Download as ODP, PPTX




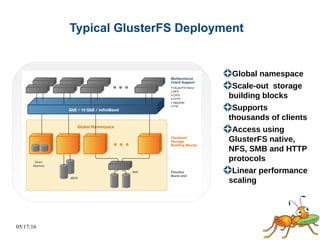



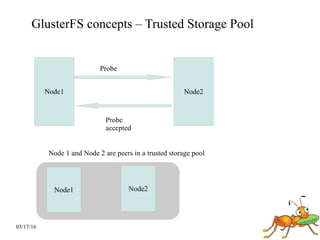
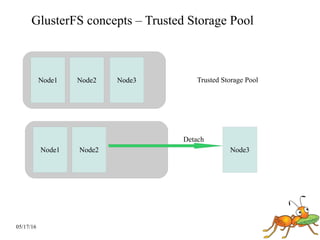
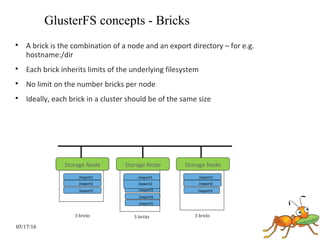



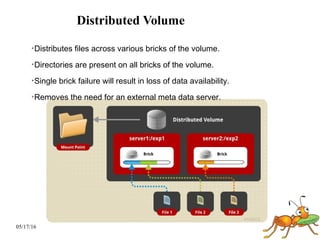

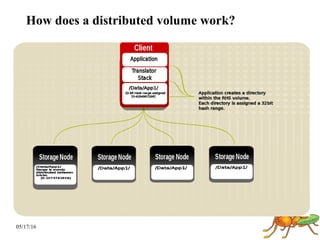
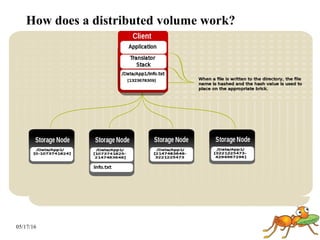
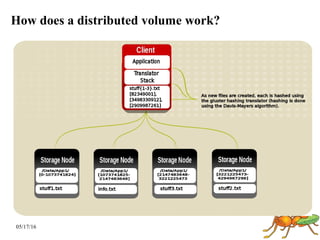

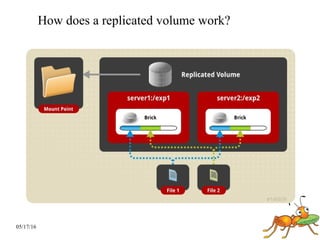
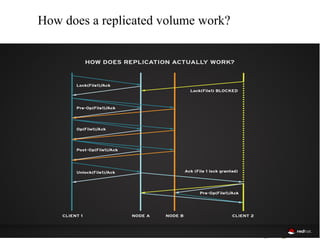

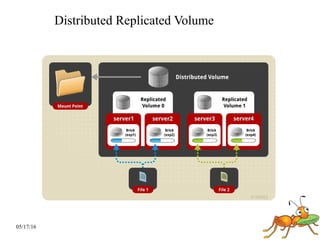




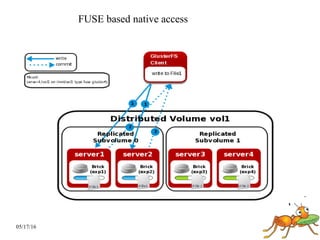
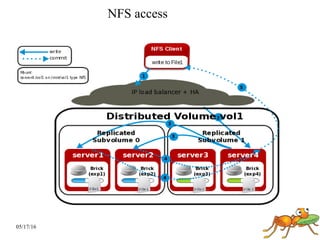

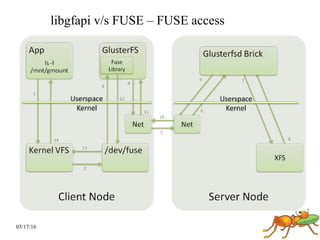
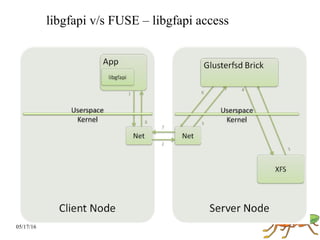
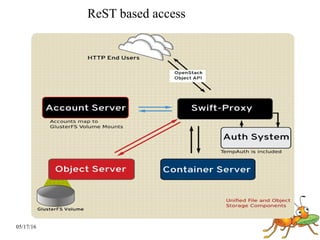
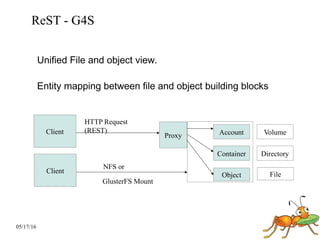
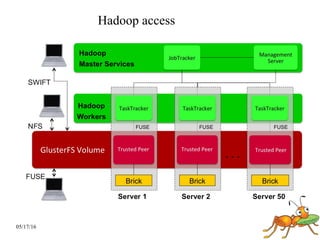


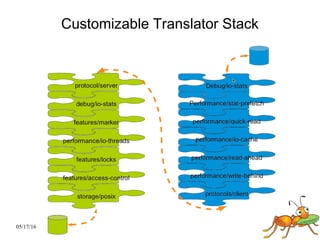


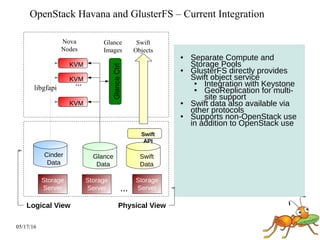
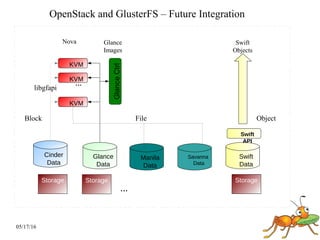












GlusterFS is a scale-out distributed file system that aggregates storage over a network to provide a single unified namespace. It has a modular architecture and runs on commodity hardware without external metadata servers. Future directions for GlusterFS include distributed geo-replication, file snapshots, and erasure coding support. Challenges include improving scalability, supporting hard links and renames, reducing monitoring overhead, and lowering costs.











































































































