Downloaded 24 times














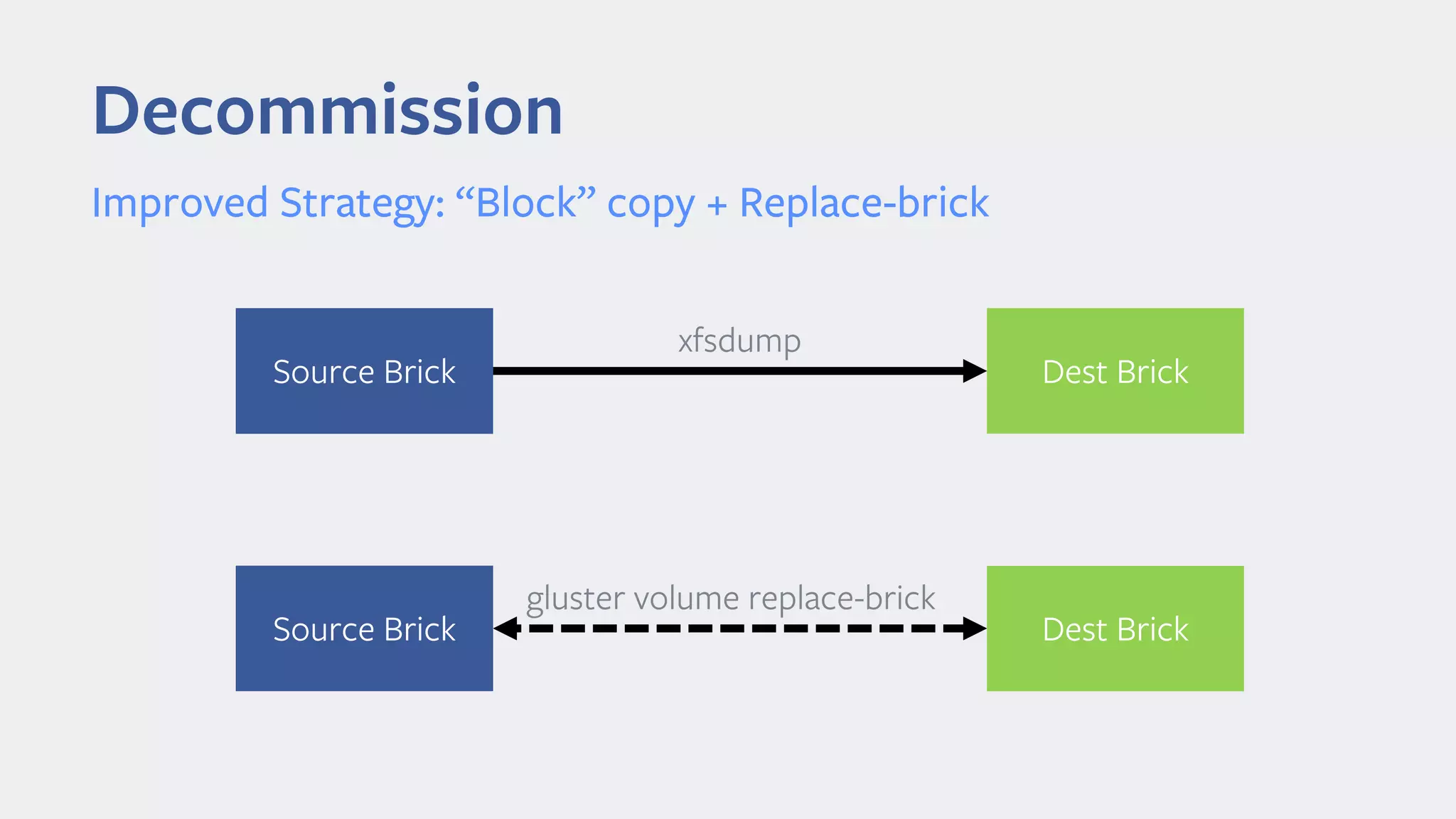




The document discusses the lifecycle of a Gluster volume, including creation, maintenance through software upgrades and hardware repairs, and decommission. During creation, hardware must be homogenous and the layout distributed across racks for high availability. Maintenance involves batch upgrading software on racks serially to avoid quorum loss, and replacing hardware by first copying data in blocks and then using replace-brick. Decommissioning full hardware requires copying all data in blocks first to another node before replacing to ensure integrity and no downtime.























































































