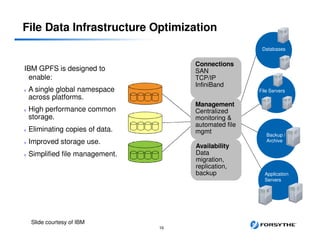
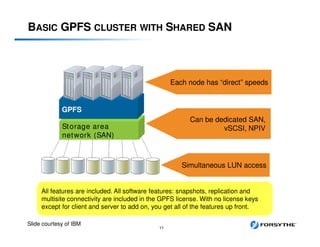
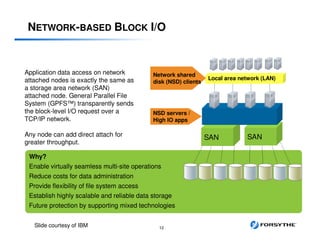
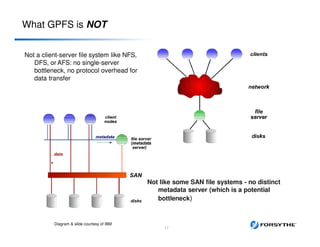
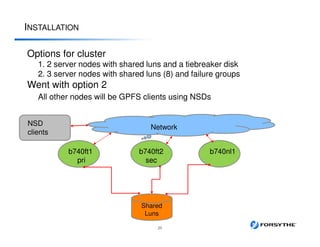
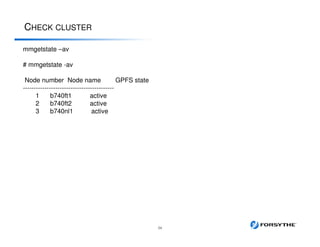
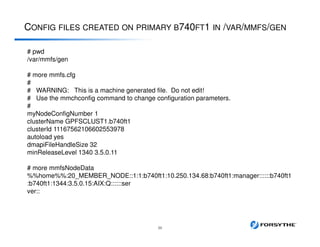
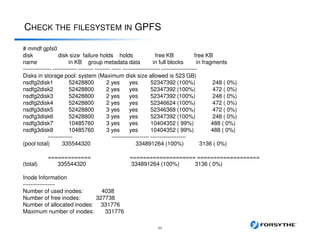
This document provides an overview of installing and configuring a 3 node GPFS cluster. It discusses using 8 shared LUNs across the 3 servers to simulate having disks from 2 different V7000 storage arrays for redundancy. The disks will be divided into 2 failure groups, with hdisk1-4 in one failure group representing one simulated array, and hdisk5-8 in the other failure group representing the other simulated array. This is to ensure redundancy in case of failure of an entire storage array.