Downloaded 11 times







































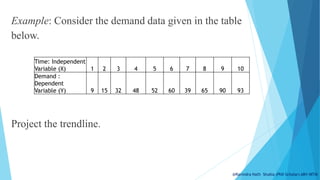


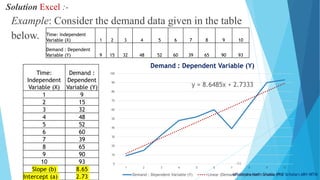










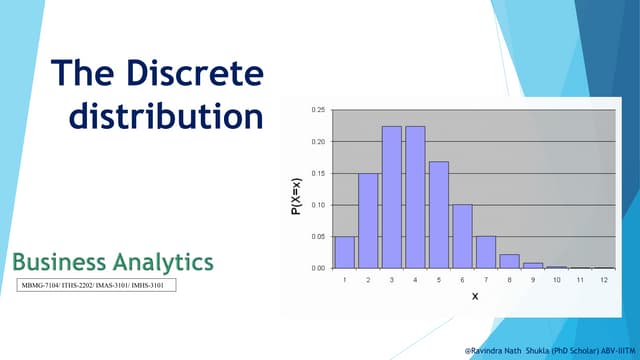
Managers require accurate forecasts to make good decisions. There are three main categories of forecasting approaches: qualitative and judgmental techniques which rely on experience; statistical time-series models which analyze historical data patterns; and explanatory/causal methods which consider factors influencing changes. Some common forecasting techniques include moving averages, exponential smoothing, and trend line analysis, with error metrics like mean absolute deviation used to evaluate accuracy.