Downloaded 230 times
![S.Prasanth Kumar, Bioinformatician Gene Expression Studies Gene Expression Profiling Microarray Data Analysis: Unsupervised Learning Algorithms S.Prasanth Kumar, Bioinformatician S.Prasanth Kumar Dept. of Bioinformatics Applied Botany Centre (ABC) Gujarat University, Ahmedabad, INDIA www.facebook.com/Prasanth Sivakumar FOLLOW ME ON ACCESS MY RESOURCES IN SLIDESHARE prasanthperceptron CONTACT ME [email_address]](https://image.slidesharecdn.com/geneexpressionprofiling-i-110324013640-phpapp02/85/Gene-expression-profiling-i-1-320.jpg)
![S.Prasanth Kumar, Bioinformatician Gene Expression Studies Gene Expression Profiling Microarray Data Analysis: Unsupervised Learning Algorithms S.Prasanth Kumar, Bioinformatician S.Prasanth Kumar Dept. of Bioinformatics Applied Botany Centre (ABC) Gujarat University, Ahmedabad, INDIA www.facebook.com/Prasanth Sivakumar FOLLOW ME ON ACCESS MY RESOURCES IN SLIDESHARE prasanthperceptron CONTACT ME [email_address]](https://image.slidesharecdn.com/geneexpressionprofiling-i-110324013640-phpapp02/75/Gene-expression-profiling-i-1-2048.jpg)
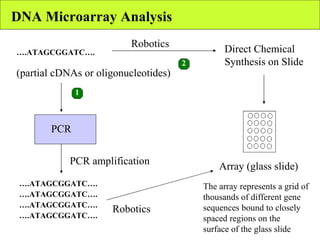
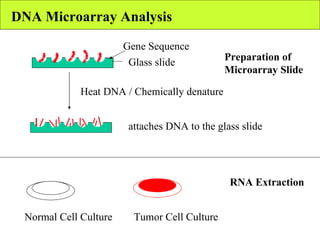
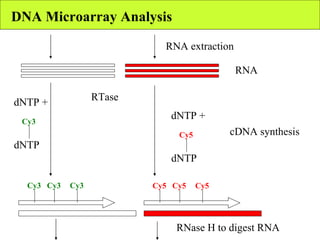
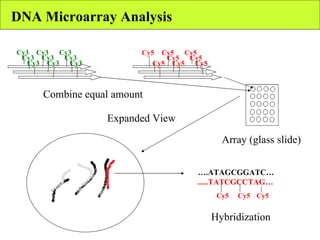
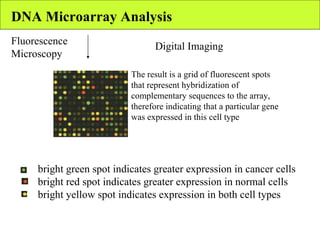
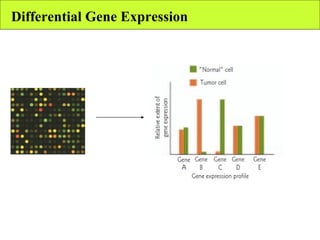
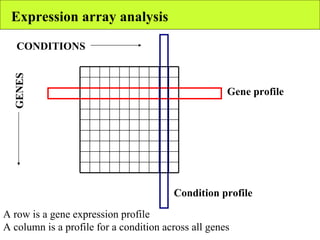





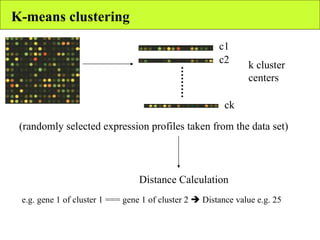

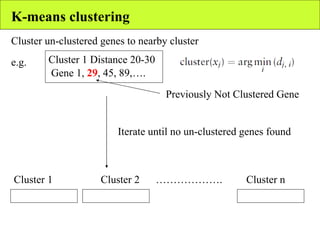
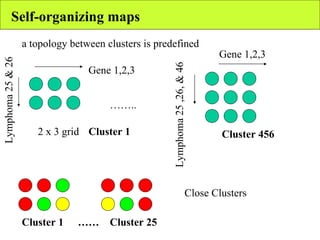
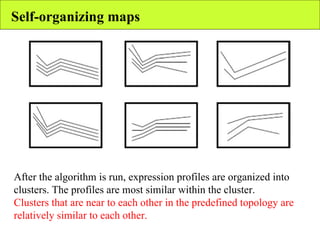
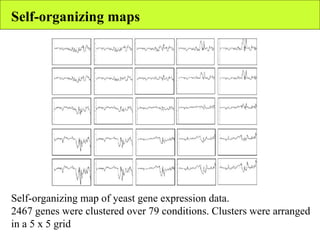
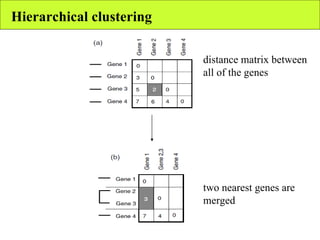
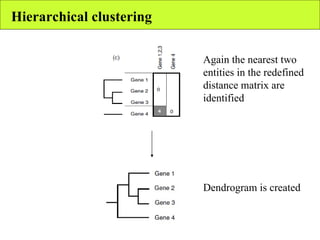
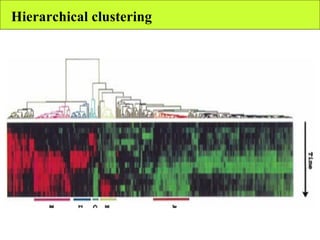


The document summarizes various unsupervised learning algorithms used for analyzing gene expression data from microarray experiments, including k-means clustering, self-organizing maps, and hierarchical clustering. It describes how these algorithms group genes based on similarity in their expression profiles across different conditions or cell types without external labels, helping to simplify data sets and identify genes that may be co-regulated or serve similar functions.



































































