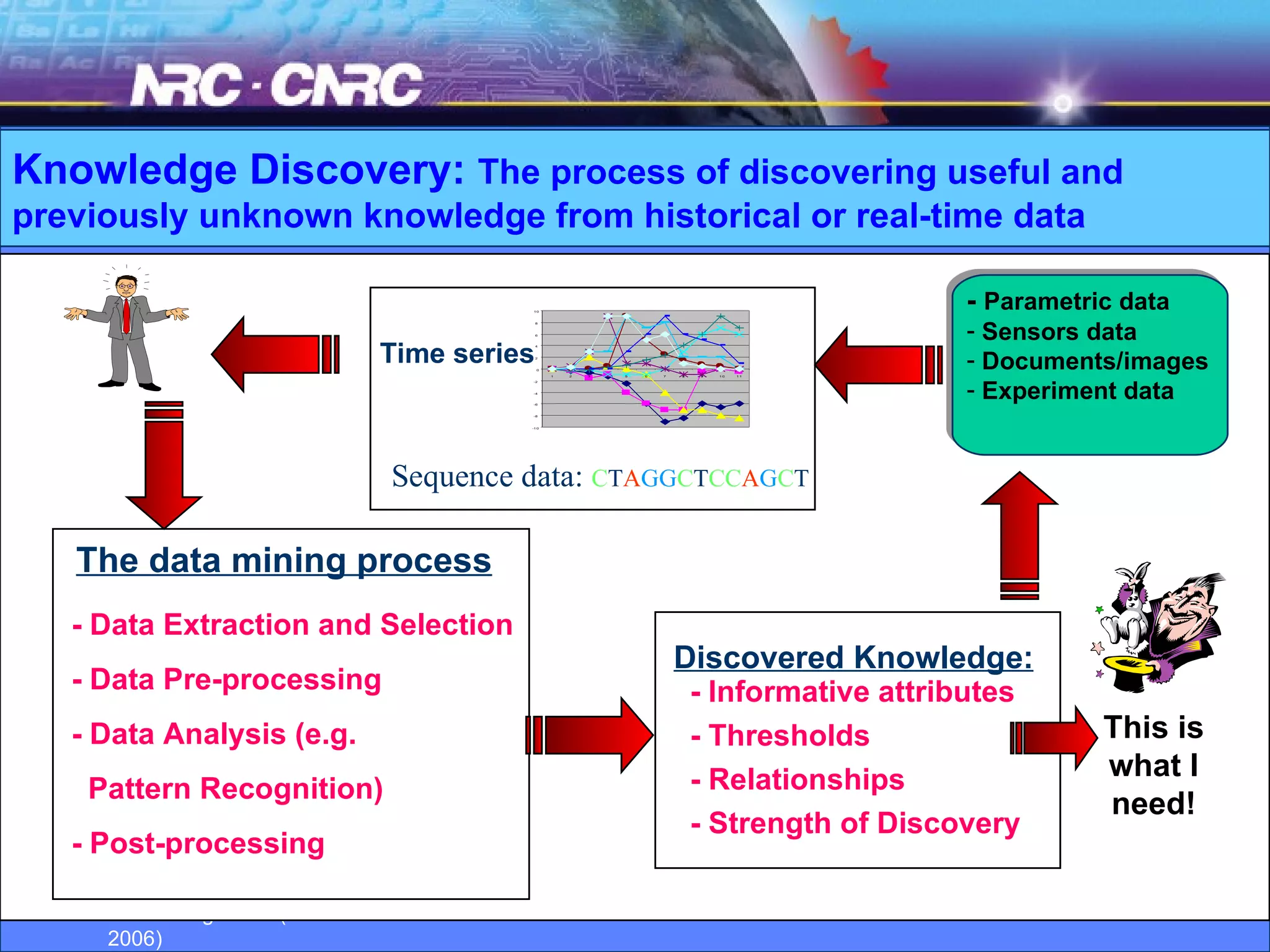
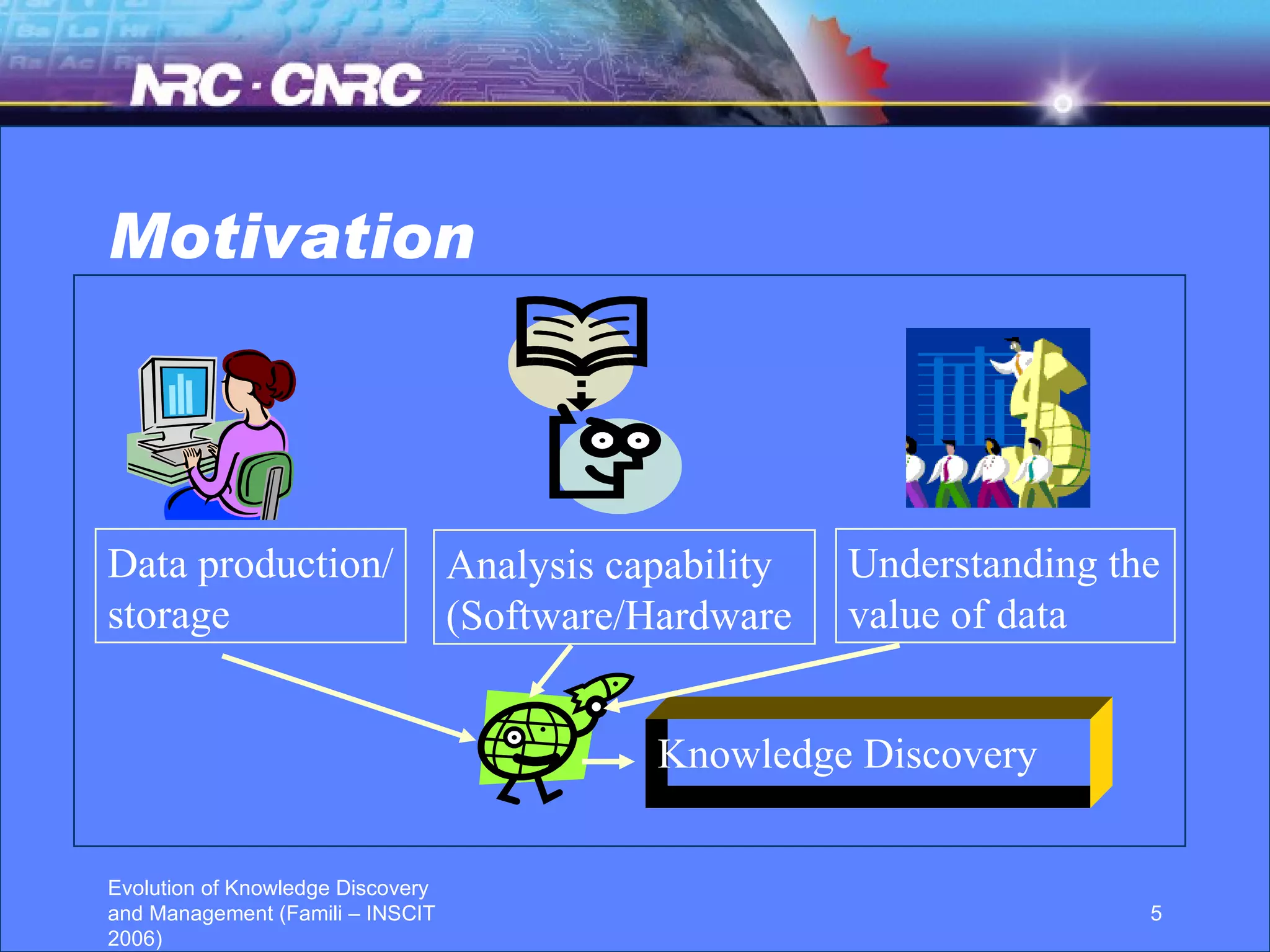
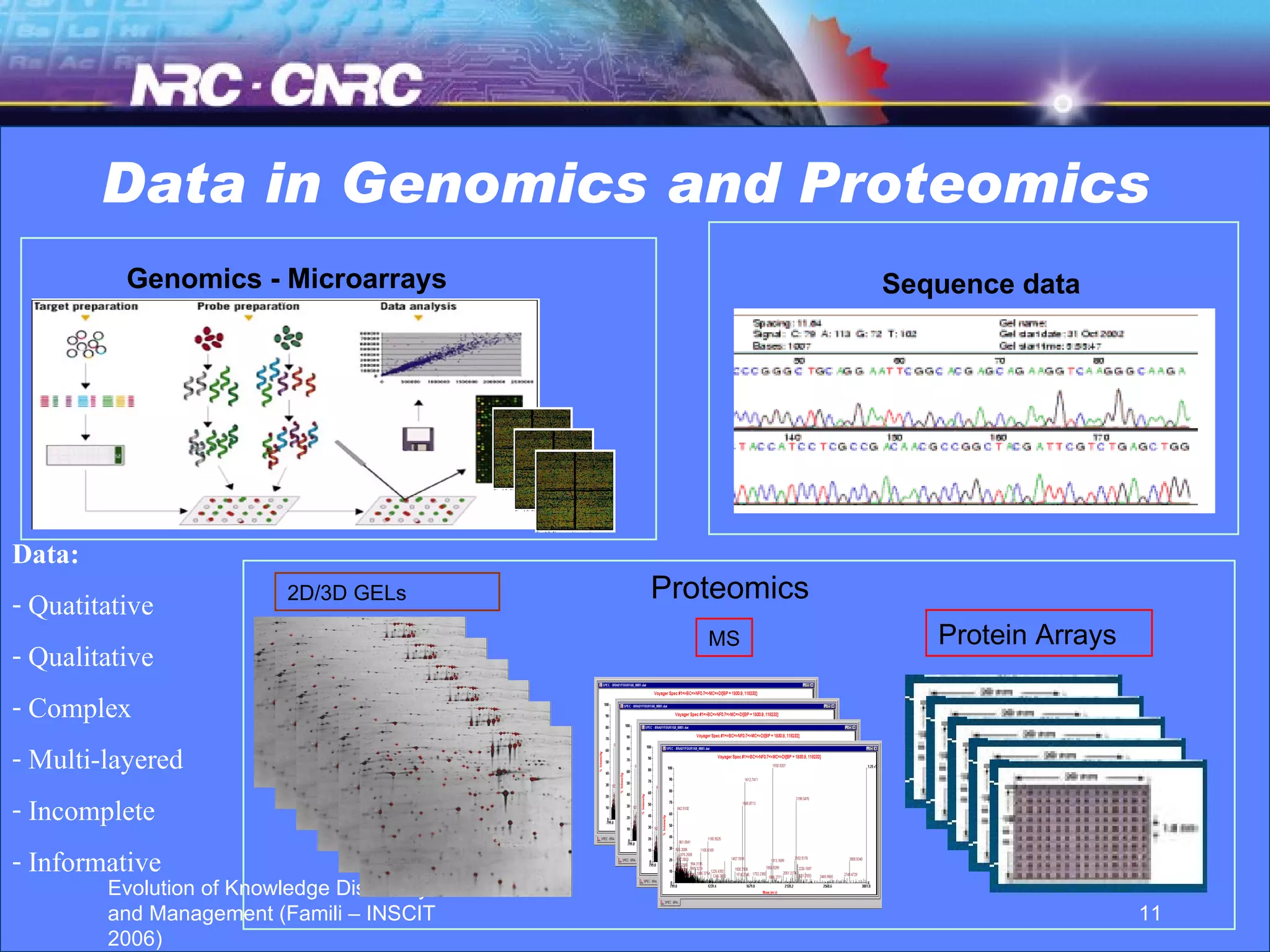
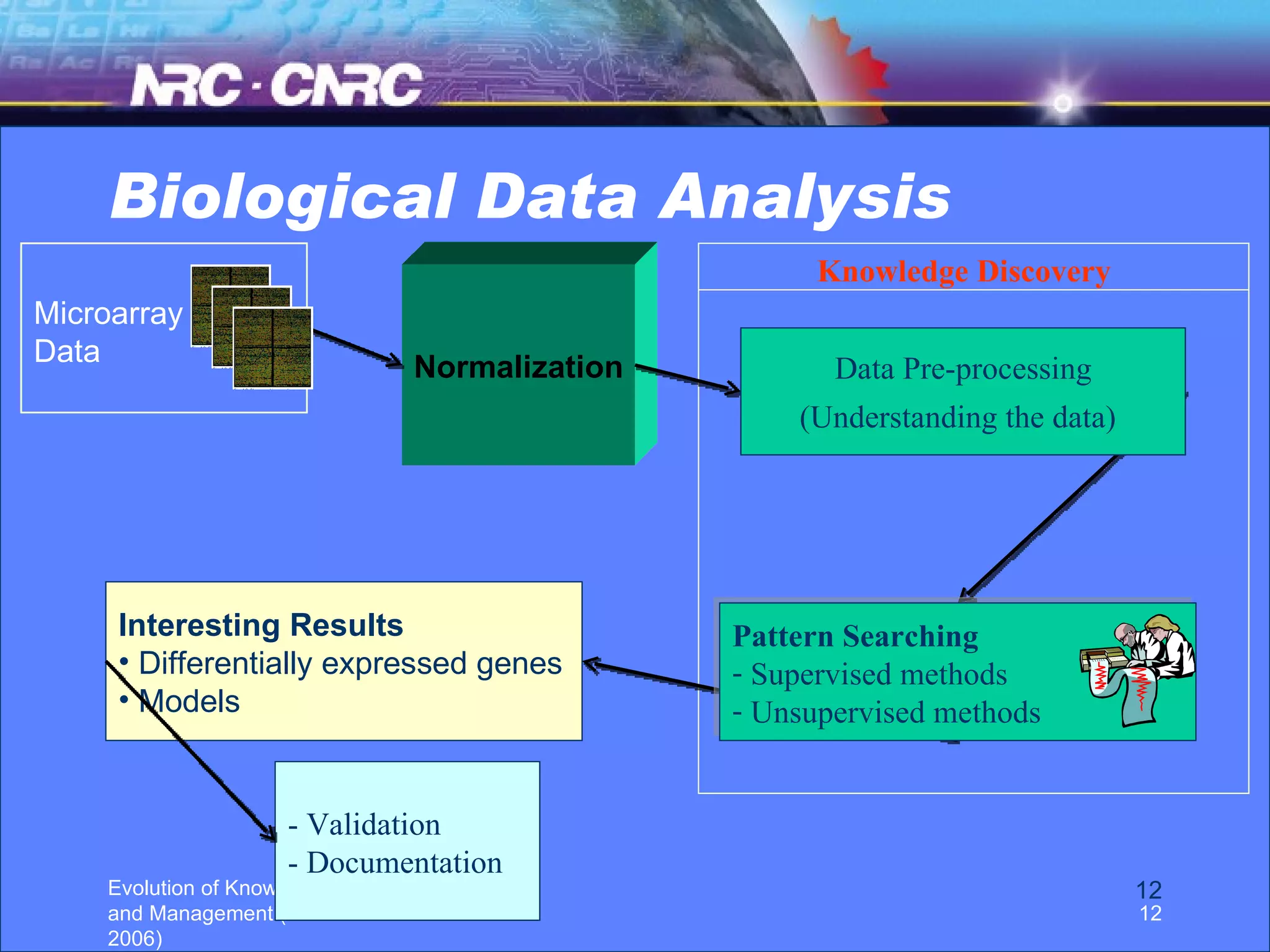
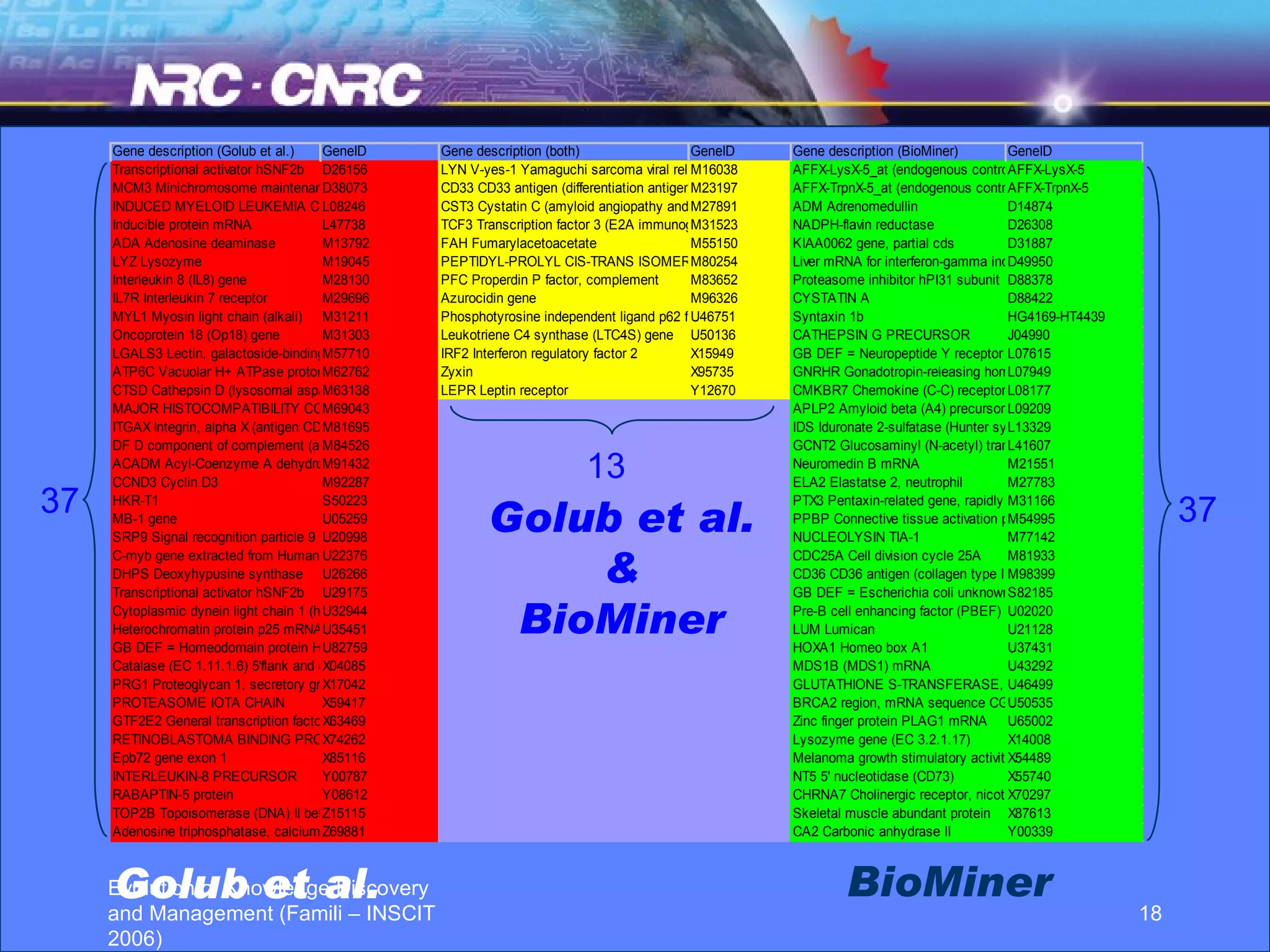
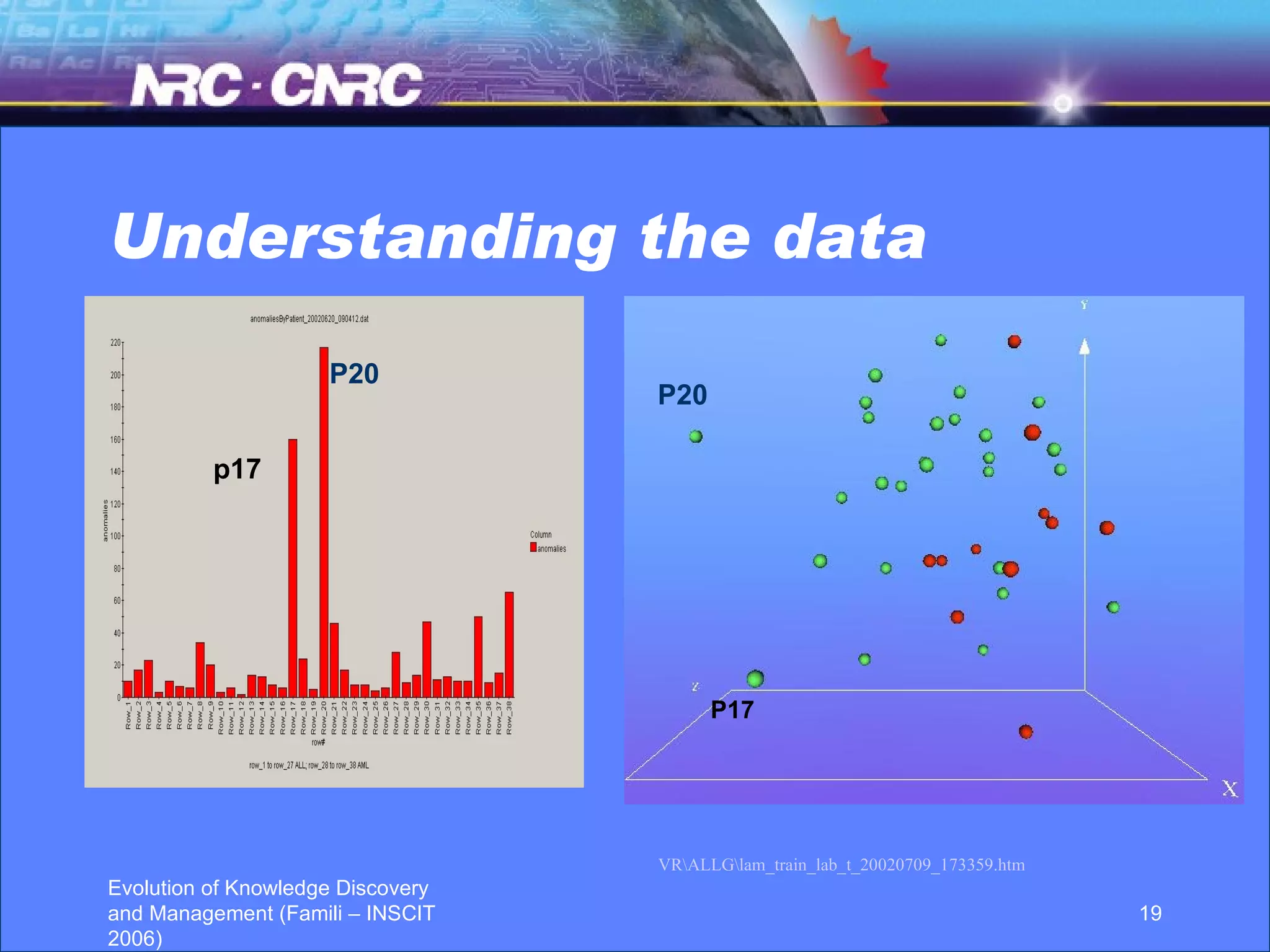
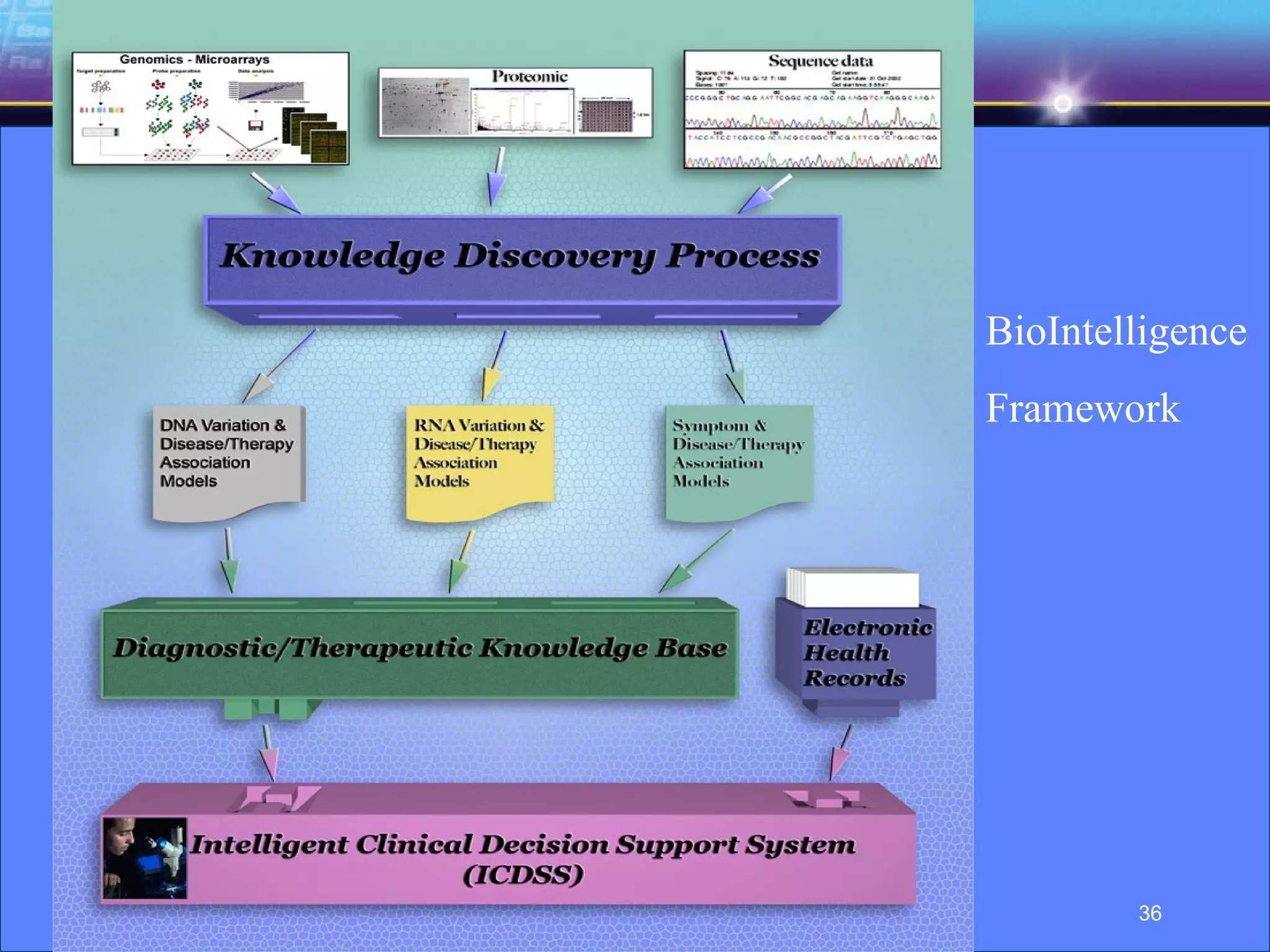
The document discusses the evolution of knowledge discovery and management over time. It outlines how knowledge discovery has progressed from early efforts using simulated data due to lack of large real-world datasets, to today where there is no shortage of complex real-world problems and data available. Key areas evolving now include automated data analysis, integration of tools and databases, and handling different data types like text and images. While expert systems showed early promise but had limited results, knowledge discovery has led to valuable applications through continued academic and industrial research.
![Evolution of Knowledge Discovery and Management Dr. A. Fazel Famili National Research Council of Canada Ottawa, ON K1A 0R6 Canada [email_address] October 28 th 2066](https://image.slidesharecdn.com/evolution-of-knowledge-discovery-and-management-12190/75/Evolution-of-Knowledge-Discovery-and-Management-1-2048.jpg)









































































































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)












![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)

