Downloaded 82 times


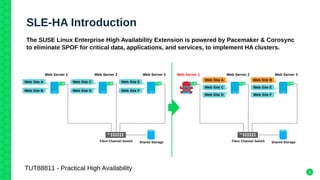



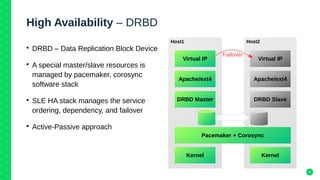

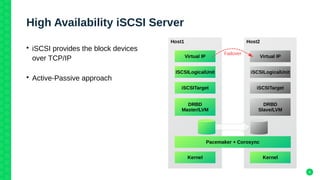

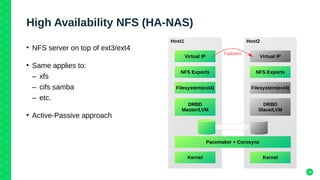
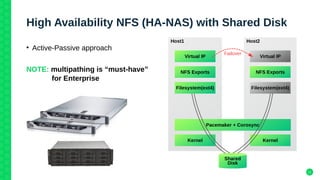

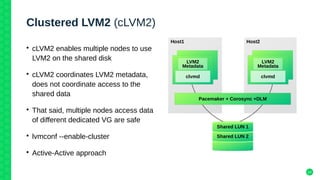
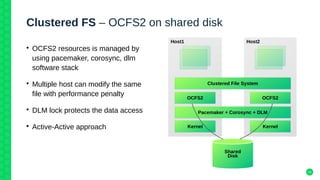
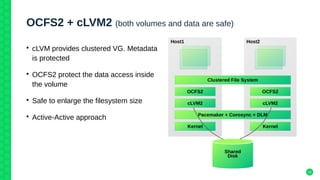







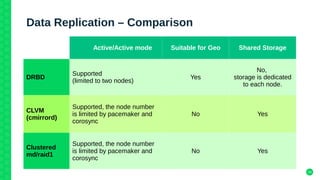
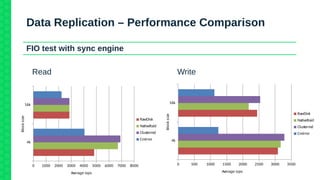
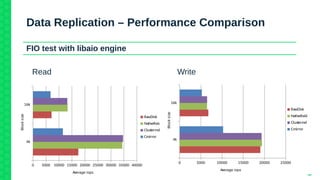





The document outlines the architecture and elements of SUSE's high availability (HA) storage solutions, which utilize technologies like Pacemaker and Corosync to ensure data and application availability. It covers various components including DRBD for data replication, clustered LVM, and clustered file systems such as OCFS2, detailing their configurations and the benefits they offer for enterprise-level applications. Additionally, it discusses performance comparisons and requirements for effective data management in high availability scenarios.


































































