Download as PDF, PPTX




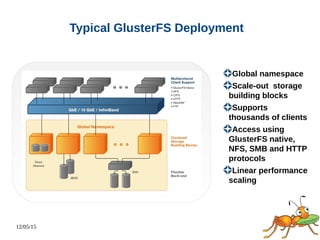



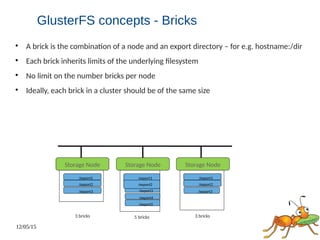



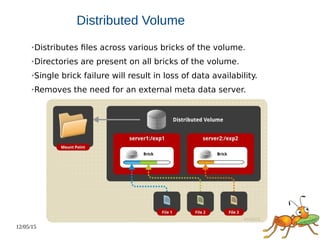


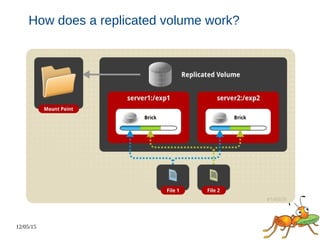

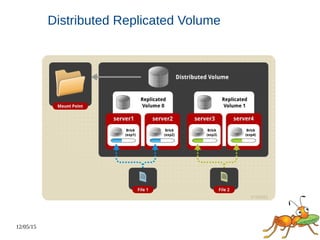





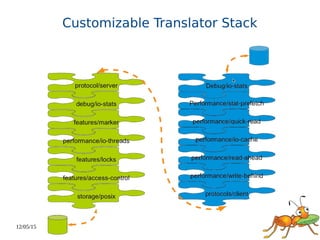

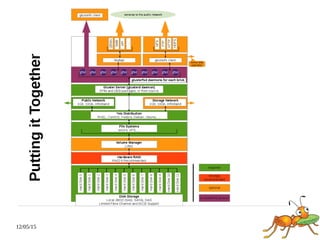






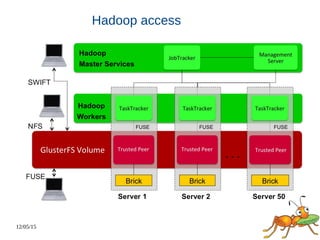



This document discusses using GlusterFS for Hadoop. GlusterFS is an open-source distributed file system that aggregates storage and provides a unified namespace. It can be used as the storage layer for Hadoop, replacing HDFS. Using GlusterFS provides advantages like a POSIX-compliant file system, ability to use the same storage for MapReduce and application data, and features like geo-replication and erasure coding. GlusterFS also integrates with projects like Apache Spark, Ambari, and OpenStack.


















































































