Downloaded 55 times


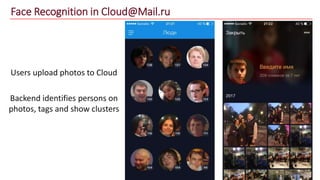


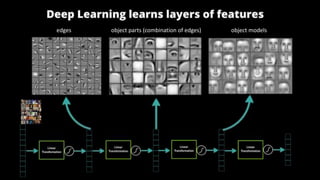


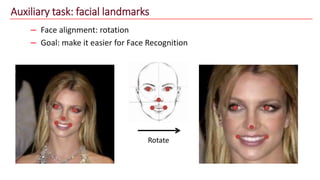


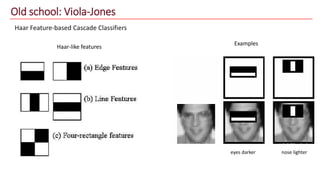
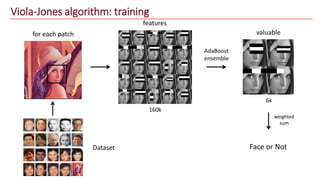
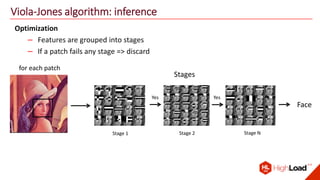
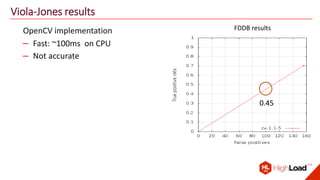
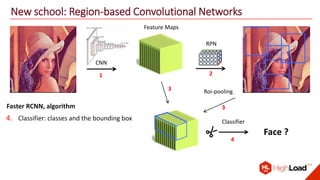
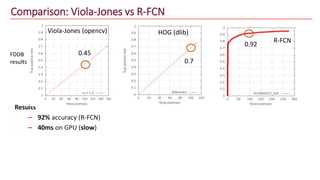

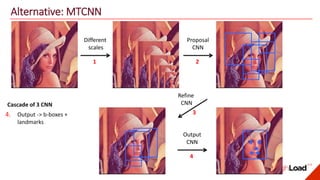



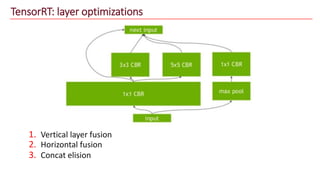



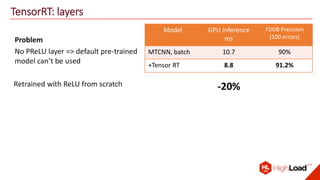


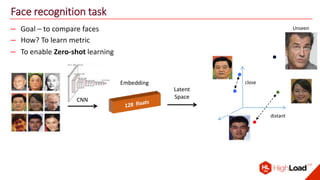


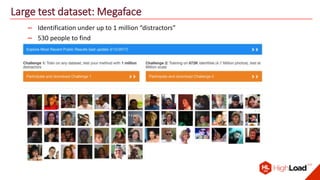
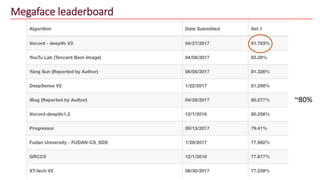

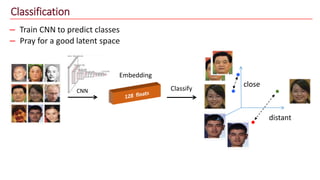

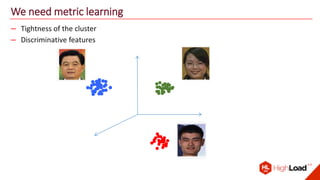



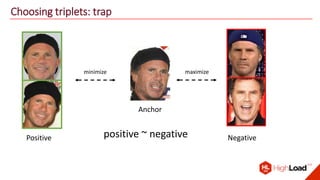
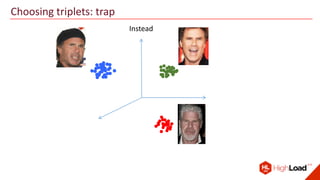

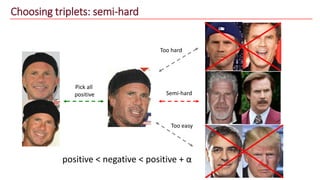

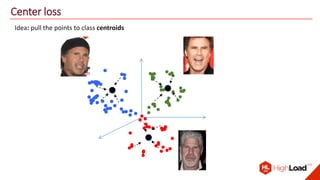
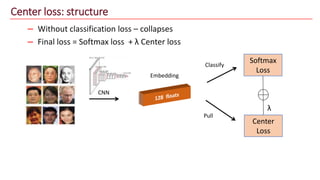
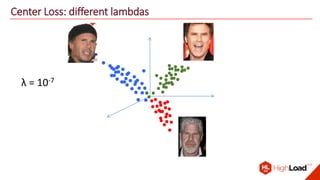
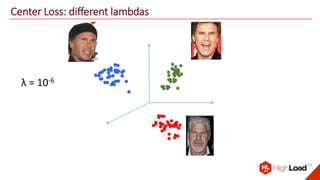
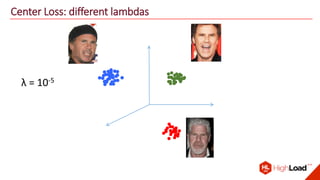

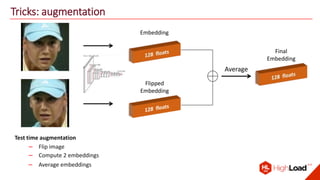
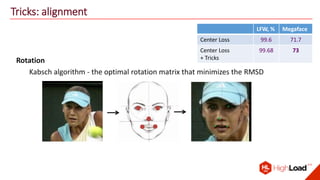

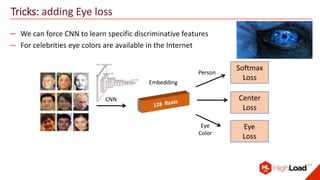

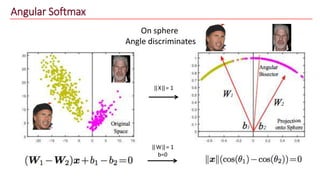
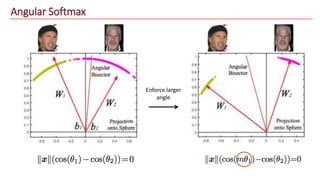
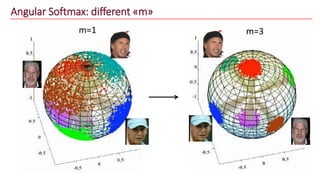






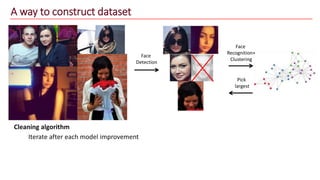





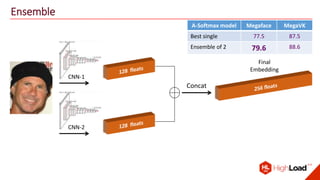

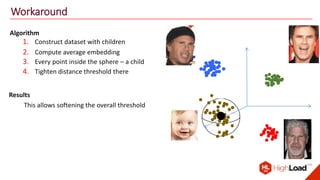


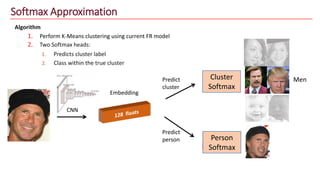




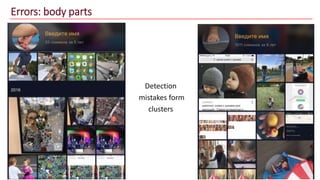
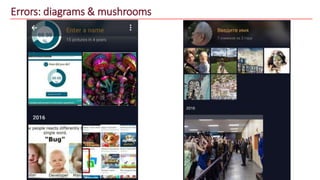
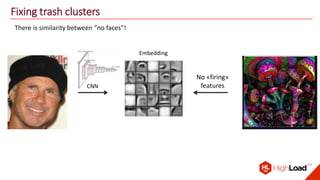


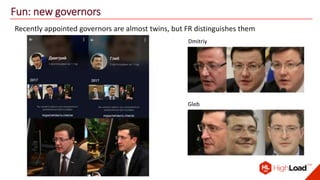
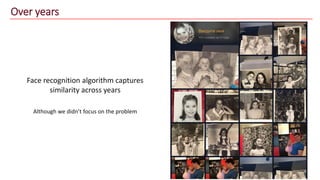






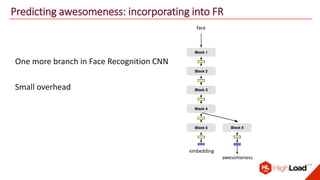

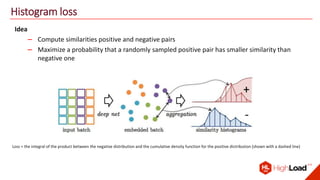

The document discusses advancements in face recognition technology, detailing methods such as the Viola-Jones algorithm and deep learning-based approaches like MTCNN and Faster R-CNN, highlighting their performance metrics. It emphasizes the importance of data quality and diversity for effective model training, particularly in overcoming biases in recognition accuracy. Furthermore, it introduces various techniques for optimizing inference speed and enhancing feature discriminability, such as TensorRT and metric learning with center loss.























































































