Download as PDF, PPTX


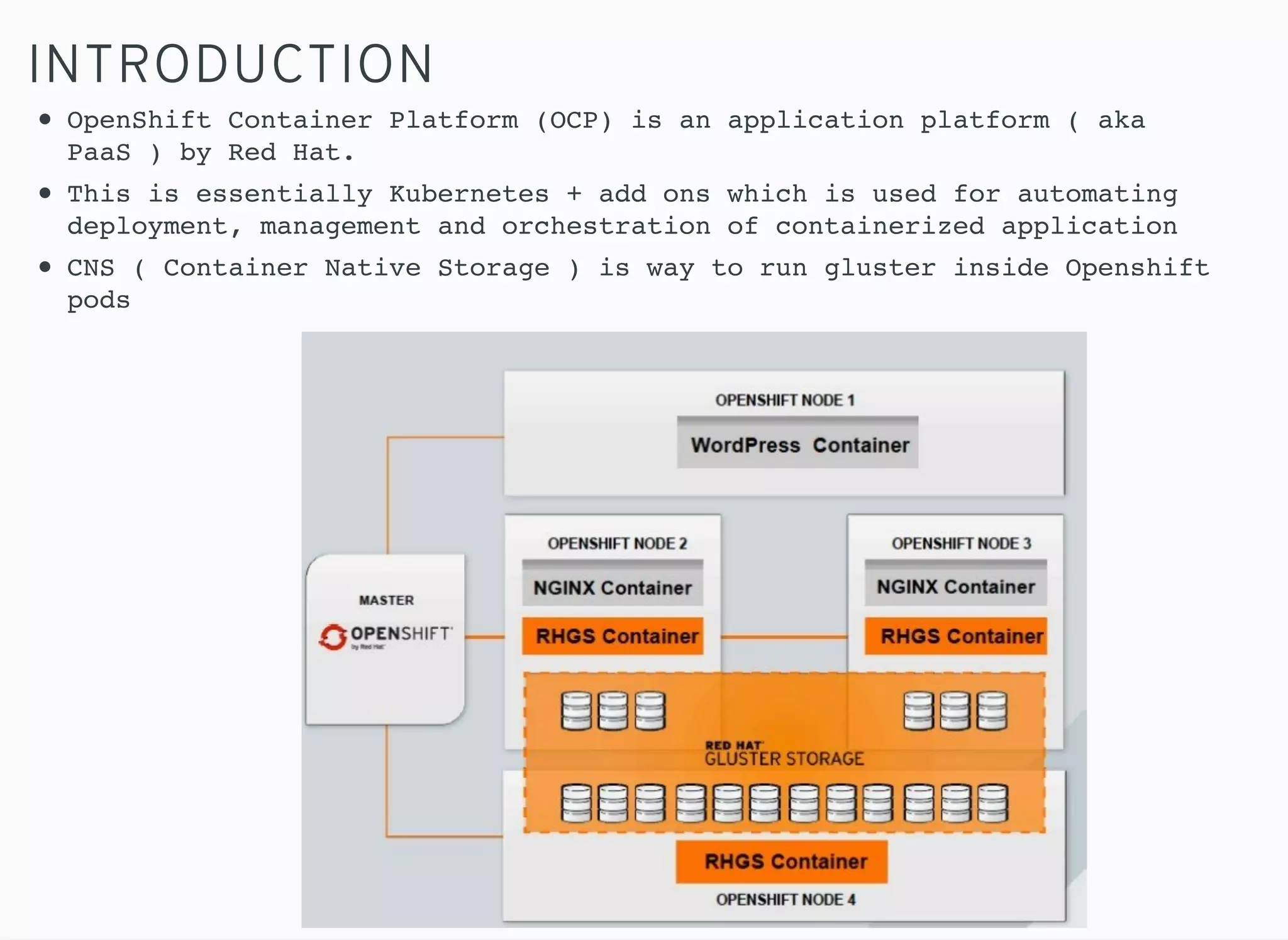





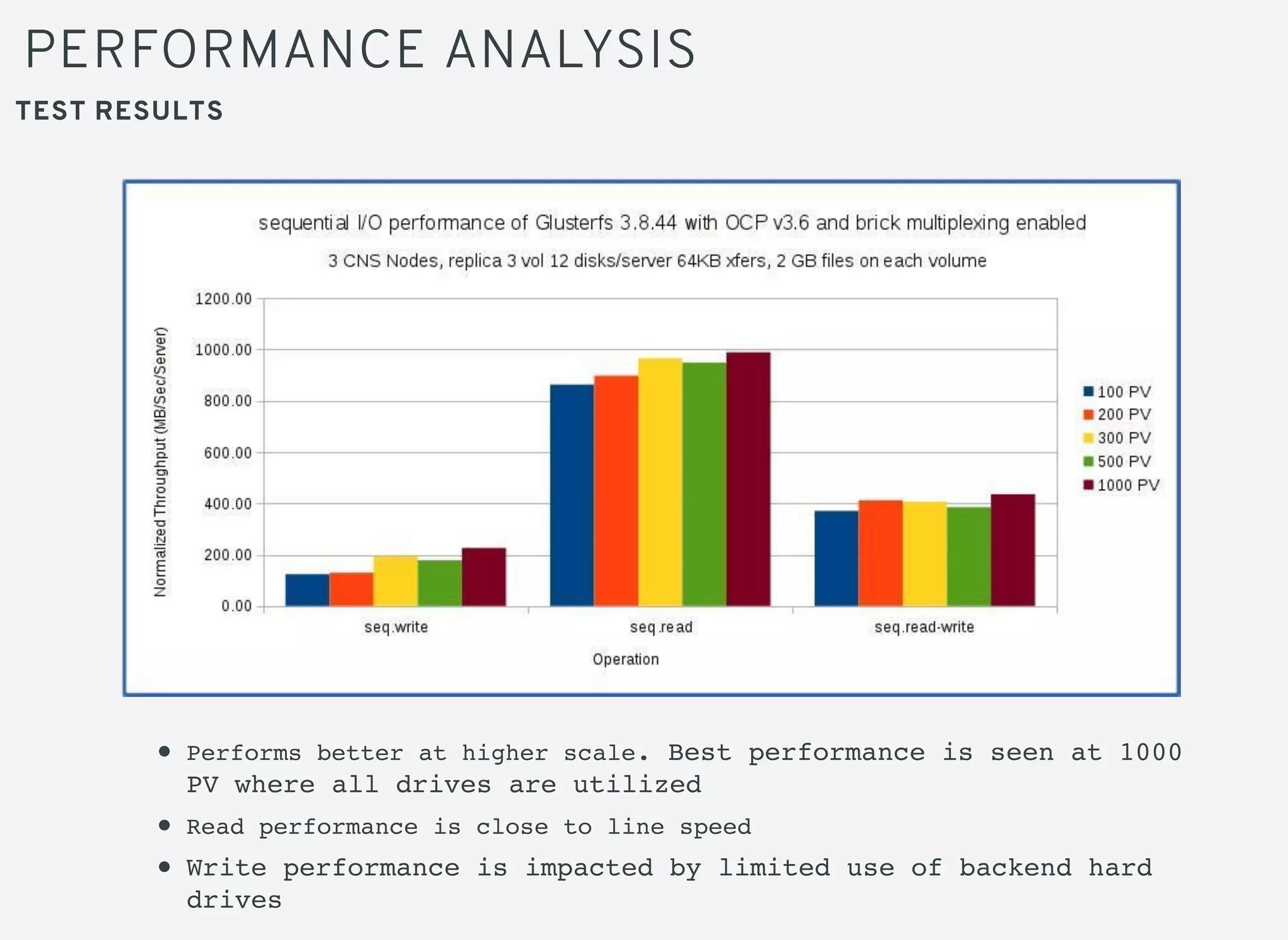
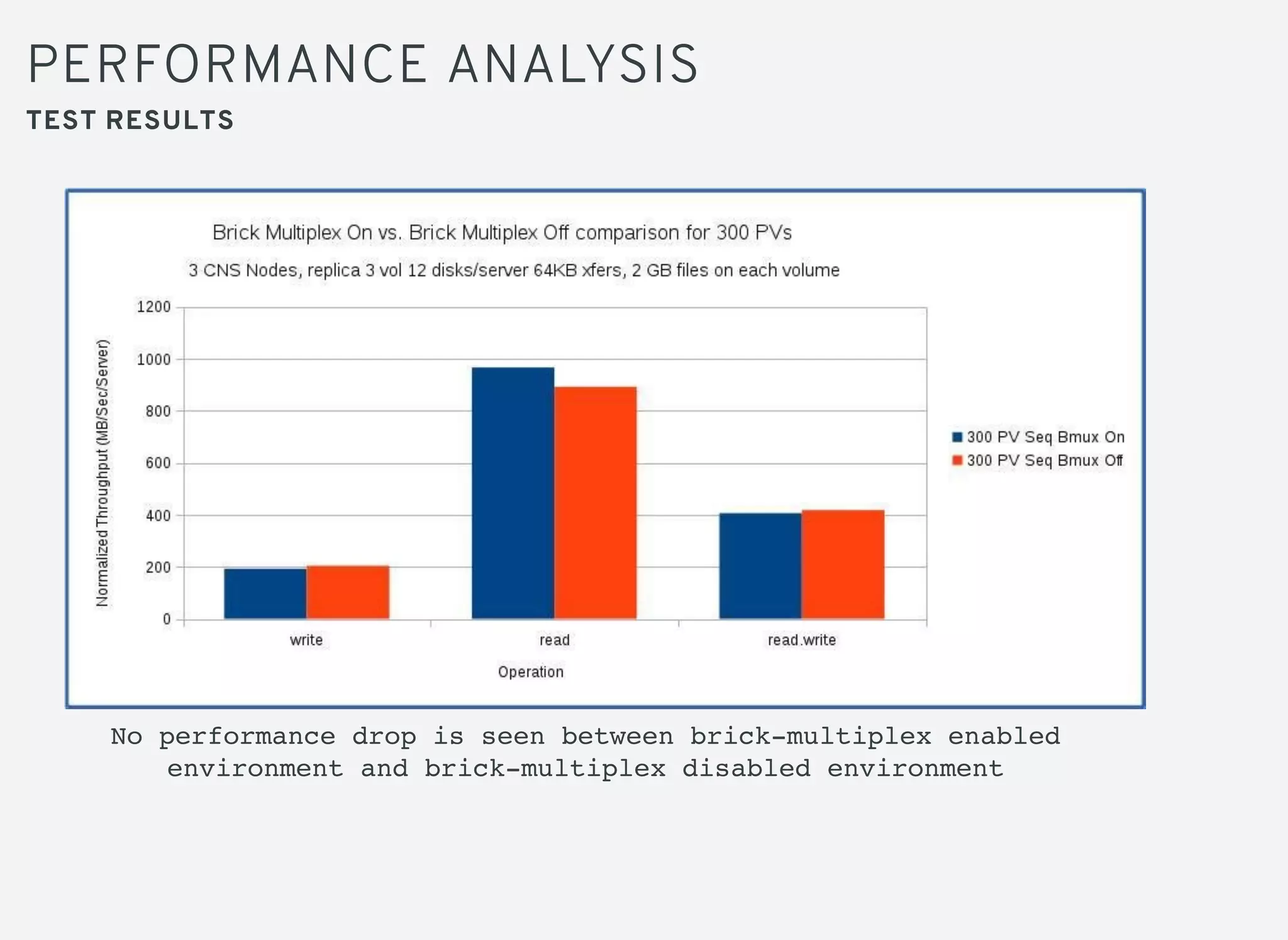



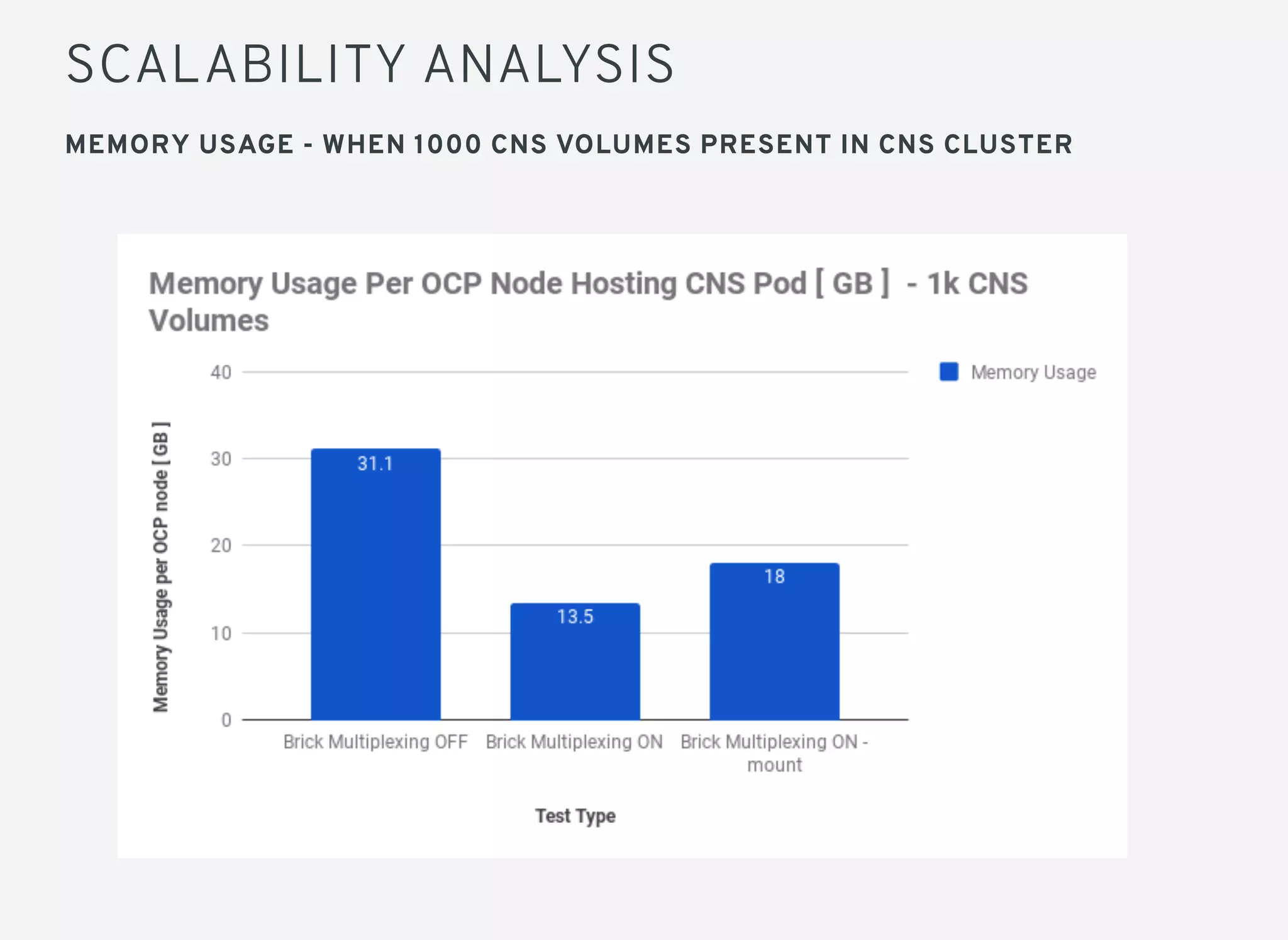
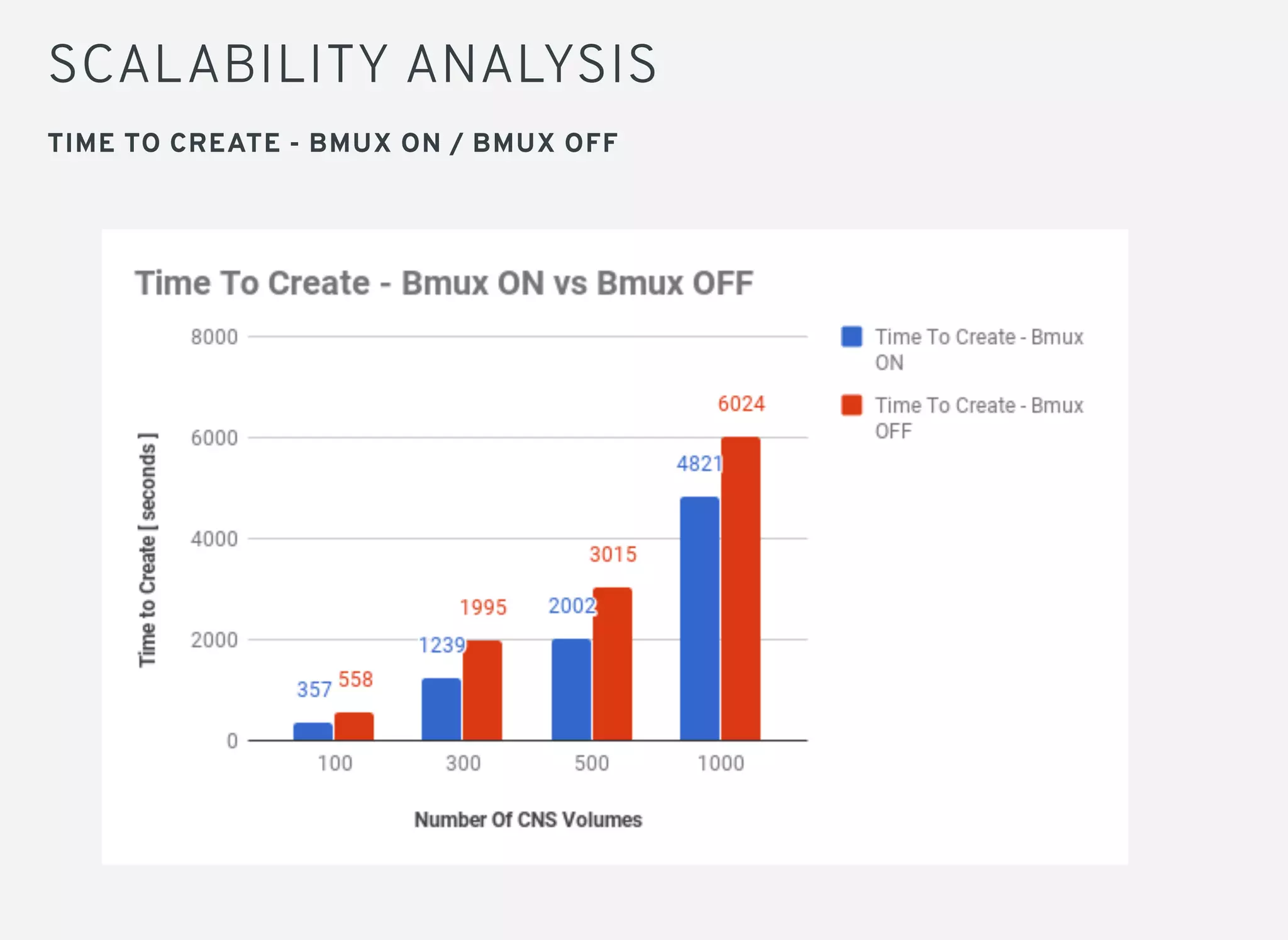
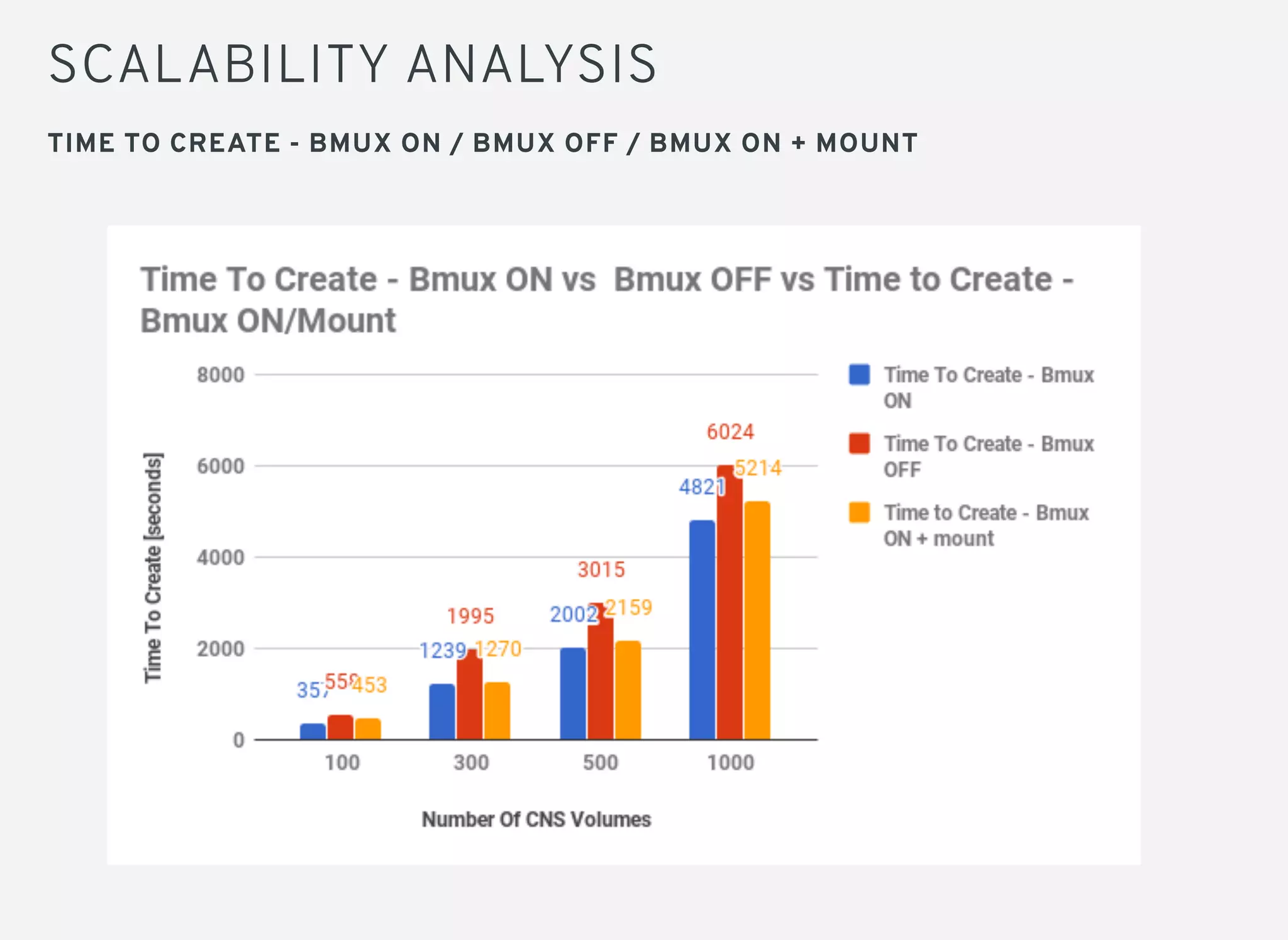







Brick multiplexing allows multiple storage bricks in GlusterFS to be managed by a single process, reducing resource usage. Performance testing showed no degradation with brick multiplexing enabled, and it allows faster scaling to support more persistent volumes. Memory usage is lower with brick multiplexing, allowing more volumes to be supported on the same hardware. Brick multiplexing improves scalability and is recommended to be left enabled.























































































