Download to read offline















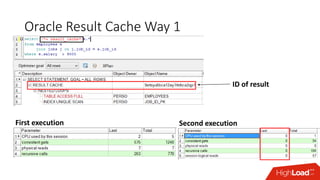






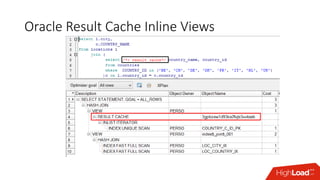
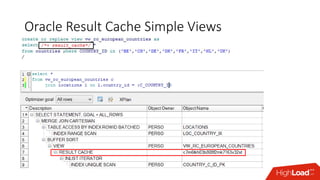

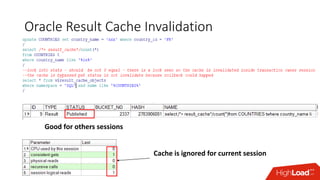
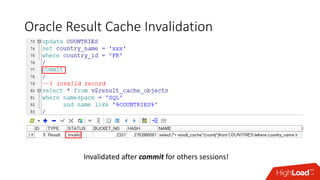











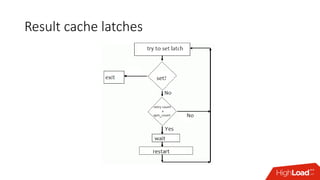





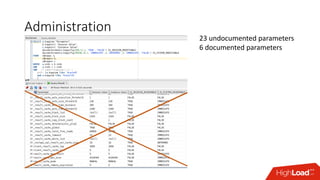








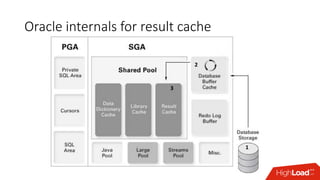







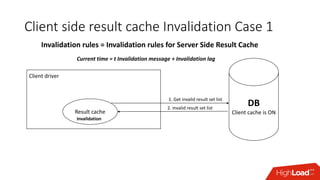












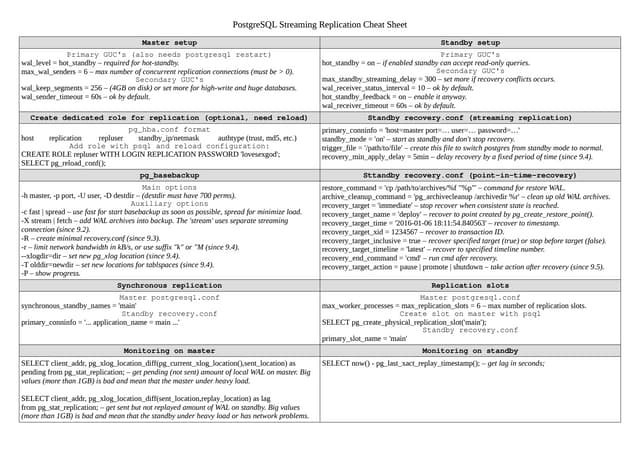
The document outlines strategies for caching in Oracle Database to enhance query performance while minimizing costs, categorizing various caching techniques such as buffer, statement, and result caches. It includes case studies demonstrating the effective use of hand-made result caches and Oracle's built-in result cache, along with their pros and cons, performance metrics, and recommendations for implementation. Furthermore, it provides insights on cache management, invalidation scenarios, and detailed monitoring features to optimize performance in production environments.