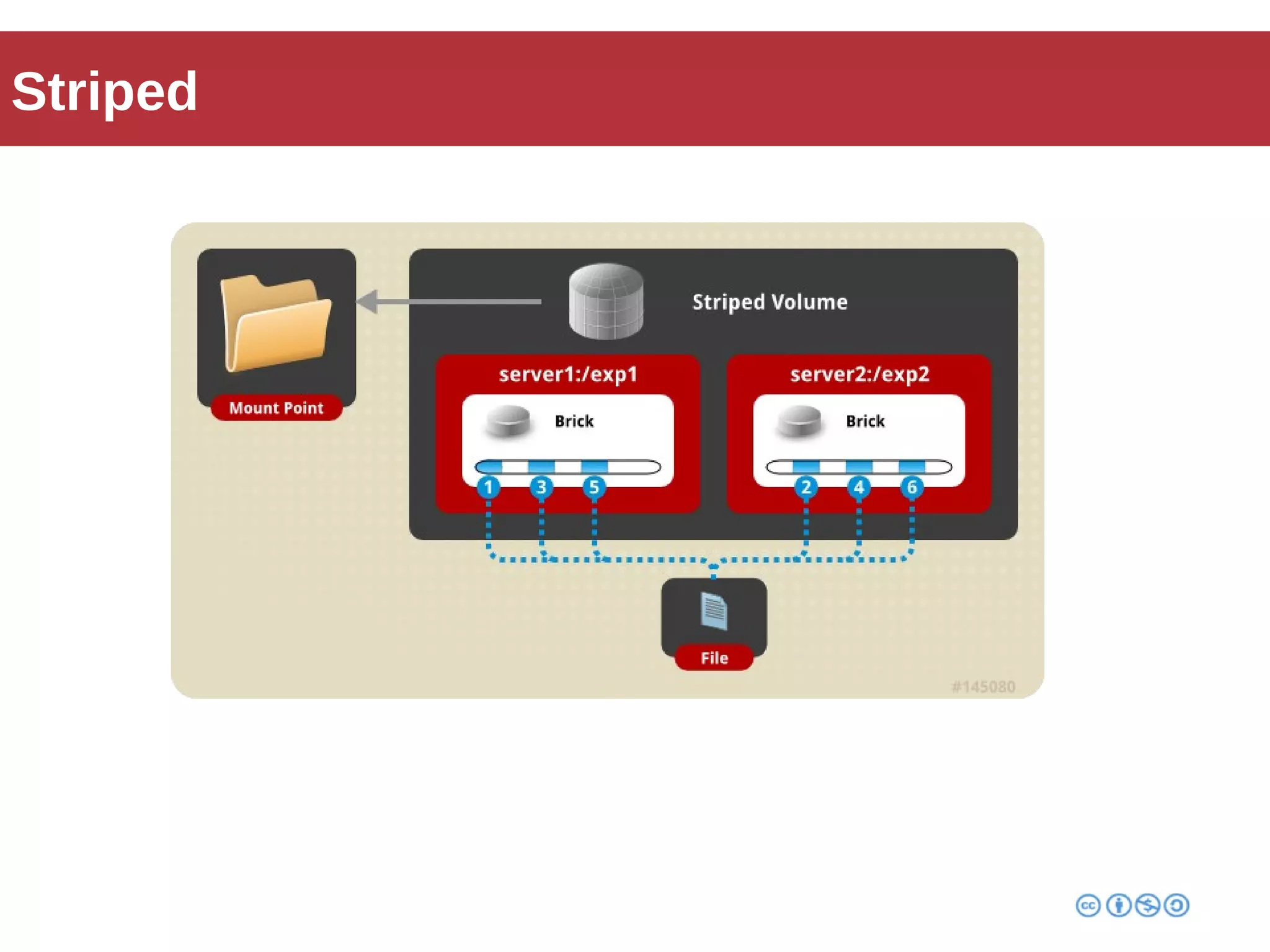








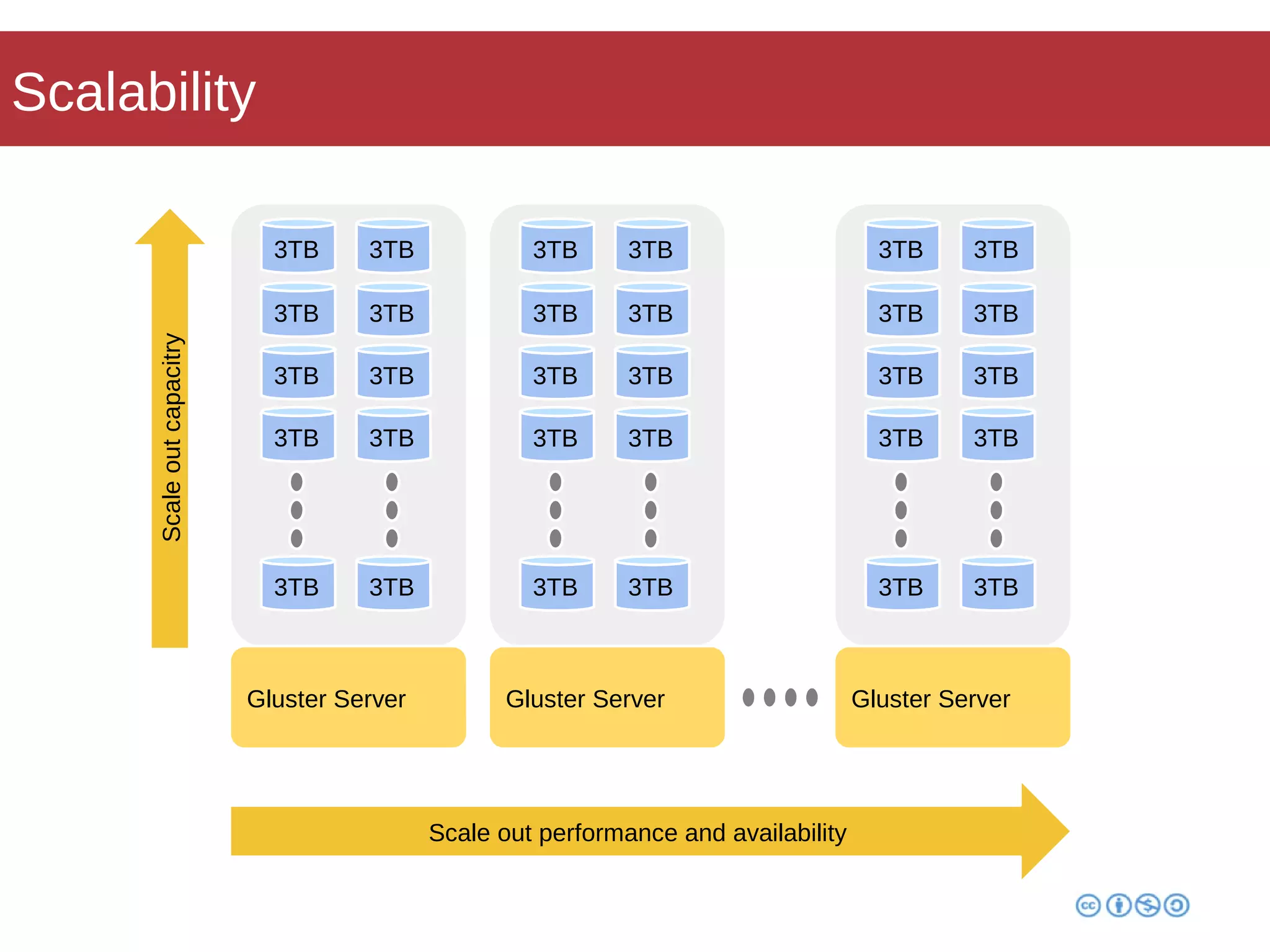








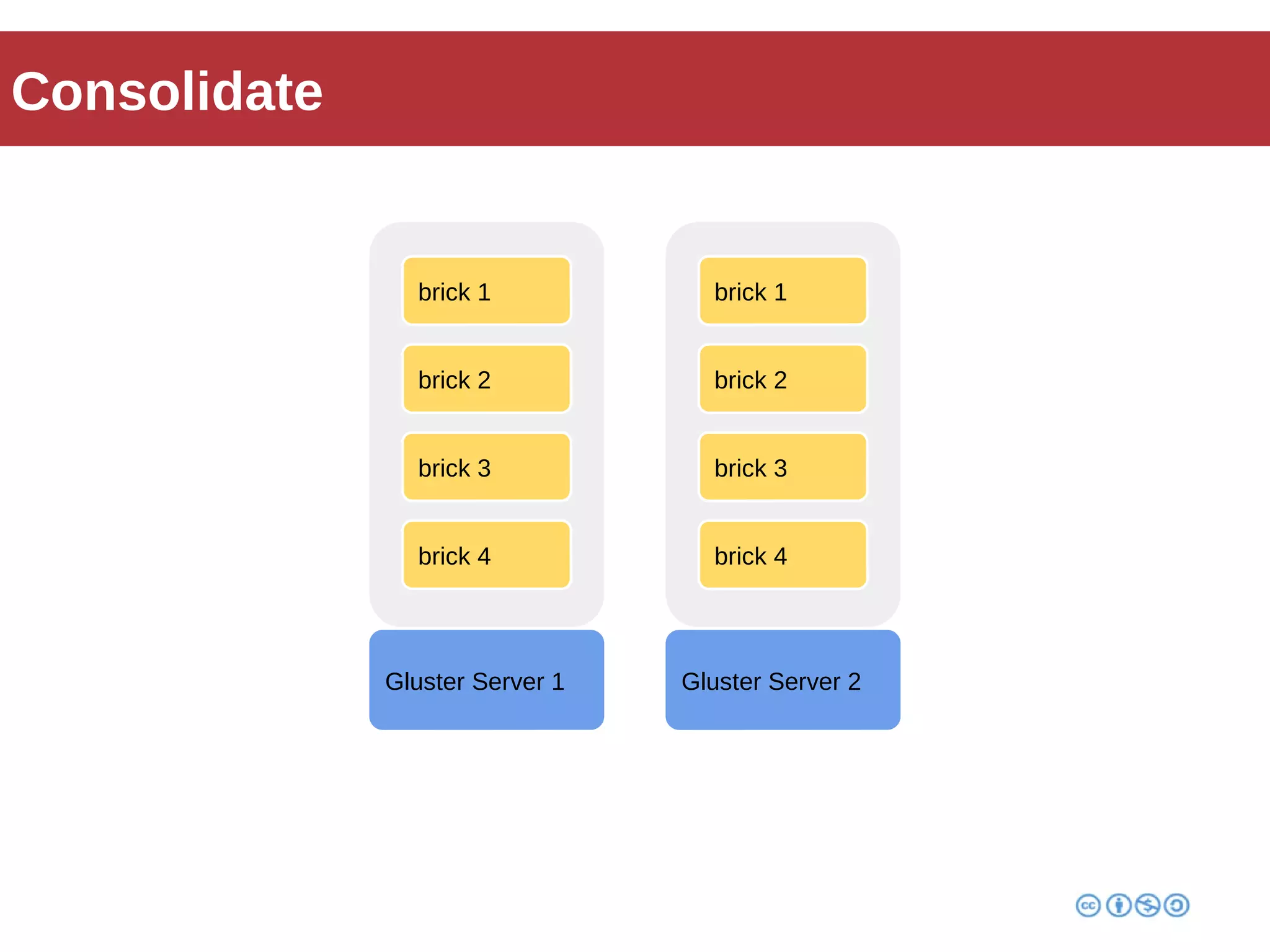








Roberto Franchini discusses GlusterFS, a scalable distributed file system suitable for managing large amounts of data without centralized metadata, catering to various use cases such as backup, media distribution, and high-performance computing. He details its architecture, including peer nodes, volumes, and different volume types like distributed and replicated, while highlighting its modular and fault-tolerant features. The presentation also covers the evolution and implementation of GlusterFS in production environments, showcasing its scalability and performance improvements over time.








































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)



![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)










